Download as PDF, PPTX









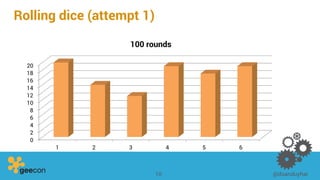
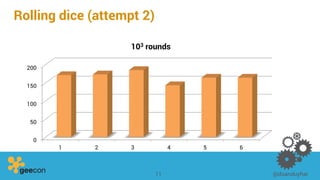
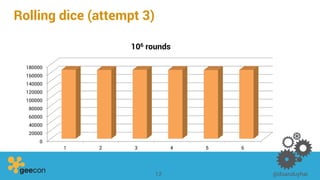













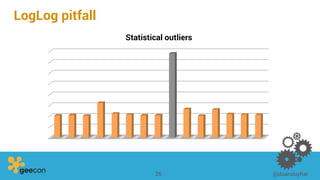

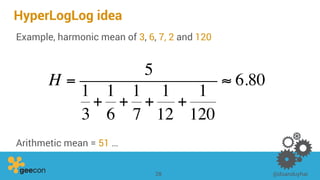
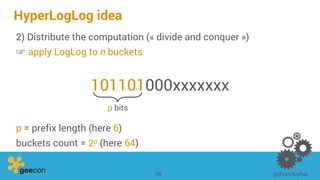


















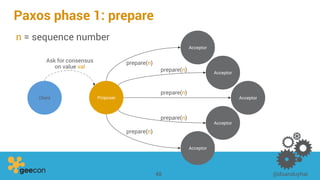
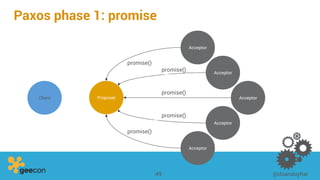
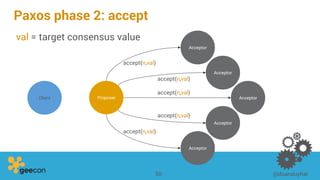
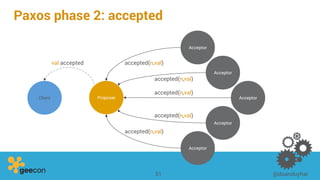
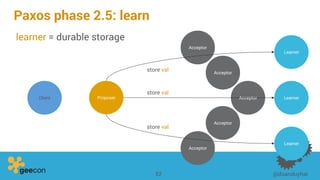



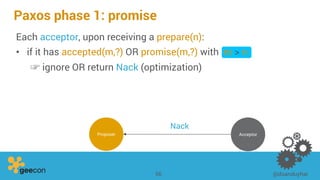
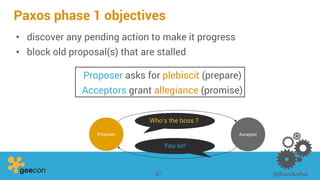

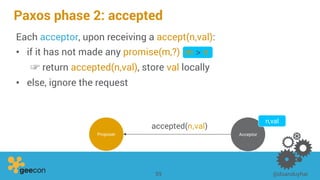

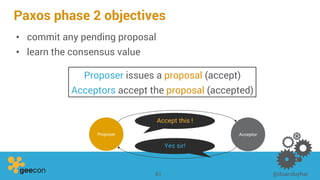

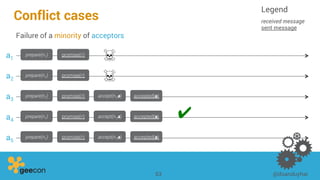
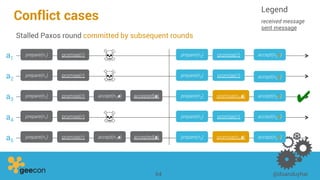
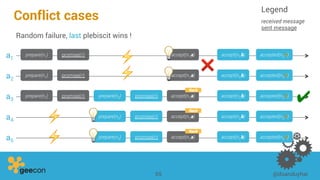
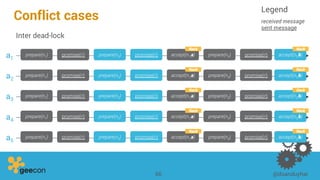
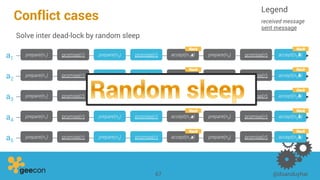






This document discusses distributed algorithms for big data. It begins with an overview of HyperLogLog for estimating cardinality and counting distinct elements in a large data set. It then explains how HyperLogLog works by using a hash function to distribute the data across buckets and applying the LogLog algorithm to each bucket before taking the harmonic mean. The document also covers Paxos for distributed consensus, explaining the phases of prepare, promise, accept and learn to reach agreement in the presence of failures.























































































