Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
SU
Uploaded by
Seiichi Uchida
PPTX, PDF
6,701 views
データサイエンス概論第一=3-2 主成分分析と因子分析
九州大学大学院システム情報科学研究院「データサイエンス実践特別講座」が贈る,数理・情報系『でない』学生さんのための「データサイエンス講義.
Data & Analytics
◦
Read more
9
Save
Share
Embed
Embed presentation
Download
Downloaded 260 times
1
/ 47
2
/ 47
3
/ 47
4
/ 47
5
/ 47
6
/ 47
7
/ 47
8
/ 47
9
/ 47
10
/ 47
11
/ 47
12
/ 47
13
/ 47
14
/ 47
15
/ 47
16
/ 47
17
/ 47
18
/ 47
19
/ 47
20
/ 47
21
/ 47
22
/ 47
23
/ 47
24
/ 47
25
/ 47
26
/ 47
27
/ 47
28
/ 47
29
/ 47
30
/ 47
31
/ 47
32
/ 47
33
/ 47
34
/ 47
35
/ 47
36
/ 47
37
/ 47
38
/ 47
39
/ 47
40
/ 47
41
/ 47
42
/ 47
43
/ 47
44
/ 47
45
/ 47
46
/ 47
47
/ 47
More Related Content
PPTX
データサイエンス概論第一=2-2 クラスタリング
by
Seiichi Uchida
PPTX
データサイエンス概論第一=2-1 データ間の距離と類似度
by
Seiichi Uchida
PPTX
データサイエンス概論第一 5 時系列データの解析
by
Seiichi Uchida
PPTX
データサイエンス概論第一=3-1 線形代数に基づくデータ解析の基礎
by
Seiichi Uchida
PPTX
データサイエンス概論第一 6 異常検出
by
Seiichi Uchida
PPTX
データサイエンス概論第一=3-3 回帰分析
by
Seiichi Uchida
PDF
決定木学習
by
Mitsuo Shimohata
PPTX
ベイズモデリングで見る因子分析
by
Shushi Namba
データサイエンス概論第一=2-2 クラスタリング
by
Seiichi Uchida
データサイエンス概論第一=2-1 データ間の距離と類似度
by
Seiichi Uchida
データサイエンス概論第一 5 時系列データの解析
by
Seiichi Uchida
データサイエンス概論第一=3-1 線形代数に基づくデータ解析の基礎
by
Seiichi Uchida
データサイエンス概論第一 6 異常検出
by
Seiichi Uchida
データサイエンス概論第一=3-3 回帰分析
by
Seiichi Uchida
決定木学習
by
Mitsuo Shimohata
ベイズモデリングで見る因子分析
by
Shushi Namba
What's hot
PDF
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PDF
階層ベイズによるワンToワンマーケティング入門
by
shima o
PPTX
データサイエンス概論第一=1-3 平均と分散
by
Seiichi Uchida
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PPTX
データサイエンス概論第一=1-2 データのベクトル表現と集合
by
Seiichi Uchida
PPTX
相関分析と回帰分析
by
大貴 末廣
PDF
データ解析7 主成分分析の基礎
by
Hirotaka Hachiya
PDF
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
多腕バンディット問題: 定式化と応用 (第13回ステアラボ人工知能セミナー)
by
STAIR Lab, Chiba Institute of Technology
PDF
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
PDF
ベイズ推定でパラメータリスクを捉える&優れたサンプラーとしてのMCMC
by
基晴 出井
PDF
pymcとpystanでベイズ推定してみた話
by
Classi.corp
PPTX
データサイエンス概論第一=1-1 データとは
by
Seiichi Uchida
PPT
100614 構造方程式モデリング基本の「き」
by
Shinohara Masahiro
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PDF
パターン認識 第10章 決定木
by
Miyoshi Yuya
PDF
MICの解説
by
logics-of-blue
PPTX
GEE(一般化推定方程式)の理論
by
Koichiro Gibo
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
不均衡データのクラス分類
by
Shintaro Fukushima
階層ベイズによるワンToワンマーケティング入門
by
shima o
データサイエンス概論第一=1-3 平均と分散
by
Seiichi Uchida
Stan超初心者入門
by
Hiroshi Shimizu
データサイエンス概論第一=1-2 データのベクトル表現と集合
by
Seiichi Uchida
相関分析と回帰分析
by
大貴 末廣
データ解析7 主成分分析の基礎
by
Hirotaka Hachiya
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
ベイズ統計学の概論的紹介
by
Naoki Hayashi
多腕バンディット問題: 定式化と応用 (第13回ステアラボ人工知能セミナー)
by
STAIR Lab, Chiba Institute of Technology
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
ベイズ推定でパラメータリスクを捉える&優れたサンプラーとしてのMCMC
by
基晴 出井
pymcとpystanでベイズ推定してみた話
by
Classi.corp
データサイエンス概論第一=1-1 データとは
by
Seiichi Uchida
100614 構造方程式モデリング基本の「き」
by
Shinohara Masahiro
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
パターン認識 第10章 決定木
by
Miyoshi Yuya
MICの解説
by
logics-of-blue
GEE(一般化推定方程式)の理論
by
Koichiro Gibo
Similar to データサイエンス概論第一=3-2 主成分分析と因子分析
PPTX
データサイエンス概論第一=0 まえがき
by
Seiichi Uchida
PDF
C05
by
anonymousouj
PPTX
主成分分析
by
Yasuhiro Kanno
PDF
データ解析8 主成分分析の応用
by
Hirotaka Hachiya
PPTX
データサイエンス概論第一=4-1 相関・頻度・ヒストグラム
by
Seiichi Uchida
PDF
Stat r 9_principal
by
fusion2011
PDF
機械学習と主成分分析
by
Katsuhiro Morishita
PDF
データ解析10 因子分析の基礎
by
Hirotaka Hachiya
PDF
主成分分析
by
貴之 八木
PDF
関数データ解析の概要とその方法
by
Hidetoshi Matsui
PPT
Gasshuku98
by
隆浩 安
PDF
パターン認識02 k平均法ver2.0
by
sleipnir002
PDF
因子分析
by
Mitsuo Shimohata
PDF
[Tokyor08] Rによるデータサイエンス 第2部 第3章 対応分析
by
Yohei Sato
PDF
カステラ本勉強会 第三回
by
ke beck
PDF
マトリックス・データ解析法(主成分分析)
by
博行 門眞
PDF
東京都市大学 データ解析入門 3 行列分解 2
by
hirokazutanaka
PDF
DS Exercise Course 6
by
大貴 末廣
PPTX
統計学の記法,回帰分析と最小二乗法
by
Masahito Ohue
PDF
TokyoWebmining統計学部 第1回
by
Issei Kurahashi
データサイエンス概論第一=0 まえがき
by
Seiichi Uchida
C05
by
anonymousouj
主成分分析
by
Yasuhiro Kanno
データ解析8 主成分分析の応用
by
Hirotaka Hachiya
データサイエンス概論第一=4-1 相関・頻度・ヒストグラム
by
Seiichi Uchida
Stat r 9_principal
by
fusion2011
機械学習と主成分分析
by
Katsuhiro Morishita
データ解析10 因子分析の基礎
by
Hirotaka Hachiya
主成分分析
by
貴之 八木
関数データ解析の概要とその方法
by
Hidetoshi Matsui
Gasshuku98
by
隆浩 安
パターン認識02 k平均法ver2.0
by
sleipnir002
因子分析
by
Mitsuo Shimohata
[Tokyor08] Rによるデータサイエンス 第2部 第3章 対応分析
by
Yohei Sato
カステラ本勉強会 第三回
by
ke beck
マトリックス・データ解析法(主成分分析)
by
博行 門眞
東京都市大学 データ解析入門 3 行列分解 2
by
hirokazutanaka
DS Exercise Course 6
by
大貴 末廣
統計学の記法,回帰分析と最小二乗法
by
Masahito Ohue
TokyoWebmining統計学部 第1回
by
Issei Kurahashi
More from Seiichi Uchida
PDF
1 データとデータ分析
by
Seiichi Uchida
PDF
9 可視化
by
Seiichi Uchida
PDF
13 分類とパターン認識
by
Seiichi Uchida
PDF
12 非構造化データ解析
by
Seiichi Uchida
PDF
0 データサイエンス概論まえがき
by
Seiichi Uchida
PDF
15 人工知能入門
by
Seiichi Uchida
PDF
14 データ収集とバイアス
by
Seiichi Uchida
PDF
10 確率と確率分布
by
Seiichi Uchida
PDF
8 予測と回帰分析
by
Seiichi Uchida
PDF
7 主成分分析
by
Seiichi Uchida
PDF
6 線形代数に基づくデータ解析の基礎
by
Seiichi Uchida
PDF
5 クラスタリングと異常検出
by
Seiichi Uchida
PDF
4 データ間の距離と類似度
by
Seiichi Uchida
PDF
3 平均・分散・相関
by
Seiichi Uchida
PDF
2 データのベクトル表現と集合
by
Seiichi Uchida
PDF
「あなたがいま読んでいるものは文字です」~画像情報学から見た文字研究のこれから
by
Seiichi Uchida
PDF
Machine learning for document analysis and understanding
by
Seiichi Uchida
PDF
データサイエンス概論第一=8 パターン認識と深層学習
by
Seiichi Uchida
PDF
データサイエンス概論第一=7 画像処理
by
Seiichi Uchida
PPTX
An opening talk at ICDAR2017 Future Workshop - Beyond 100%
by
Seiichi Uchida
1 データとデータ分析
by
Seiichi Uchida
9 可視化
by
Seiichi Uchida
13 分類とパターン認識
by
Seiichi Uchida
12 非構造化データ解析
by
Seiichi Uchida
0 データサイエンス概論まえがき
by
Seiichi Uchida
15 人工知能入門
by
Seiichi Uchida
14 データ収集とバイアス
by
Seiichi Uchida
10 確率と確率分布
by
Seiichi Uchida
8 予測と回帰分析
by
Seiichi Uchida
7 主成分分析
by
Seiichi Uchida
6 線形代数に基づくデータ解析の基礎
by
Seiichi Uchida
5 クラスタリングと異常検出
by
Seiichi Uchida
4 データ間の距離と類似度
by
Seiichi Uchida
3 平均・分散・相関
by
Seiichi Uchida
2 データのベクトル表現と集合
by
Seiichi Uchida
「あなたがいま読んでいるものは文字です」~画像情報学から見た文字研究のこれから
by
Seiichi Uchida
Machine learning for document analysis and understanding
by
Seiichi Uchida
データサイエンス概論第一=8 パターン認識と深層学習
by
Seiichi Uchida
データサイエンス概論第一=7 画像処理
by
Seiichi Uchida
An opening talk at ICDAR2017 Future Workshop - Beyond 100%
by
Seiichi Uchida
データサイエンス概論第一=3-2 主成分分析と因子分析
1.
1 九州大学大学院システム情報科学研究院 データサイエンス実践特別講座 データサイエンス概論第一 第3回 主成分分析と回帰分析: 3-2 主成分分析と因子分析 システム情報科学研究院情報知能工学部門 内田誠一
2.
2 データサイエンス概論第一の内容 データとは データのベクトル表現と集合
平均と分散 データ間の距離 データ間の類似度 データのクラスタリング (グルーピング) 線形代数に基づくデータ解析の基礎 主成分分析と因子分析 回帰分析 相関・頻度・ヒストグラム 確率と確率分布 信頼区間と統計的検定 時系列データの解析 異常検出
3.
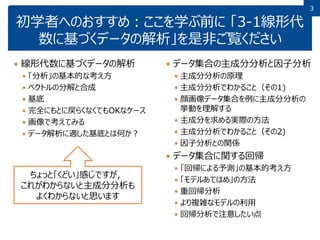
3 初学者へのおすすめ:ここを学ぶ前に 「3-1線形代 数に基づくデータの解析」を是非ご覧ください 線形代数に基づくデータの解析
「分析」の基本的な考え方 ベクトルの分解と合成 基底 完全にもとに戻らくなくてもOKなケース 画像で考えてみる データ解析に適した基底とは何か? データ集合の主成分分析と因子分析 主成分分析の原理 主成分分析でわかること(その1) 顔画像データ集合を例に主成分分析の 挙動を理解する 主成分を求める実際の方法 主成分分析でわかること(その2) 因子分析との関係 データ集合に関する回帰 「回帰による予測」の基本的考え方 「モデルあてはめ」の方法 重回帰分析 より複雑なモデルの利用 回帰分析で注意したい点 ちょっと「くどい」感じですが, これがわからないと主成分分析も よくわからないと思います
4.
4 データ集合の主成分分析 主成分分析の原理 主成分分析でわかること(その1) 顔画像データ集合を例に主成分分析の挙動を理解する 主成分を求める実際の方法 主成分分析でわかること(その2) 因子分析との関係
5.
5 データ集合の主成分分析① 主成分分析の原理 普通の基底:任意の𝑑次元ベクトルを表すための,𝑑個の𝑑次元ベクトル 主成分分析で求まる基底:特定の𝑑次元ベクトル集合を表すための, 𝑑(< 𝑑)個の𝑑次元ベクトル
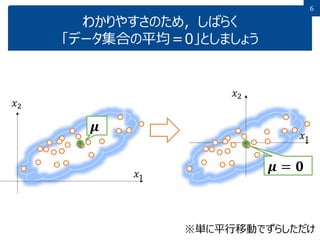
6.
6 わかりやすさのため,しばらく 「データ集合の平均=0」としましょう 𝑥1 𝑥2 𝝁 𝑥1 𝑥2 𝝁 = 𝟎 ※単に平行移動でずらしただけ
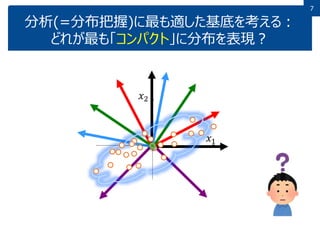
7.
7 分析(=分布把握)に最も適した基底を考える: どれが最も「コンパクト」に分布を表現? 7 𝑥1 𝑥2
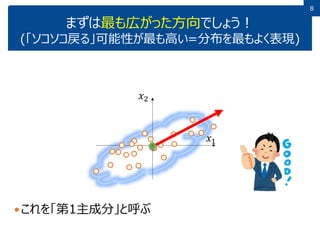
8.
88 まずは最も広がった方向でしょう! (「ソコソコ戻る」可能性が最も高い=分布を最もよく表現) これを「第1主成分」と呼ぶ 𝑥1 𝑥2
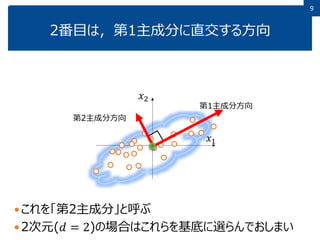
9.
99 これを「第2主成分」と呼ぶ 2次元(𝑑 = 2)の場合はこれらを基底に選らんでおしまい 2番目は,第1主成分に直交する方向 𝑥1 𝑥2 第1主成分方向 第2主成分方向
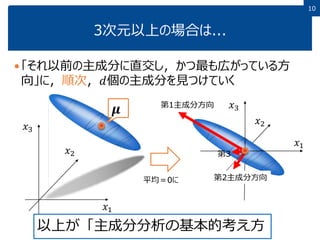
10.
1010 3次元以上の場合は... 「それ以前の主成分に直交し,かつ最も広がっている方 向」に,順次,𝑑個の主成分を見つけていく 𝑥1 𝑥2 𝑥3 𝝁 𝑥1 𝑥2 𝑥3 平均=0に 第1主成分方向 第2主成分方向 以上が「主成分分析の基本的考え方 第3
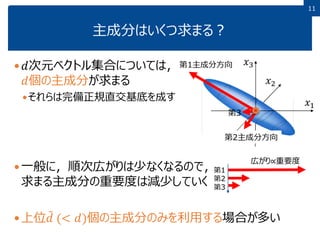
11.
1111 主成分はいくつ求まる? 𝑑次元ベクトル集合については, 𝑑個の主成分が求まる それらは完備正規直交基底を成す 一般に,順次広がりは少なくなるので, 求まる主成分の重要度は減少していく 上位 𝑑
(< 𝑑)個の主成分のみを利用する場合が多い 𝑥1 𝑥2 𝑥3第1主成分方向 第2主成分方向 第1 第2 第3 広がり∝重要度 第3
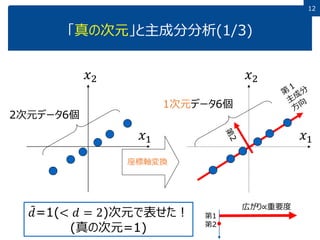
12.
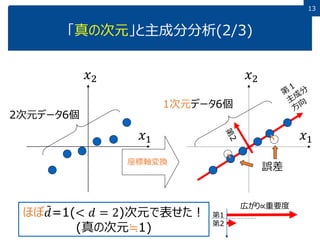
12 「真の次元」と主成分分析(1/3) 2次元データ6個 座標軸変換 𝑥1 𝑥2 𝑥1 𝑥2 1次元データ6個 𝑑=1(< 𝑑 =
2)次元で表せた! (真の次元=1) 第1 第2 広がり∝重要度
13.
13 「真の次元」と主成分分析(2/3) 2次元データ6個 誤差 座標軸変換 ほぼ 𝑑=1(< 𝑑
= 2)次元で表せた! (真の次元≒1) 𝑥1 𝑥2 𝑥1 𝑥2 第1 第2 広がり∝重要度 1次元データ6個
14.
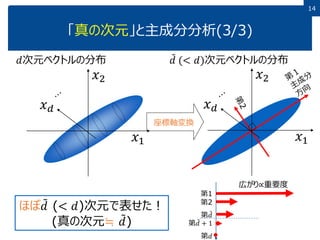
14 「真の次元」と主成分分析(3/3) 座標軸変換 𝑑次元ベクトルの分布 𝑑 (<
𝑑)次元ベクトルの分布 ほぼ 𝑑 (< 𝑑)次元で表せた! (真の次元≒ 𝑑) 第1 第2 第 𝑑 第 𝑑 + 1 第𝑑 広がり∝重要度 𝑥1 𝑥2 𝑥 𝑑 𝑥1 𝑥2 𝑥 𝑑
15.
15 データ集合の主成分分析② 主成分分析でわかること(その1) どうしてこんな大変な思いをしなくてはならないのか?
16.
1616 主成分方向=分布の主要な広がり方向 高々 𝑑(< 𝑑)個の主成分で,
𝑑次元ベクトル分布全体を コンパクトに表現 この意味で,クラスタリングの代表ベクトルにも似ている 時には 𝑑 ≪ 𝑑 やろうと思えばいくらでも 𝑑は小さくできる ただし,やりすぎると分布の構造をうまく捉えられないことに 主成分方向=平均からの主要な変動と捉えることも可能
17.
1717 各主成分の重要度 (後々は「累積寄与率」とか「固有値」と呼びます) 大きく広がっている→重要度高い 第1, 第2, 第3...と,重要度は下がる ただし,下がり方は様々.そしてそれが非常に重要! 慣れてくると,この「下がり方カーブ」で分布の形状が想像できる 第1,
第2, 第3,…, 第 𝑑, 第 𝑑 + 1,…,第𝑑 重要度
18.
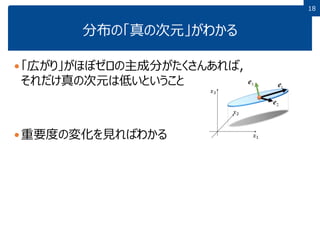
1818 分布の「真の次元」がわかる 「広がり」がほぼゼロの主成分がたくさんあれば, それだけ真の次元は低いということ 重要度の変化を見ればわかる
19.
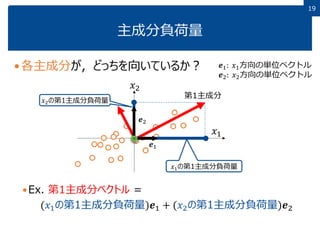
1919 主成分負荷量 各主成分が,どっちを向いているか? Ex. 第1主成分ベクトル = (𝑥1の第1主成分負荷量)𝒆1
+ (𝑥2の第1主成分負荷量)𝒆2 𝒆1: 𝑥1方向の単位ベクトル 𝒆2: 𝑥2方向の単位ベクトル 𝑥1 𝑥2 第1主成分 𝑥1の第1主成分負荷量 𝑥2の第1主成分負荷量 𝒆1 𝒆2
20.
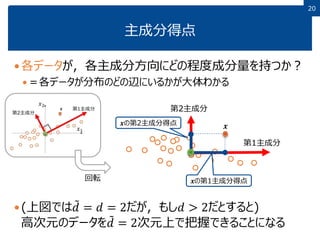
2020 主成分得点 各データが,各主成分方向にどの程度成分量を持つか? =各データが分布のどの辺にいるかが大体わかる (上図では 𝑑 =
𝑑 = 2だが,もし𝑑 > 2だとすると) 高次元のデータを 𝑑 = 2次元上で把握できることになる 第1主成分 第2主成分 𝒙 𝒙の第1主成分得点 𝒙の第2主成分得点 回転
21.
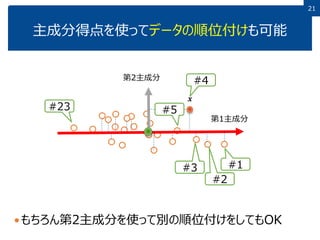
2121 主成分得点を使ってデータの順位付けも可能 もちろん第2主成分を使って別の順位付けをしてもOK 第1主成分 第2主成分 𝒙 #1 #2 #3 #4 #5#23
22.
22 データ集合の主成分分析③ 顔画像データ集合を例に 主成分分析の挙動を理解する 画像もベクトルなので主成分分析可能
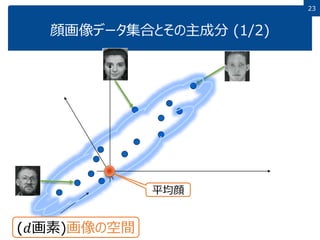
23.
23 顔画像データ集合とその主成分 (1/2) (𝑑画素)画像の空間 平均顔
24.
24 顔画像データ集合とその主成分 (2/2) 第1主成分 (分散最大方向) 第2主成分 (𝑑画素)画像の空間 平均顔
25.
25 顔画像に対する主成分分析 データ集合 (一部) 得られた主成分 (上位のみ)
26.
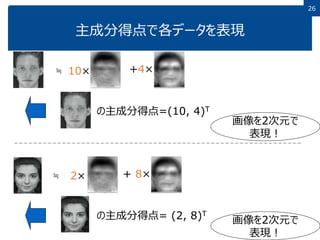
2626 主成分得点で各データを表現 ≒ 10× +4× の主成分得点=(10,
4)T ≒ 2× + 8× の主成分得点= (2, 8)T 画像を2次元で 表現! 画像を2次元で 表現!
27.
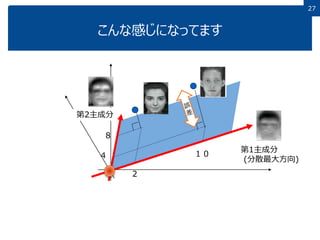
27 こんな感じになってます 第1主成分 (分散最大方向) 第2主成分 104 2 8
28.
2828 主成分を増やせば「誤差」を減らせます ≒ 10× +4×
-2× +5× の主成分得点=(10, 4, -2, 5) T ≒ 2× + 8× -11× -8× の主成分得点= (2, 8, -11, -8)T 画像を4次元で表現!
29.
29 データ集合の主成分分析④ 主成分を求める実際の方法 詳細略
30.
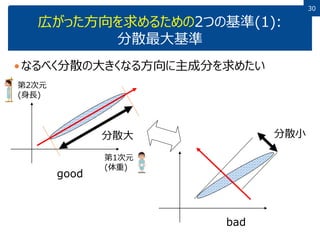
3030 広がった方向を求めるための2つの基準(1): 分散最大基準 なるべく分散の大きくなる方向に主成分を求めたい 分散大 分散小 good bad 第1次元 (体重) 第2次元 (身長)
31.
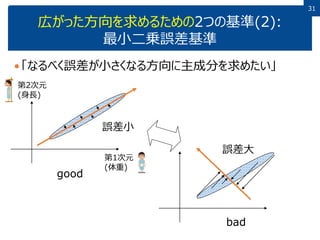
3131 広がった方向を求めるための2つの基準(2): 最小二乗誤差基準 「なるべく誤差が小さくなる方向に主成分を求めたい」 誤差小 誤差大 good bad 第1次元 (体重) 第2次元 (身長)
32.
3232 参考:主成分分析の解法 分散・最小誤差,どちらの基準でも,次のように解ける まったく同じ主成分が求まる 以下の3ステップで終了 1. データ集合(各々𝑑次元ベクトル)から共分散行列 Σ
を求める 2. Σの固有値と固有ベクトルを求める 3. 固有値の大きなものから 𝑑個の固有ベクトルを主成分と する( 𝑑は適当に決定) そのうちやります
33.
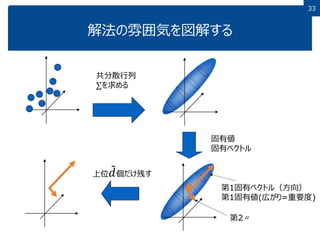
33 解法の雰囲気を図解する 共分散行列 ∑を求める 固有値 固有ベクトル 第1固有ベクトル(方向) 第1固有値(広がり=重要度) 第2〃 上位 𝑑個だけ残す
34.
34 データ集合の主成分分析⑤ 主成分分析でわかること(その2) 慣れてくるといろいろわかってきます
35.
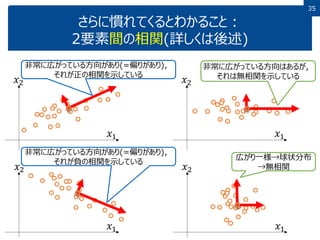
35 さらに慣れてくるとわかること: 2要素間の相関(詳しくは後述) 𝑥1 𝑥2 非常に広がっている方向があり(=偏りがあり), それが正の相関を示している 𝑥1 𝑥2 非常に広がっている方向はあるが, それは無相関を示している 𝑥1 𝑥2 広がり一様→球状分布 →無相関 𝑥1 𝑥2 非常に広がっている方向があり(=偏りがあり), それが負の相関を示している
36.
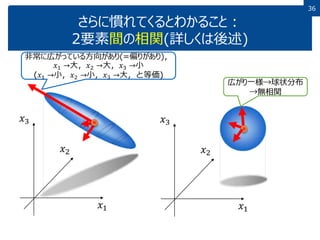
36 さらに慣れてくるとわかること: 2要素間の相関(詳しくは後述) 𝑥1 𝑥2 𝑥3 𝑥1 𝑥2 𝑥3 非常に広がっている方向があり(=偏りがあり), 𝑥1 →大,𝑥2 →大,𝑥3
→小 (𝑥1 →小,𝑥2 →小,𝑥3 →大,と等価) 広がり一様→球状分布 →無相関
37.
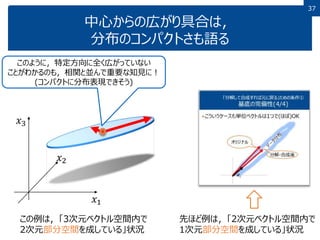
37 中心からの広がり具合は, 分布のコンパクトさも語る 𝑥1 𝑥2 𝑥3 この例は,「3次元ベクトル空間内で 2次元部分空間を成している」状況 先ほど例は,「2次元ベクトル空間内で 1次元部分空間を成している」状況 このように,特定方向に全く広がっていない ことがわかるのも,相関と並んで重要な知見に! (コンパクトに分布表現できそう)
38.
38 データ集合の主成分分析⑥ 因子分析との関係 似て非なるもの
39.
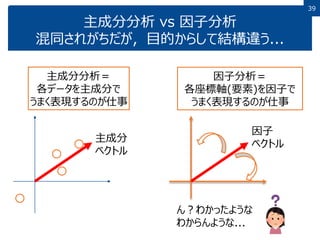
39 主成分分析 vs 因子分析 混同されがちだが,目的からして結構違う... 主成分分析= 各データを主成分で うまく表現するのが仕事 因子分析= 各座標軸(要素)を因子で うまく表現するのが仕事 主成分 ベクトル 因子 ベクトル ん?わかったような わからんような...
40.
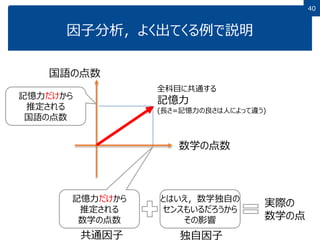
40 因子分析,よく出てくる例で説明 全科目に共通する 記憶力 (長さ=記憶力の良さは人によって違う) 数学の点数 記憶力だけから 推定される 数学の点数 記憶力だけから 推定される 国語の点数 とはいえ,数学独自の センスもいるだろうから その影響 実際の 数学の点 共通因子 独自因子 国語の点数
41.
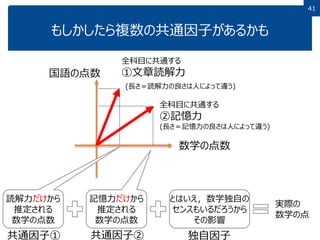
41 もしかしたら複数の共通因子があるかも 全科目に共通する ②記憶力 (長さ=記憶力の良さは人によって違う) 数学の点数 国語の点数 記憶力だけから 推定される 数学の点数 とはいえ,数学独自の センスもいるだろうから その影響 実際の 数学の点 共通因子② 独自因子 全科目に共通する ①文章読解力 (長さ=読解力の良さは人によって違う) 読解力だけから 推定される 数学の点数 共通因子①
42.
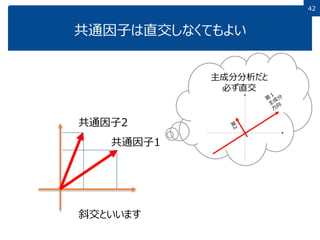
42 共通因子は直交しなくてもよい 42 共通因子1 主成分分析だと 必ず直交 斜交といいます 共通因子2
43.
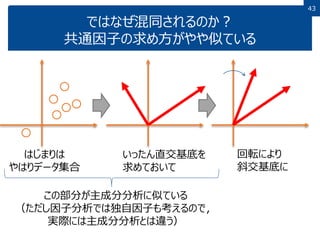
43 ではなぜ混同されるのか? 共通因子の求め方がやや似ている 43 いったん直交基底を 求めておいて 回転により 斜交基底に はじまりは やはりデータ集合 この部分が主成分分析に似ている (ただし因子分析では独自因子も考えるので, 実際には主成分分析とは違う)
44.
4444 参考:より違いを深く知りたい方へ http://www.sigmath.es.osaka-u.ac.jp/~kano/research/seminar/30BSJ/kano.pdf
45.
45 データ集合の主成分分析⑦ 分布状況の解析手段について, これまでのまとめ
46.
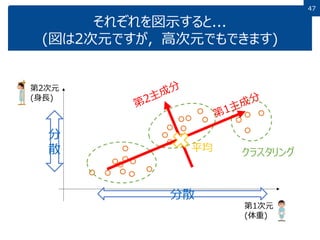
4646 色々な方法で分布状況を解析してきました 平均 分布の中心 (各軸の)分散 各要素(各座標軸)での広がり具合 クラスタリング 分布全体をグループに分ける 主成分 分布が最も広がっている方向=第一主成分 第一主成分に直交しつつ,次に最も広がっている部分=第二 分布の「真の次元」もわかる どれがいいとか 悪いとかではない. みんな違って みんないい.
47.
47 それぞれを図示すると... (図は2次元ですが,高次元でもできます) 第1次元 (体重) 第2次元 (身長) 分散 分 散 クラスタリング平均
Download