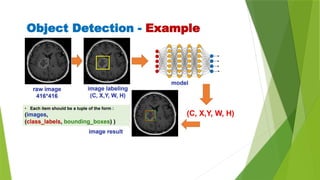
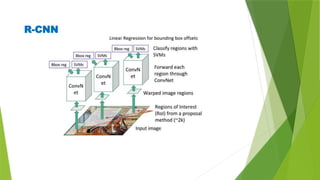
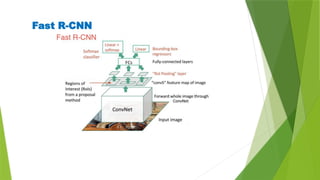
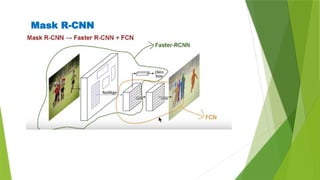
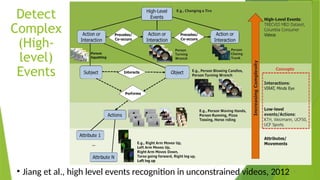
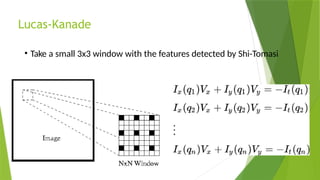
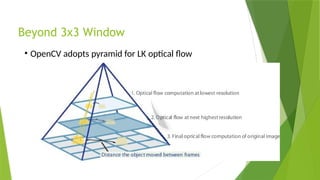
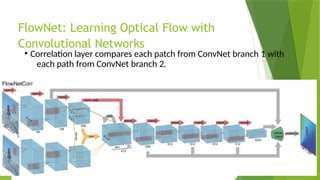
The document outlines the development of an automated video analysis system for construction sites, aiming to analyze video footage and generate detailed reports on activities, safety compliance, and incidents. It specifies objectives such as customizing machine learning models, integrating object and action data, and creating human-readable reports while addressing challenges like data quality and computational resources. Expected outcomes include enhanced monitoring, improved safety, and operational efficiency through proactive management and automated reporting.
































































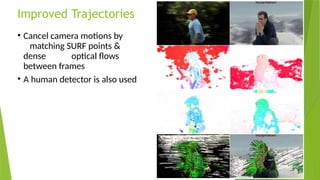
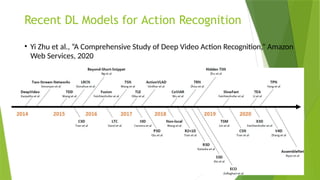
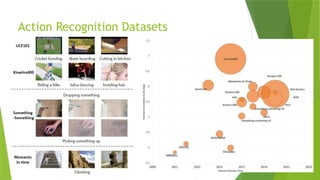


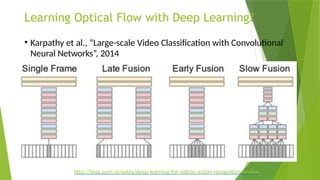
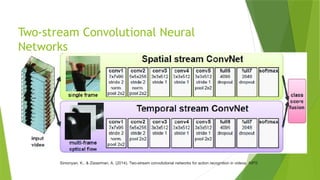
![State-of-the-Arts
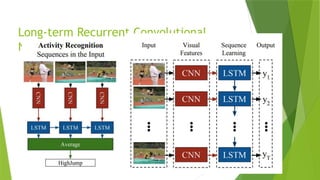
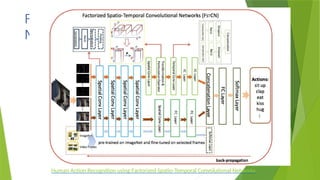
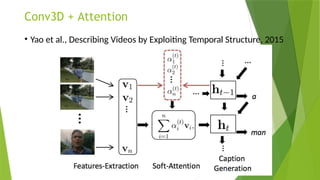
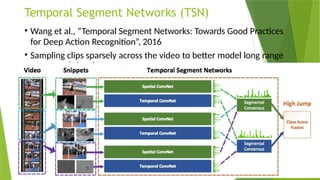
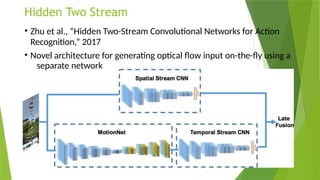
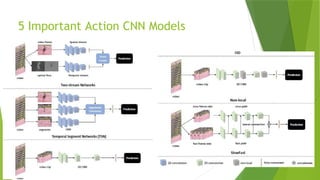
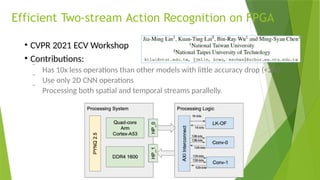
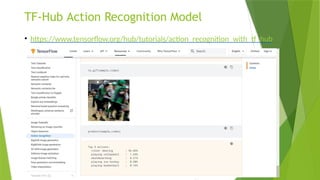
• LRCN [15], C3D [16], Conv3D & Attention [17], TwoStreamFusion [18],
TSN [19], ActionVlad [20], HiddenTwoStream [1] I3D [21] and T3D
[22]
http://blog.qure.ai/notes/deep-learning-for-videos-action-recognition-review](https://image.slidesharecdn.com/pre-241107071050-99565d68/85/Automated-Video-Analysis-and-Reporting-for-Construction-Sites-79-320.jpg)