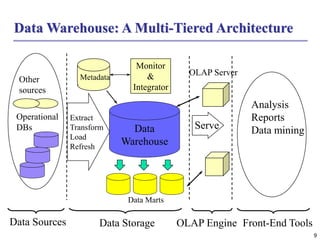
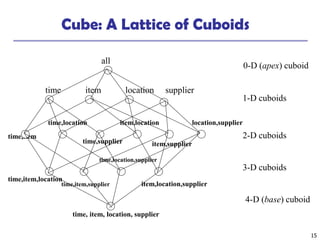
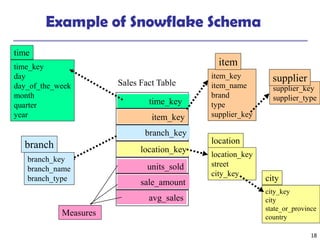
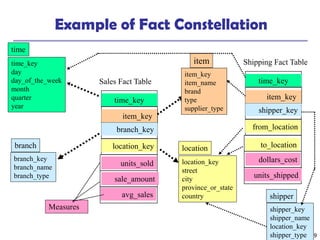
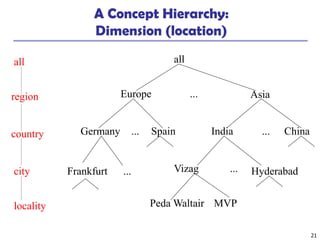
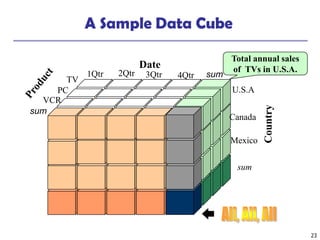
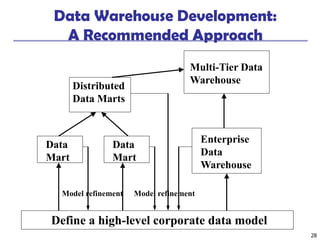
The document provides a comprehensive overview of data warehousing and online analytical processing (OLAP), focusing on the fundamental concepts, models, and processes involved in constructing and utilizing data warehouses. Key topics include the distinction between operational databases and data warehouses, the architecture of data warehouses, and various OLAP operations such as roll-up and slice and dice. It further explores data modeling techniques, data cube definitions, and the necessity of extraction, transformation, and loading (ETL) processes for effective data analysis.






















![32
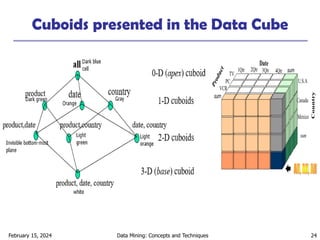
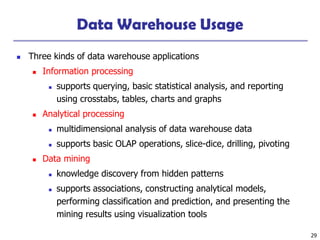
The “Compute Cube” Operator
Cube definition and computation in DMQL
define cube sales [item, city, year]: sum (sale amount)
compute cube sales
Transform it into a SQL-like language (with a new operator cube by)
SELECT item, city, year, SUM (sale amount)
FROM SALES
CUBE BY item, city, year
Need to compute following Group-Bys
( item, city, year),
(item,year),(city,year), (city,item),
(year), (item), (city)
()
(item)
(city)
()
(year)
(city, item) (city, year) (item, year)
(city, item, year)](https://image.slidesharecdn.com/dwhandolap-241110012733-166e67c2/85/data-warehousing-and-online-analtytical-processing-32-320.jpg)










![43
Presentation of Generalized Results
Generalized relation:
Relations where some of the attributes are generalized, with counts
or other aggregation values accumulated.
Cross tabulation:
Mapping results into cross tabulation form (similar to contingency
tables).
Visualization techniques:
Pie charts, bar charts, curves, cubes, and other visual forms.
Quantitative characteristic rules:
Mapping generalized result into characteristic rules with quantitative
information associated with it, e.g.,
.
%]
47
:
[
"
"
)
(
_
%]
53
:
[
"
"
)
(
_
)
(
)
(
t
foreign
x
region
birth
t
Canada
x
region
birth
x
male
x
grad
](https://image.slidesharecdn.com/dwhandolap-241110012733-166e67c2/85/data-warehousing-and-online-analtytical-processing-43-320.jpg)



















































