Download as PDF, PPTX



















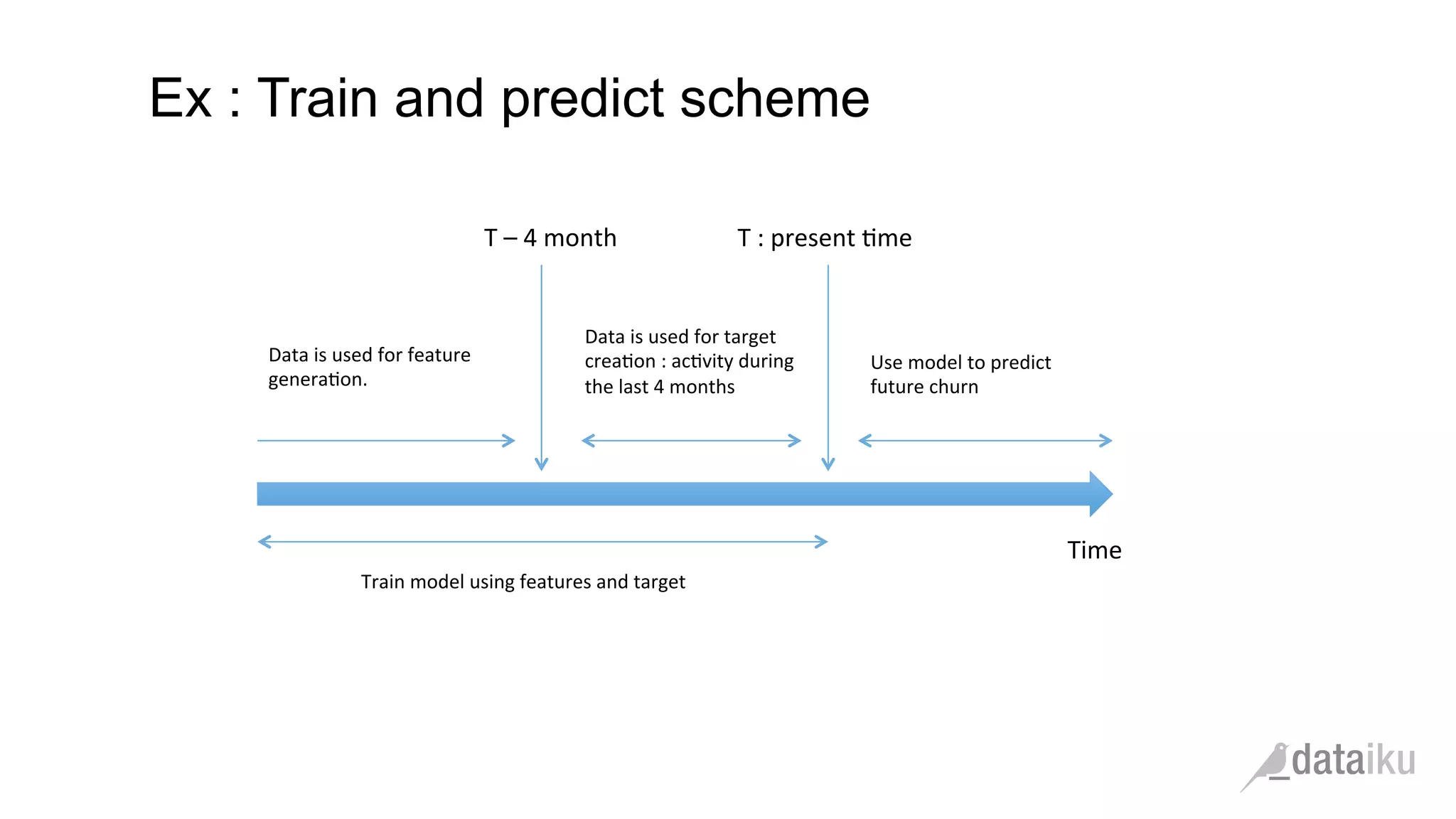
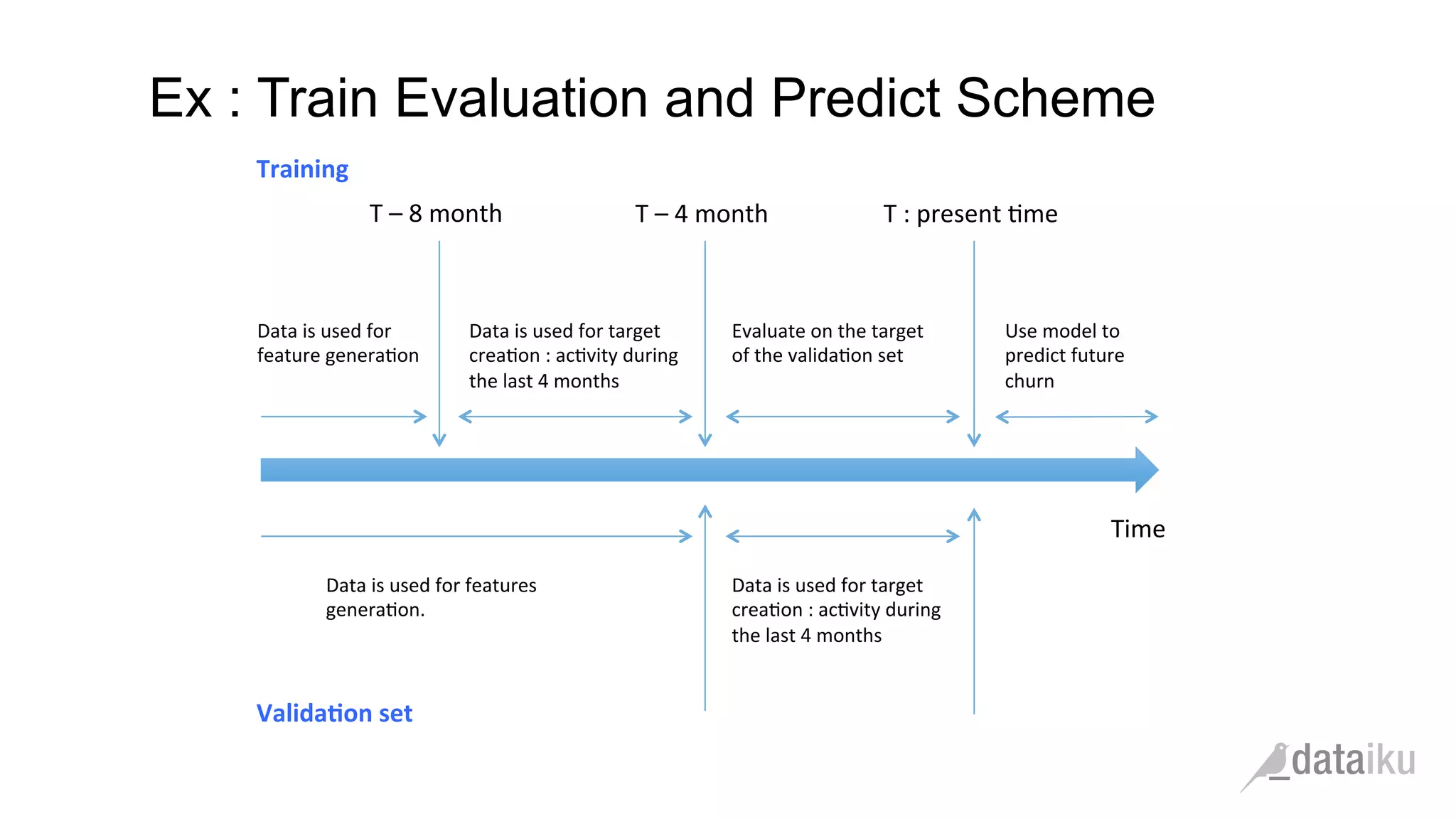


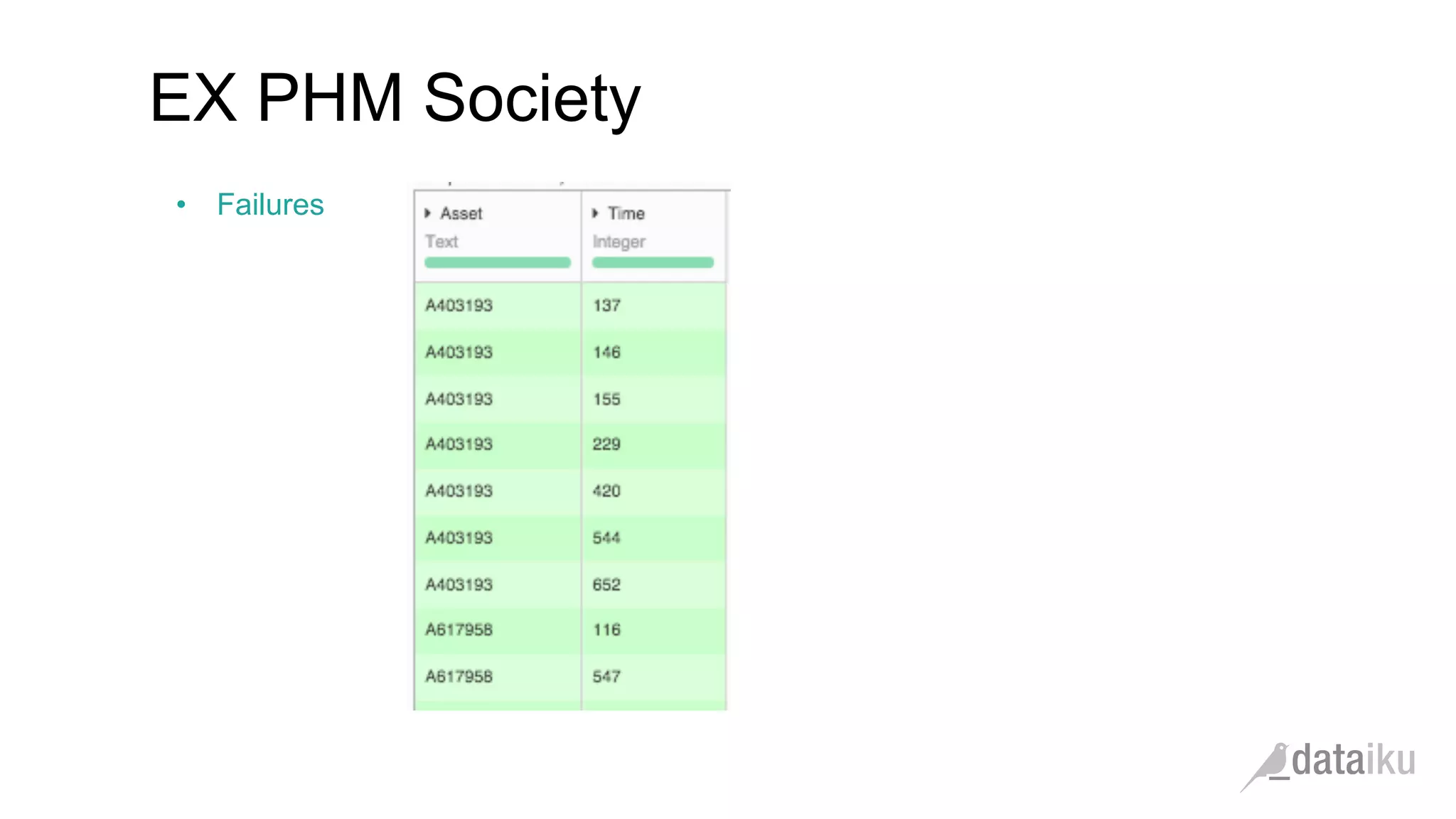
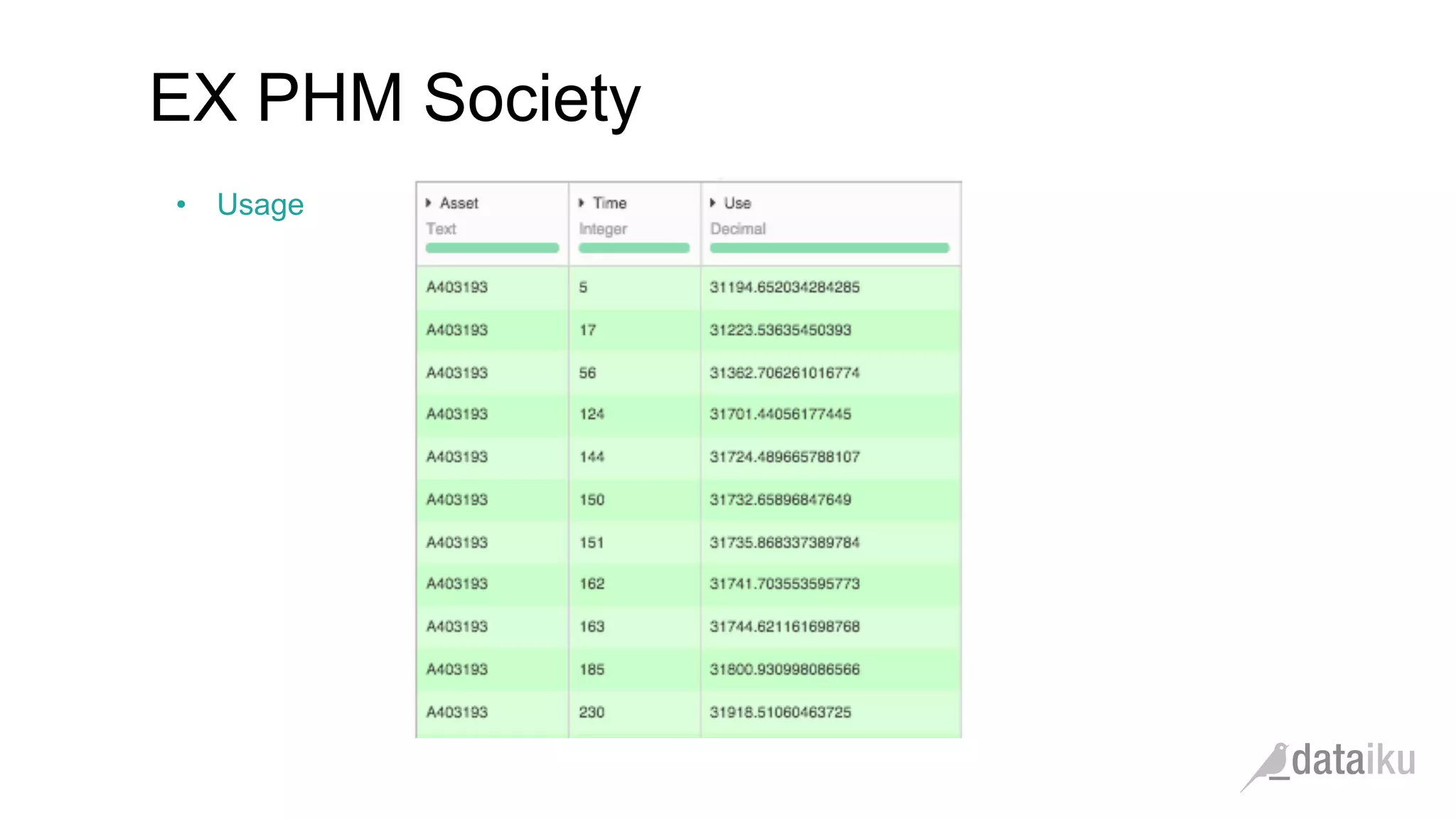
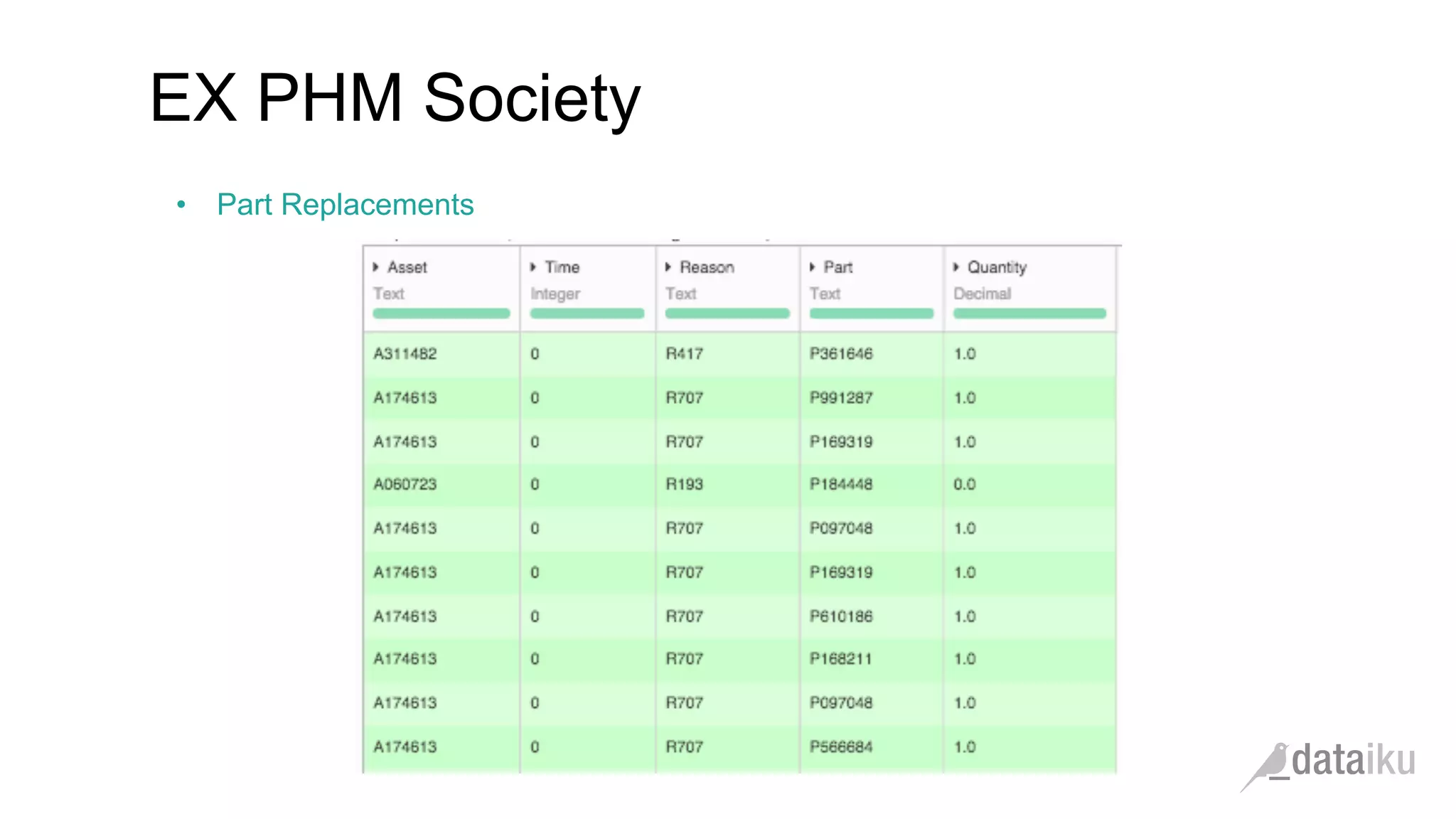

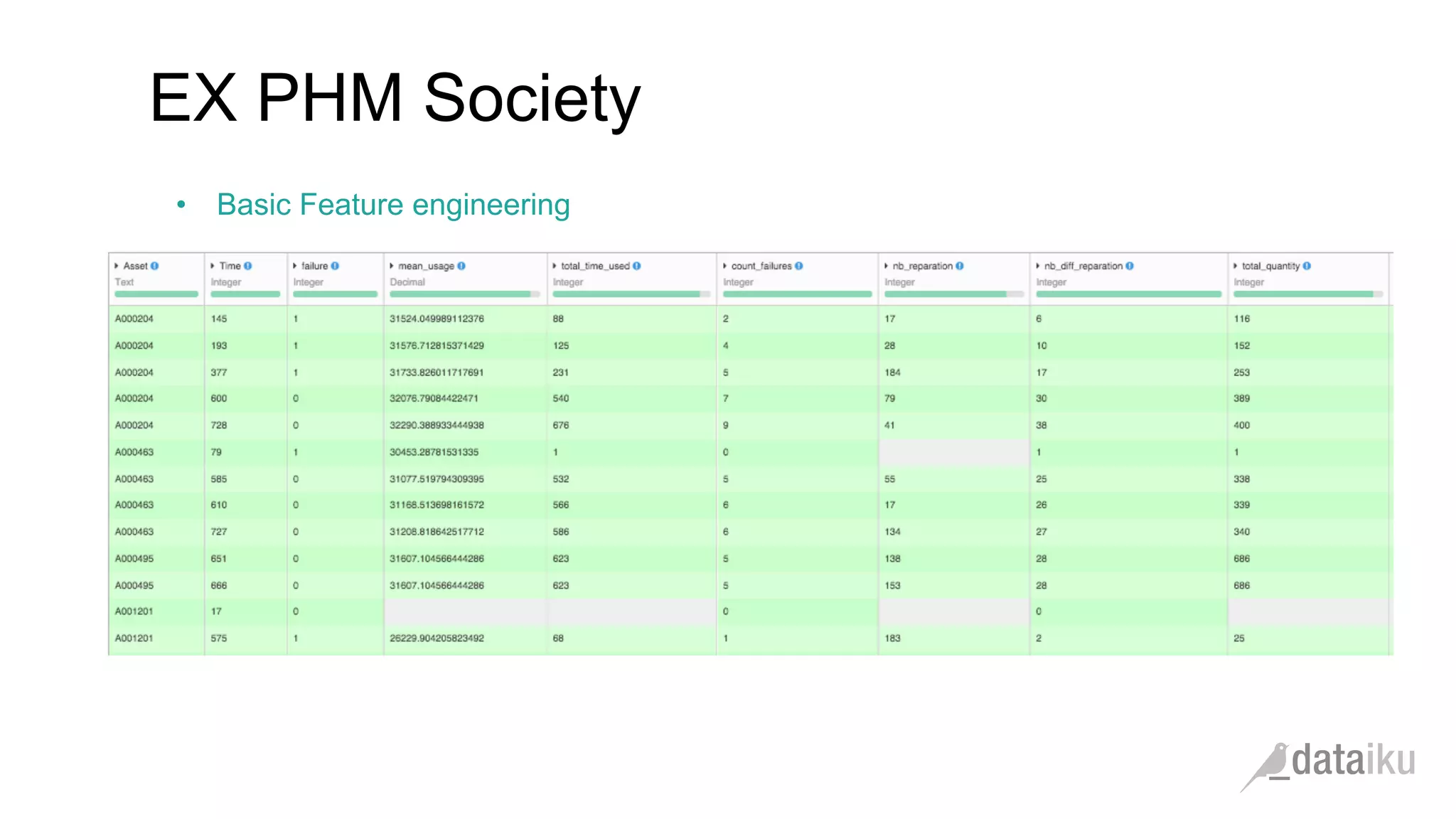
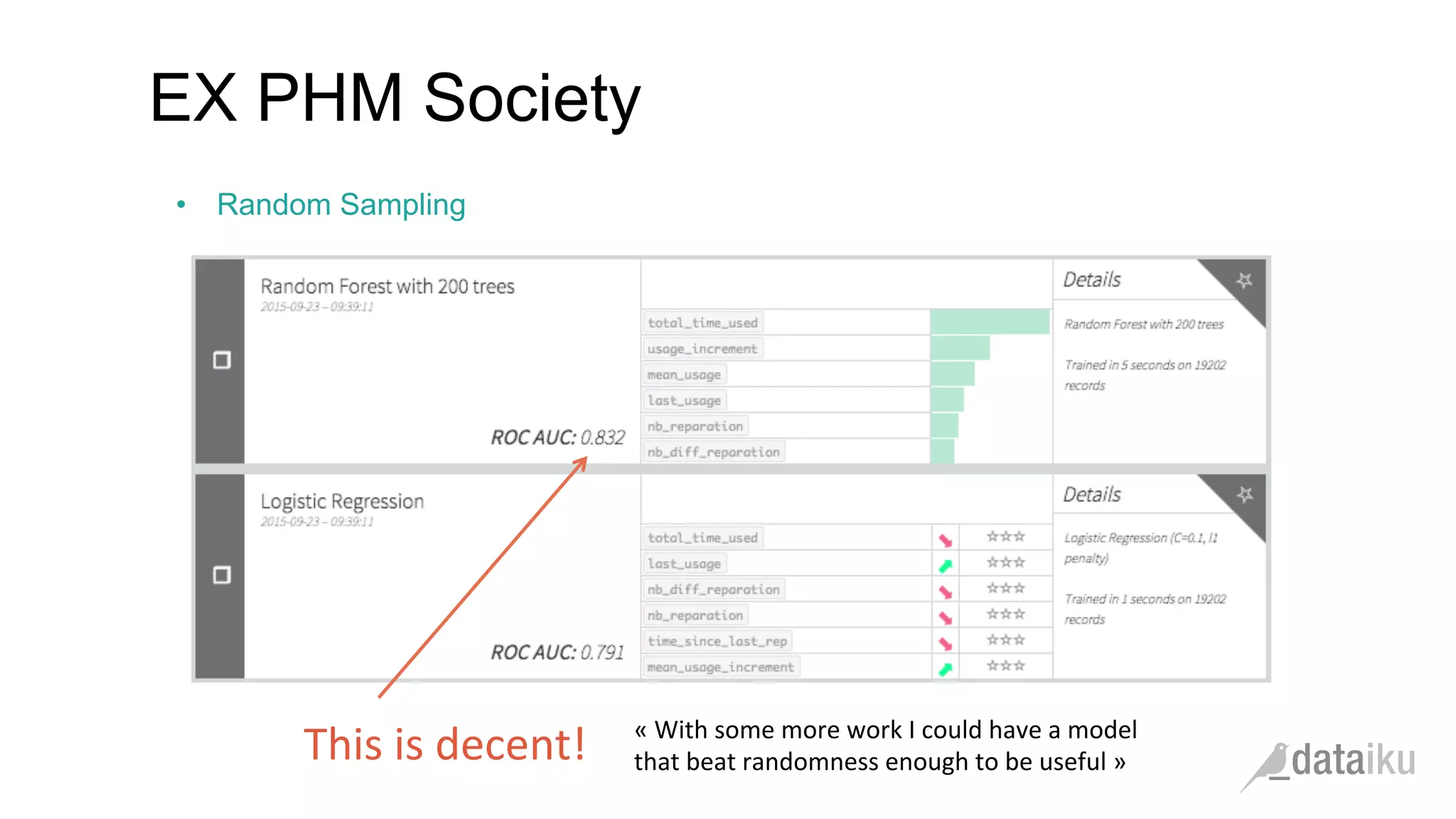

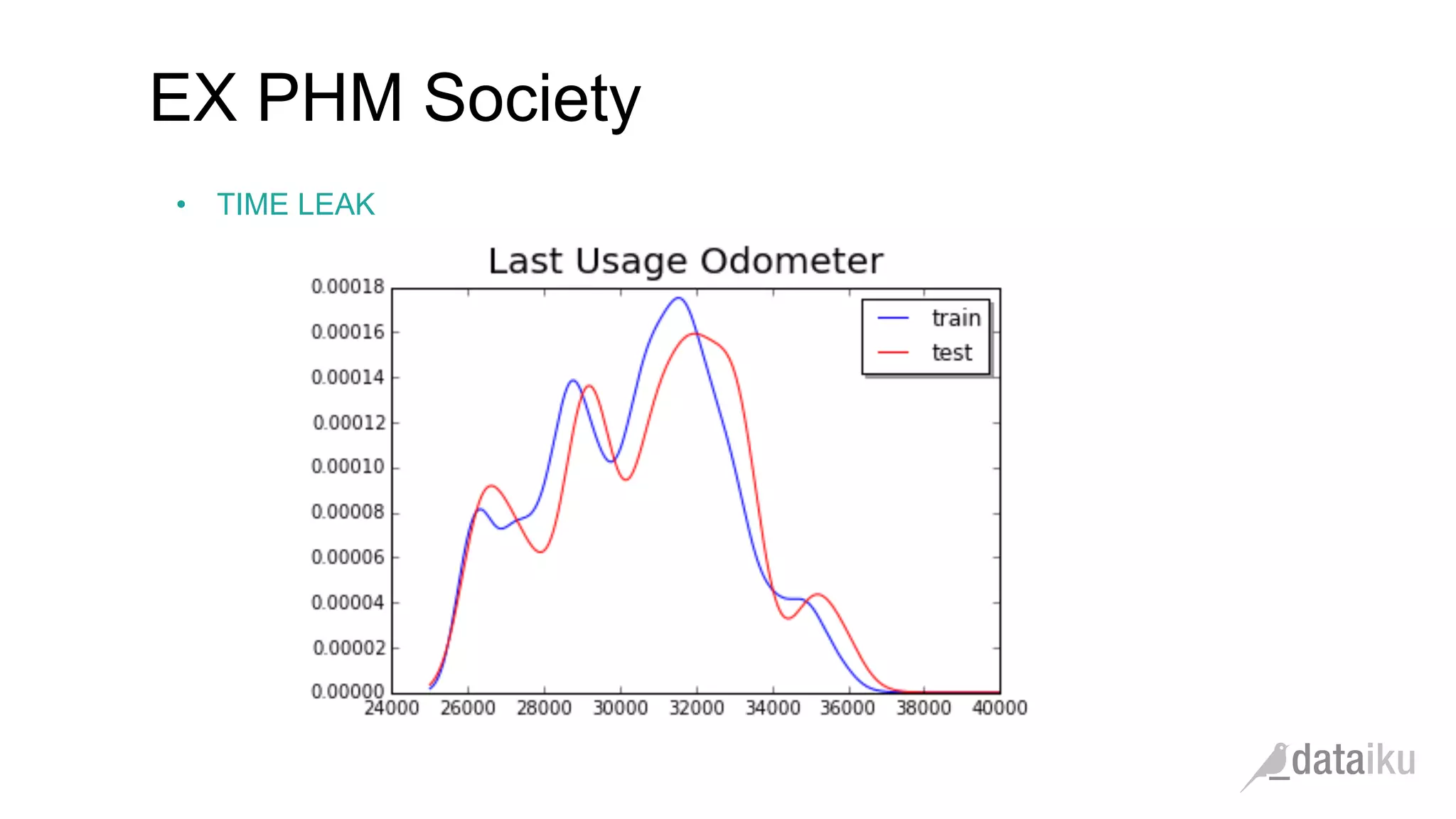
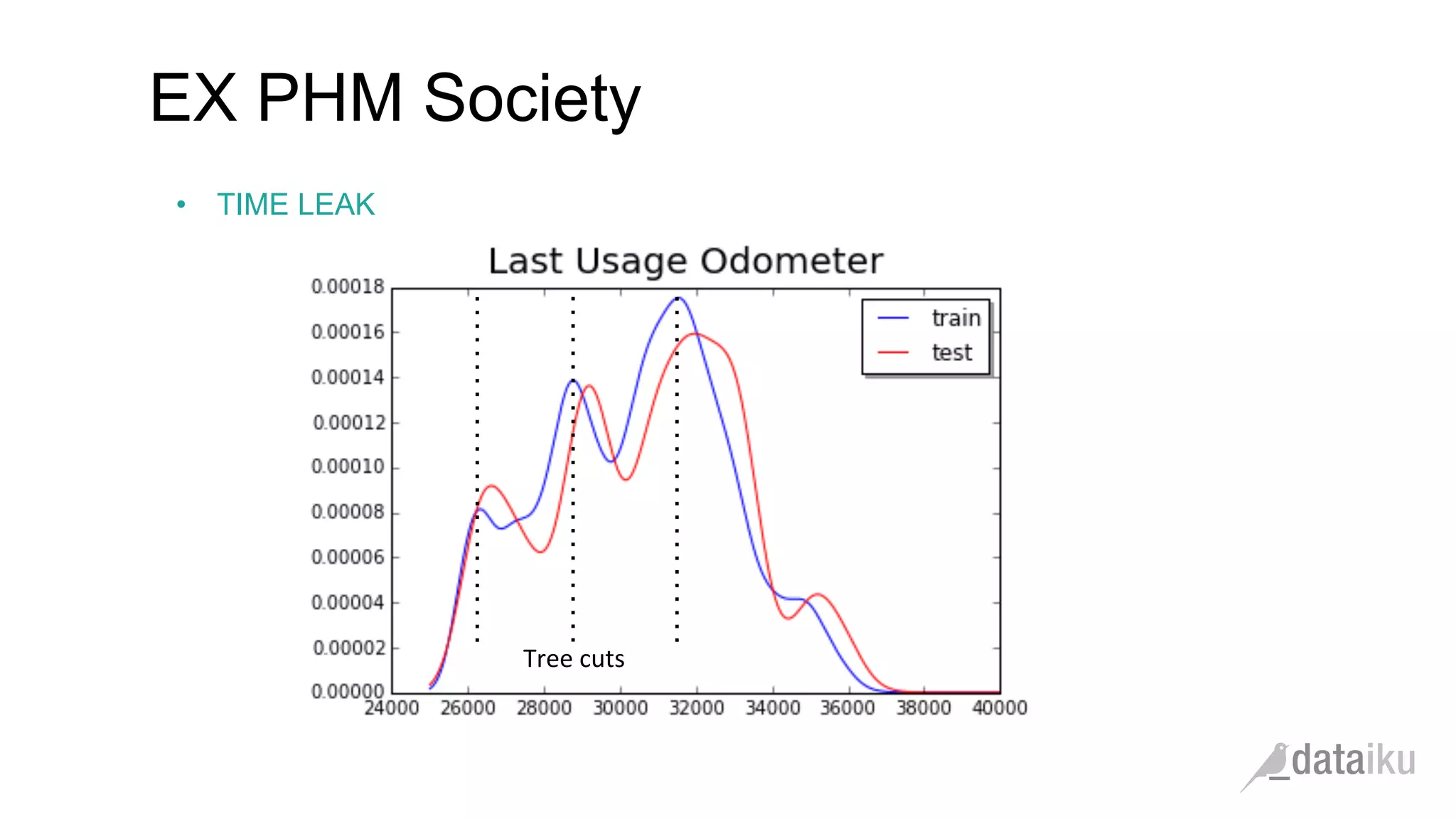


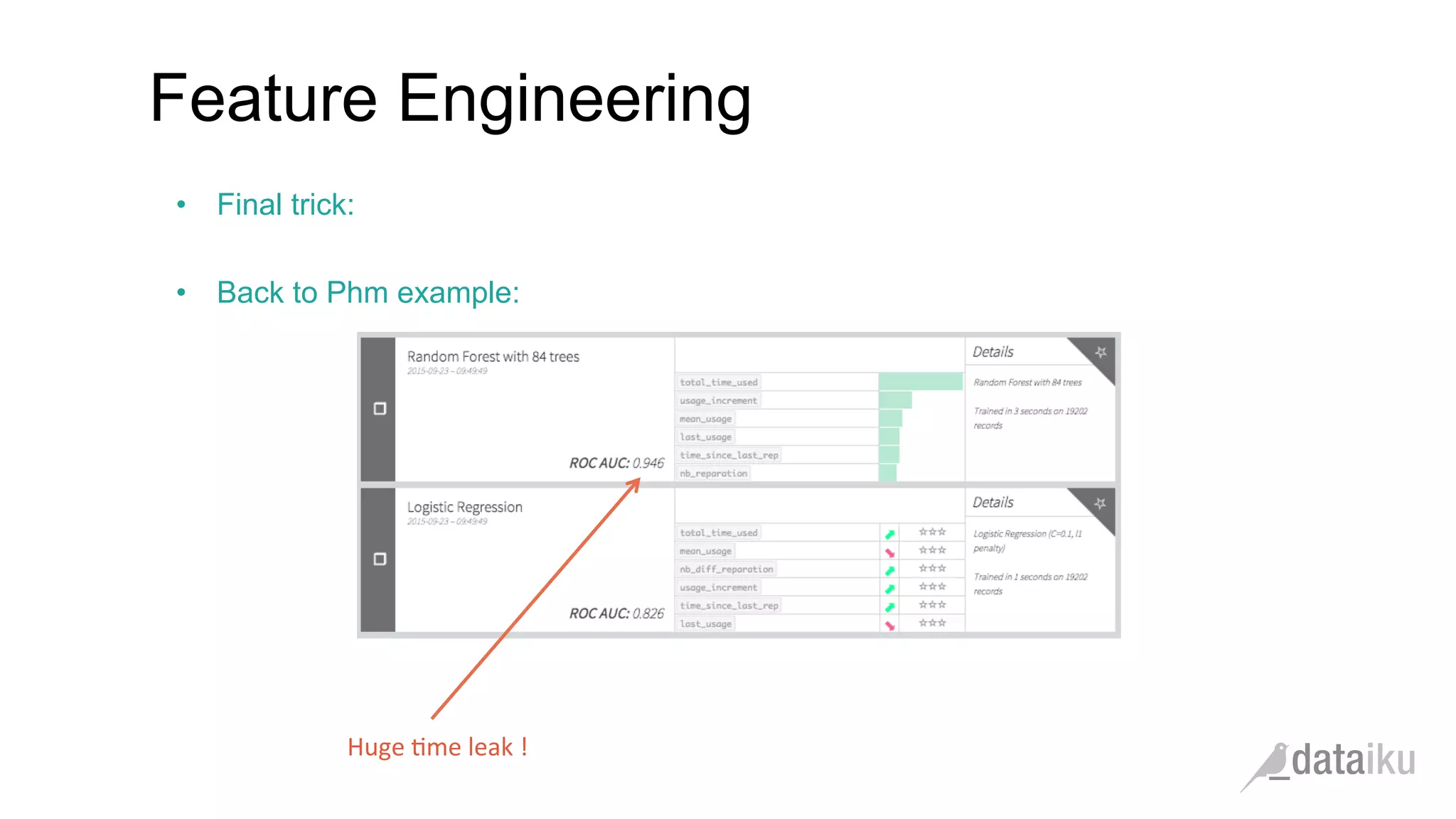





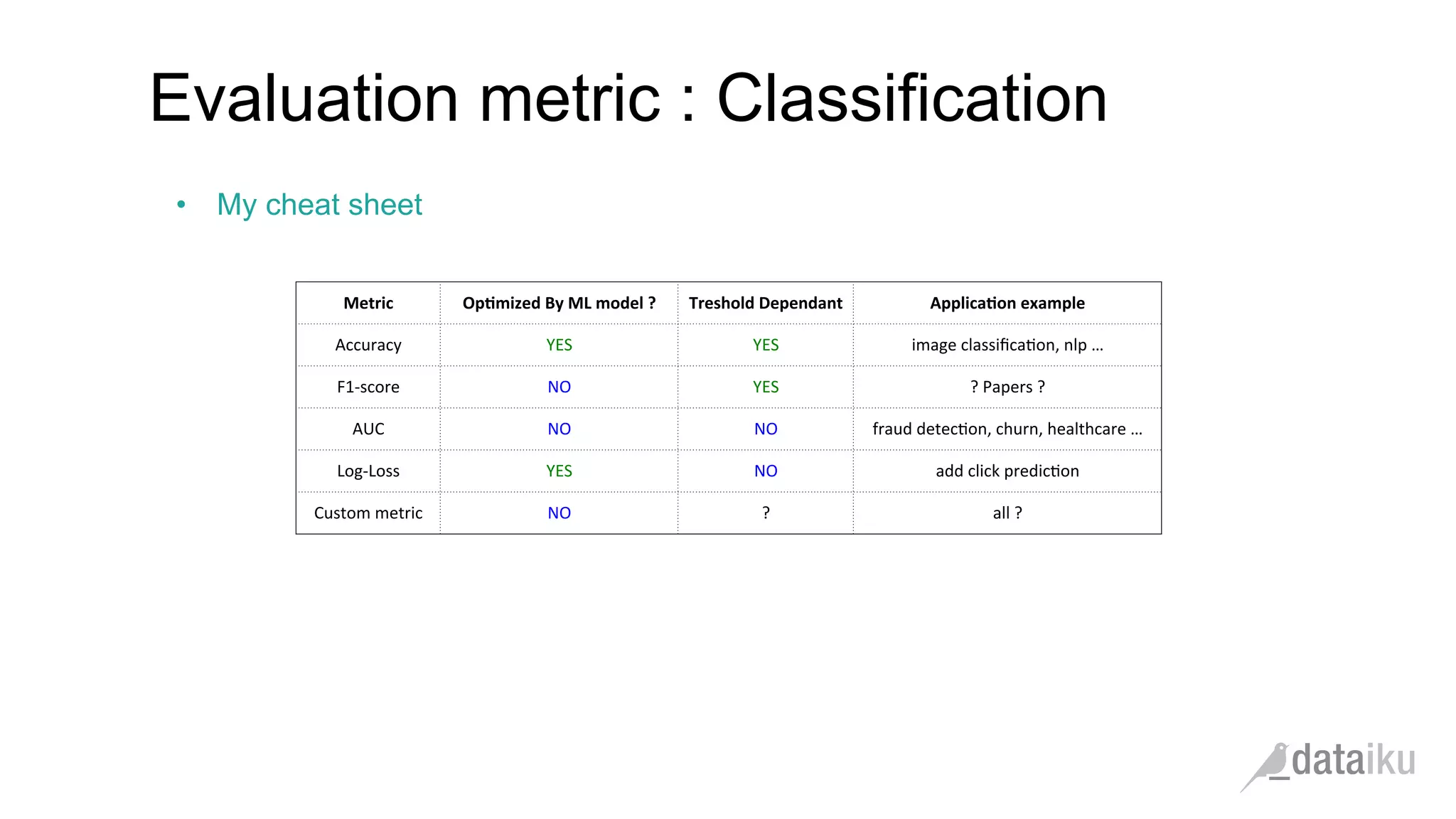



The document discusses the importance of transforming business goals into machine learning (ML) problems, highlighting the role of data science competitions, particularly on Kaggle. Key topics include the understanding of datasets, feature engineering, and appropriate model evaluation metrics, such as AUC and F1 score, with emphasis on time-based train/test splits for predictive modeling. It also addresses common pitfalls and essential strategies for effectively participating in data science competitions and mastering ML fundamentals.
































































































