Download as PDF, PPTX





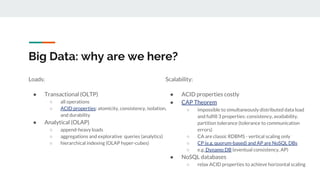

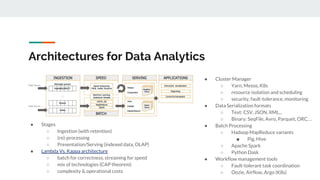

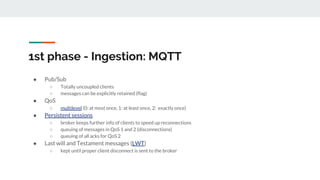
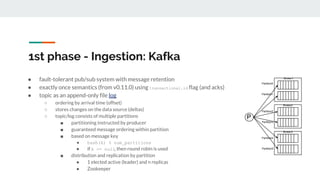





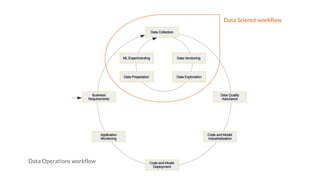
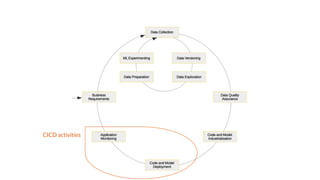
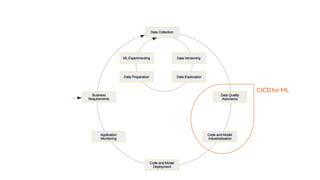
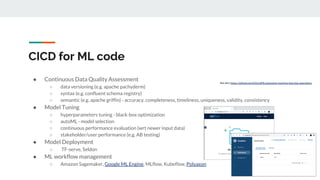



The document discusses integrating data science workflows with continuous integration and delivery (CICD) practices, known as Data Operations or DataOps. It outlines challenges in traditional data science workflows around data versioning, reproducibility, and delivering value incrementally. Key aspects of CICD for data and models are described, including continuous data quality assessment, model tuning, and deployment. The Data-Mill project is introduced as an open-source platform for enforcing DataOps principles on Kubernetes clusters through modular "flavors" of software components and built-in exploration environments.












































































