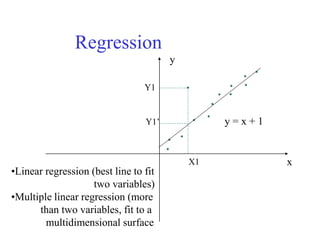
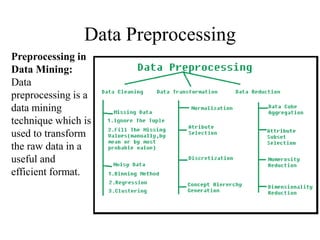
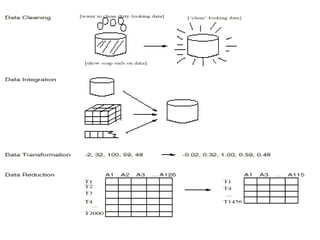
This document provides an overview of key concepts in data preprocessing for data science. It discusses why preprocessing is important due to issues with real-world data being dirty, incomplete, noisy or inconsistent. The major tasks covered are data cleaning (handling missing data, outliers, inconsistencies), data integration, transformation (normalization, aggregation), and reduction (discretization, dimensionality reduction). Clustering and regression techniques are also introduced for handling outliers and smoothing noisy data. The goal of preprocessing is to prepare raw data into a format suitable for analysis to obtain quality insights and predictions.




















![Sample Dataset
Countrydata=
[['India‘, 38.0, 68000.0] ,
['France‘, 43.0, 45000.0],
['Germany‘, 30.0, 54000.0],
['France' ,48.0,NaN]
]
List or tuple or dictionary
Df=pd.DataFrame(countrydata,
columns=[“country”,”no_states”,”Area”])](https://image.slidesharecdn.com/preprocessingnew-230601124640-05f6ce55/85/Preprocessing_new-ppt-22-320.jpg)
![# importing libraries
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd
#importing datasets
data_set= pd.read_csv('Dataset.csv')
#Viewing Dataframe , position index
x= data_set.iloc[:, [0:2]]
#Using column names
y= data_set.loc[:, [‘country’,’area’]]
'India‘, 38.0, 68000.0
'France‘, 43.0, 45000.0
’Germany‘, 30.0, 54000.0
’France' ,48.0,NaN
Country no_states area
0 India 38.0 68000.0
1
2
3](https://image.slidesharecdn.com/preprocessingnew-230601124640-05f6ce55/85/Preprocessing_new-ppt-23-320.jpg)
![Operations
df.shape (rows,columns)
df.head(), df.head(2) default first 5 rows,
df.tail(), df.tail(4) default last 5 rows
df[2:5], df[0::2] intial,final,step value rows
df.columns Index[‘ ‘,’ ‘,’ ‘] column
names
df.empid or df[‘empid’] list of columns to be
passed](https://image.slidesharecdn.com/preprocessingnew-230601124640-05f6ce55/85/Preprocessing_new-ppt-24-320.jpg)
![df[‘area’].min()
df[‘area’].max()
df.describe()
Count,mean,std,min,25%,50%,75%,max of all
coumns
df1=df.sort_values(‘country’)](https://image.slidesharecdn.com/preprocessingnew-230601124640-05f6ce55/85/Preprocessing_new-ppt-25-320.jpg)


![df.isnull().sum() ============= >zero initially
df[‘column’].mean()
df[‘column’].fillna(df[[‘column’].mean(), inplace=True)
df[‘column’].fillna(df[[‘column’].mode(), inplace=True)
df[‘column’].fillna(df[[‘column’].median(), inplace=True)
df.isnull().sum() ============= ==>zero](https://image.slidesharecdn.com/preprocessingnew-230601124640-05f6ce55/85/Preprocessing_new-ppt-28-320.jpg)


![• Sorted data for price (in dollars): 4, 8, 9, 15,
21, 21, 24, 25, 26, 28, 29, 34
• Equal-width no of bins:3
• 34-4=30/3=10
• Bin 1: 4..4+10==4..14 [4,8,9]
• Bin 2:15..15+10==15..25 [15,21,21,24,25]
• Bin 3:26..26+10==26..36 [26,28,29,34]](https://image.slidesharecdn.com/preprocessingnew-230601124640-05f6ce55/85/Preprocessing_new-ppt-31-320.jpg)





![# take 1st column among 4 column of data set
for i in range (150):
b[i]=a[i,1]
b=np.sort(b) #sort the array
• # create bins
• bin1=np.zeros((30,5))
• bin2=np.zeros((30,5))
• bin3=np.zeros((30,5))](https://image.slidesharecdn.com/preprocessingnew-230601124640-05f6ce55/85/Preprocessing_new-ppt-38-320.jpg)
![# Bin mean
for i in range (0,150,5):
k=int(i/5)
mean=(b[i] + b[i+1] + b[i+2] + b[i+3] +
b[i+4])/5
for j in range(5):
bin1[k,j]=mean
print("Bin Mean: n",bin1)](https://image.slidesharecdn.com/preprocessingnew-230601124640-05f6ce55/85/Preprocessing_new-ppt-39-320.jpg)


![Outlier Treatment
Q1=df[‘area’].quantile(0.05)
Q2=df[‘area’].quantile(0.95)
df['a'] = np.where((df.a < Q1), Q1, df.a)
df.loc[(df.a > Q2), Q2, df.a)](https://image.slidesharecdn.com/preprocessingnew-230601124640-05f6ce55/85/Preprocessing_new-ppt-43-320.jpg)
![Univariate outliers can be found when looking at a
distribution of values in a single feature space.
Multivariate outliers can be found in an n-
dimensional space (of n-features).
Point outliers are single data points that lay far from
the rest of the distribution.
Contextual outliers can be noise in data, such as
punctuation symbols when realizing text analysis
Collective outliers can be subsets of novelties in
data
[1,35,20,32,40,46,45,4500]](https://image.slidesharecdn.com/preprocessingnew-230601124640-05f6ce55/85/Preprocessing_new-ppt-44-320.jpg)