Downloaded 17 times













![@doanduyhai
Collections
23
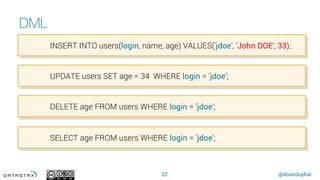
CREATE TABLE xxx(
…,
li list<text>,
se set<text>,
ma map<int, text>,
…
);
UPDATE xxx SET li = li + [append] …
UPDATE xxx SET se = se + {append}
UPDATE xxx SET ma[key] = value …](https://image.slidesharecdn.com/apachecassandraen2016-160914071622/85/Apache-cassandra-in-2016-23-320.jpg)



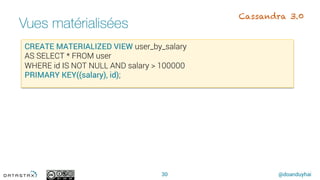

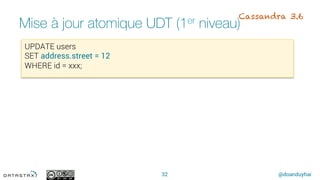







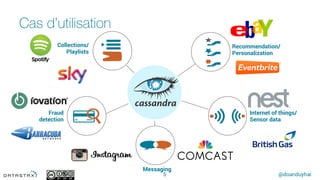
This document discusses Apache Cassandra and its features and use cases. It provides an overview of Cassandra's key characteristics like massive scalability, extreme availability, and rich data modeling. Example use cases mentioned include messaging, collections/playlists, fraud detection, recommendations, and IoT sensor data. New features introduced in Cassandra in 2016 are also summarized, such as delete by range, materialized views, atomic UDT updates, a new SASI index, and support for GROUP BY queries.


























































































