


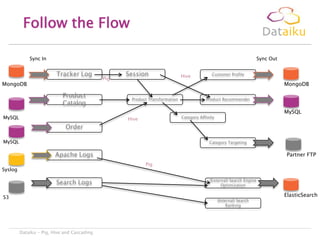
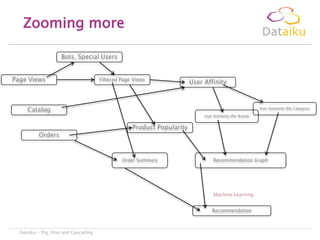





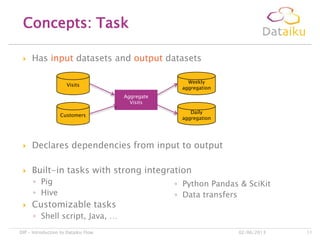
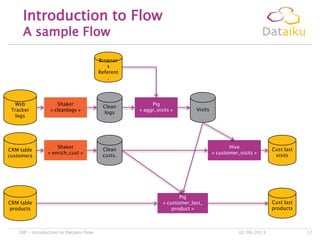

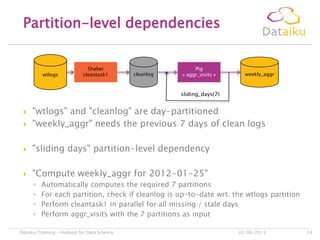



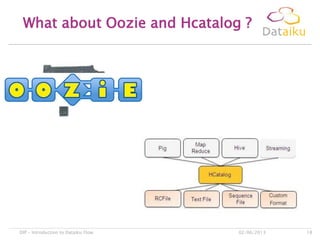









This document discusses Dataiku Flow and DCTC. Dataiku Flow is a data-driven orchestration framework for complex data pipelines that manages data dependencies and parallelization. It allows defining datasets and tasks to transform data. DCTC is a tool that can manipulate files across different storage systems like S3, GCS, HDFS to perform operations like copying, synchronizing, dispatching files. It aims to simplify common data transfer pains. The presentation concludes with contacting information for Dataiku executives.
















































![[DSC Europe 23] Matteo Molteni - Implementing a Robust CI Workflow with dbt f...](https://cdn.slidesharecdn.com/ss_thumbnails/matteomolteni-implementingarobustciworkflow-231129090959-794aed63-thumbnail.jpg?width=640&height=640&fit=bounds)















































