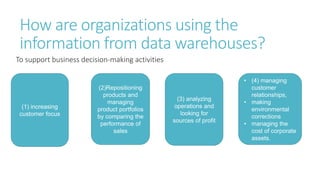
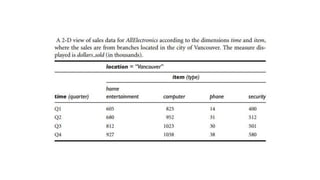
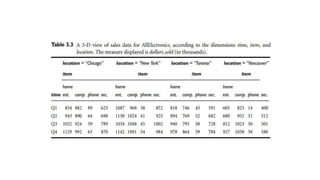
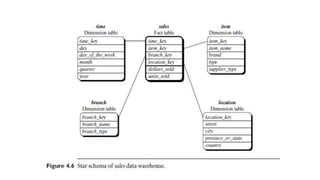
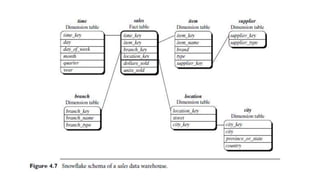
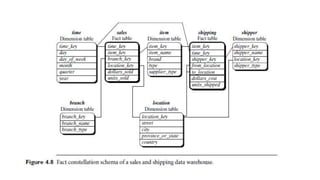
The document provides an overview of data warehousing, including definitions, architectures, and the distinction between data warehouses and operational databases. It describes data warehousing processes such as data cleaning, integration, and the multidimensional data model with schemas like star and snowflake. Additionally, it discusses applications of data warehouses in business decision-making and outlines how data marts operate as departmental subsets of a data warehouse.