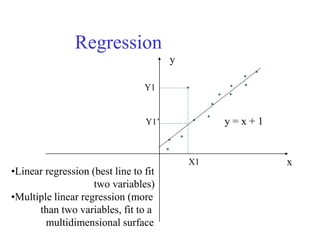
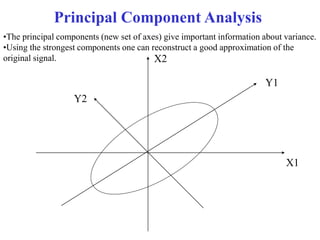
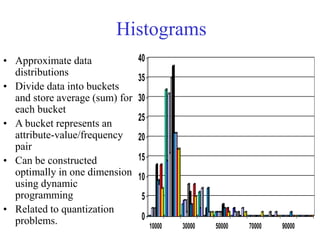
This document discusses various techniques for data preprocessing which is an important step in the knowledge discovery process. It covers why preprocessing is needed due to issues with real-world data being dirty, noisy, incomplete etc. The major tasks covered are data cleaning, integration, transformation and reduction. Specific techniques discussed include data cleaning methods like handling missing values, noisy data, and inconsistencies. Data integration addresses combining multiple sources and resolving conflicts. Transformation techniques include normalization, aggregation, and discretization. Data reduction aims to reduce volume while maintaining analytical quality using methods like cube aggregation, dimensionality reduction, and data compression.