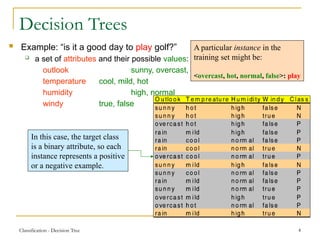
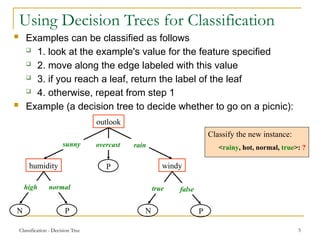
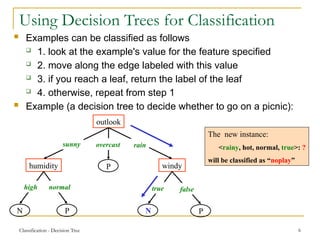
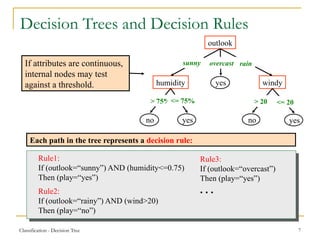
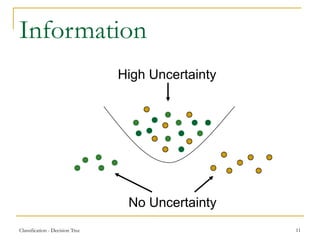
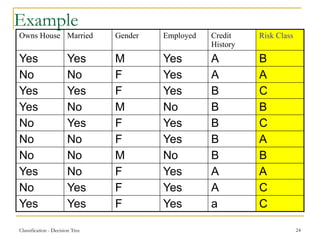
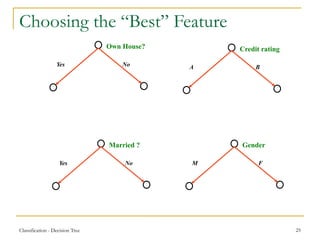
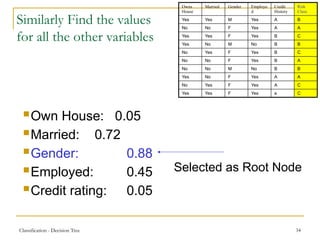
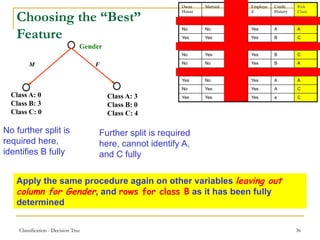
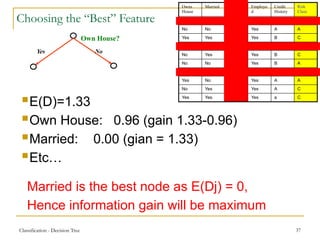
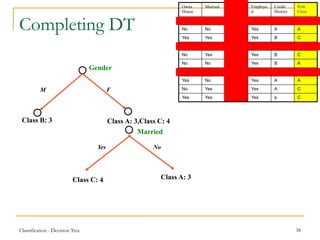
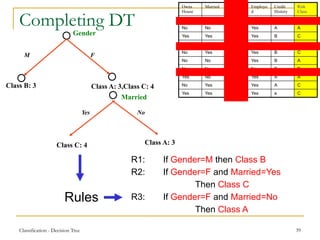
This document discusses decision tree learning, a widely used technique for classification due to its competitive accuracy and efficiency. It explains the structure of decision trees, the process of tree construction and pruning, and how to calculate entropy and information gain to select the best features for classification tasks. Additionally, it illustrates these concepts with examples and mathematical formulations.