Download as PDF, PPTX






![@doanduyhai
Spark code example!
Setup
Data-set (can be from text, CSV, JSON, Cassandra, HDFS, …)
val$conf$=$new$SparkConf(true)$
$ .setAppName("basic_example")$
$ .setMaster("local[3]")$
$
val$sc$=$new$SparkContext(conf)$
val$people$=$List(("jdoe","John$DOE",$33),$
$$$$$$$$$$$$$$$$$$("hsue","Helen$SUE",$24),$
$$$$$$$$$$$$$$$$$$("rsmith",$"Richard$Smith",$33))$
7](https://image.slidesharecdn.com/real-timedataprocessingwithsparkcassandranosqlmatters2015paris-150327155326-conversion-gate01/85/Real-time-data-processing-with-spark-cassandra-NoSQLMatters-2015-Paris-7-320.jpg)
![@doanduyhai
RDDs!
RDD = Resilient Distributed Dataset
val$parallelPeople:$RDD[(String,$String,$Int)]$=$sc.parallelize(people)$
$
val$extractAge:$RDD[(Int,$(String,$String,$Int))]$=$parallelPeople$
$ $ $ $ $ $ .map(tuple$=>$(tuple._3,$tuple))$
$
val$groupByAge:$RDD[(Int,$Iterable[(String,$String,$Int)])]=extractAge.groupByKey()$
$
val$countByAge:$Map[Int,$Long]$=$groupByAge.countByKey()$
8](https://image.slidesharecdn.com/real-timedataprocessingwithsparkcassandranosqlmatters2015paris-150327155326-conversion-gate01/85/Real-time-data-processing-with-spark-cassandra-NoSQLMatters-2015-Paris-8-320.jpg)
![@doanduyhai
RDDs!
RDD[A] = distributed collection of A
• RDD[Person]
• RDD[(String,Int)], …
RDD[A] split into partitions
Partitions distributed over n workers à parallel computing
9](https://image.slidesharecdn.com/real-timedataprocessingwithsparkcassandranosqlmatters2015paris-150327155326-conversion-gate01/85/Real-time-data-processing-with-spark-cassandra-NoSQLMatters-2015-Paris-9-320.jpg)

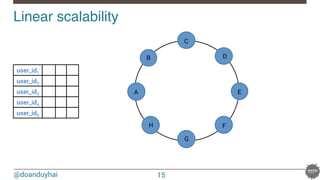
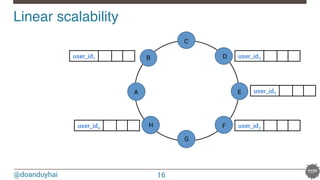
![@doanduyhai
Cassandra data distribution reminder!
Random: hash of #partition → token = hash(#p)
Hash: ]-X, X]
X = huge number (264/2)
n1
n2
n3
n4
n5
n6
n7
n8
13](https://image.slidesharecdn.com/real-timedataprocessingwithsparkcassandranosqlmatters2015paris-150327155326-conversion-gate01/85/Real-time-data-processing-with-spark-cassandra-NoSQLMatters-2015-Paris-13-320.jpg)
![@doanduyhai
Cassandra token ranges!
A: ]0, X/8]
B: ] X/8, 2X/8]
C: ] 2X/8, 3X/8]
D: ] 3X/8, 4X/8]
E: ] 4X/8, 5X/8]
F: ] 5X/8, 6X/8]
G: ] 6X/8, 7X/8]
H: ] 7X/8, X]
Murmur3 hash function
n1
n2
n3
n4
n5
n6
n7
n8
A
B
C
D
E
F
G
H
14](https://image.slidesharecdn.com/real-timedataprocessingwithsparkcassandranosqlmatters2015paris-150327155326-conversion-gate01/85/Real-time-data-processing-with-spark-cassandra-NoSQLMatters-2015-Paris-14-320.jpg)








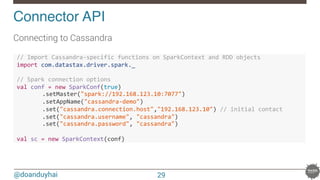

![@doanduyhai
Connector API!
Reading from Cassandra
!//!Use!table!as!RDD!
!val!rdd!=!sc.cassandraTable("test",!"words")!
!//!rdd:!CassandraRDD[CassandraRow]!=!CassandraRDD[0]!
!
!rdd.toArray.foreach(println)!
!//!CassandraRow[word:!bar,!count:!30]!
!//!CassandraRow[word:!foo,!count:!20]!
!
!rdd.columnNames!!!!//!Stream(word,!count)!
!rdd.size!!!!!!!!!!!//!2!
!
!val!firstRow!=!rdd.first!!//firstRow:CassandraRow=CassandraRow[word:!bar,!count:!30]!
!
!firstRow.getInt("count")!!//!Int!=!30!
31](https://image.slidesharecdn.com/real-timedataprocessingwithsparkcassandranosqlmatters2015paris-150327155326-conversion-gate01/85/Real-time-data-processing-with-spark-cassandra-NoSQLMatters-2015-Paris-31-320.jpg)
![@doanduyhai
Connector API!
Writing data to Cassandra
!val!newRdd!=!sc.parallelize(Seq(("cat",!40),!("fox",!50)))!!
!//!newRdd:!org.apache.spark.rdd.RDD[(String,!Int)]!=!ParallelCollectionRDD[2]!!!
!
!newRdd.saveToCassandra("test",!"words",!Seq("word",!"count"))!
SELECT&*&FROM&test.words;&
&
&&&&word&|&count&&&
&&&999999+9999999&
&&&&&bar&|&&&&30&
&&&&&foo&|&&&&20&
&&&&&cat&|&&&&40&
&&&&&fox&|&&&&50&&
32](https://image.slidesharecdn.com/real-timedataprocessingwithsparkcassandranosqlmatters2015paris-150327155326-conversion-gate01/85/Real-time-data-processing-with-spark-cassandra-NoSQLMatters-2015-Paris-32-320.jpg)
![@doanduyhai
Remember token ranges ?!
A: ]0, X/8]
B: ] X/8, 2X/8]
C: ] 2X/8, 3X/8]
D: ] 3X/8, 4X/8]
E: ] 4X/8, 5X/8]
F: ] 5X/8, 6X/8]
G: ] 6X/8, 7X/8]
H: ] 7X/8, X]
n1
n2
n3
n4
n5
n6
n7
n8
A
B
C
D
E
F
G
H
33](https://image.slidesharecdn.com/real-timedataprocessingwithsparkcassandranosqlmatters2015paris-150327155326-conversion-gate01/85/Real-time-data-processing-with-spark-cassandra-NoSQLMatters-2015-Paris-33-320.jpg)
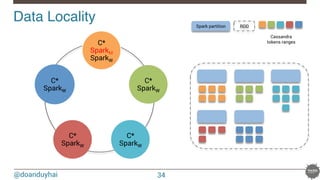
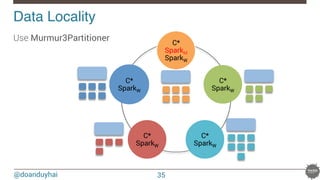
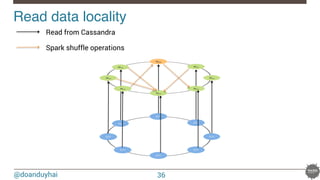
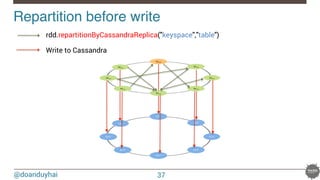
![@doanduyhai
Joins with data locality!
40
CREATE TABLE artists(name text, style text, … PRIMARY KEY(name));
CREATE TABLE albums(title text, artist text, year int,… PRIMARY KEY(title));
val join: CassandraJoinRDD[(String,Int), (String,String)] =
sc.cassandraTable[(String,Int)](KEYSPACE, ALBUMS)
// Select only useful columns for join and processing
.select("artist","year")
.as((_:String, _:Int))
// Repartition RDDs by "artists" PK, which is "name"
.repartitionByCassandraReplica(KEYSPACE, ARTISTS)
// Join with "artists" table, selecting only "name" and "country" columns
.joinWithCassandraTable[(String,String)](KEYSPACE, ARTISTS, SomeColumns("name","country"))
.on(SomeColumns("name"))](https://image.slidesharecdn.com/real-timedataprocessingwithsparkcassandranosqlmatters2015paris-150327155326-conversion-gate01/85/Real-time-data-processing-with-spark-cassandra-NoSQLMatters-2015-Paris-40-320.jpg)
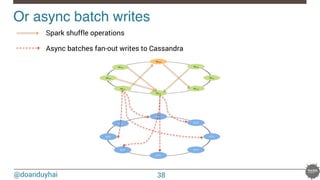
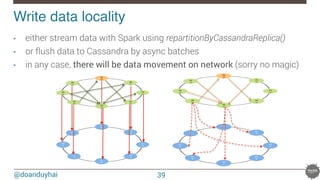
![@doanduyhai
Joins pipeline with data locality!
41
val join: CassandraJoinRDD[(String,Int), (String,String)] =
sc.cassandraTable[(String,Int)](KEYSPACE, ALBUMS)
// Select only useful columns for join and processing
.select("artist","year")
.as((_:String, _:Int))
.repartitionByCassandraReplica(KEYSPACE, ARTISTS)
.joinWithCassandraTable[(String,String)](KEYSPACE, ARTISTS, SomeColumns("name","country"))
.on(SomeColumns("name"))
.map(…)
.filter(…)
.groupByKey()
.mapValues(…)
.repartitionByCassandraReplica(KEYSPACE, ARTISTS_RATINGS)
.joinWithCassandraTable(KEYSPACE, ARTISTS_RATINGS)
…
!
!](https://image.slidesharecdn.com/real-timedataprocessingwithsparkcassandranosqlmatters2015paris-150327155326-conversion-gate01/85/Real-time-data-processing-with-spark-cassandra-NoSQLMatters-2015-Paris-41-320.jpg)



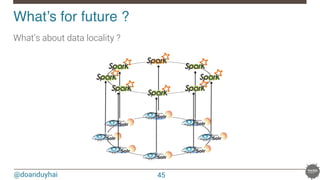
![@doanduyhai
val join: CassandraJoinRDD[(String,Int), (String,String)] =
sc.cassandraTable[(String,Int)](KEYSPACE, ALBUMS)
// Select only useful columns for join and processing
.select("artist","year").where("solr_query = 'style:*rock* AND ratings:[3 TO *]' ")
.as((_:String, _:Int))
.repartitionByCassandraReplica(KEYSPACE, ARTISTS)
.joinWithCassandraTable[(String,String)](KEYSPACE, ARTISTS, SomeColumns("name","country"))
.on(SomeColumns("name")).where("solr_query = 'age:[20 TO 30]' ")
What’s for future ?!
1. compute Spark partitions using Cassandra token ranges
2. on each partition, use Solr for local data filtering (no fan out !)
3. fetch data back into Spark for aggregations
4. repeat 1 – 3 as many times as necessary
46](https://image.slidesharecdn.com/real-timedataprocessingwithsparkcassandranosqlmatters2015paris-150327155326-conversion-gate01/85/Real-time-data-processing-with-spark-cassandra-NoSQLMatters-2015-Paris-46-320.jpg)
![@doanduyhai
What’s for future ?!
47
SELECT … FROM …
WHERE token(#partition)> 3X/8
AND token(#partition)<= 4X/8
AND solr_query='full text search expression';
1
2
3
Advantages of same JVM Cassandra + Solr integration
1
Single-pass local full text search (no fan out) 2
Data retrieval
D: ] 3X/8, 4X/8]](https://image.slidesharecdn.com/real-timedataprocessingwithsparkcassandranosqlmatters2015paris-150327155326-conversion-gate01/85/Real-time-data-processing-with-spark-cassandra-NoSQLMatters-2015-Paris-47-320.jpg)



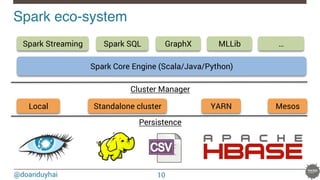
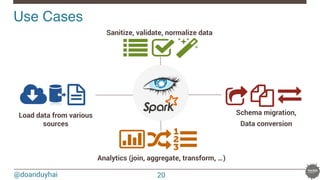
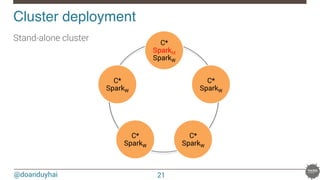
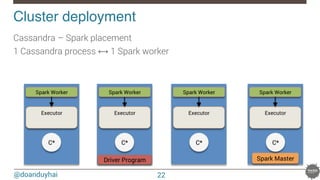
This document provides an overview of Spark and its integration with Cassandra for real-time data processing. It begins with introductions of the speaker and Datastax. It then discusses what Spark and Cassandra are, including their architectures and key characteristics like Spark being fast, easy to use, and supporting multiple languages. The document demonstrates basic Spark code and how RDDs work. It covers the Spark and Cassandra connectors and how they provide locality-aware joins. It also discusses use cases and deployment options. Finally, it considers future improvements like leveraging Solr for local filtering to improve data locality during joins.




































































































