Download to read offline





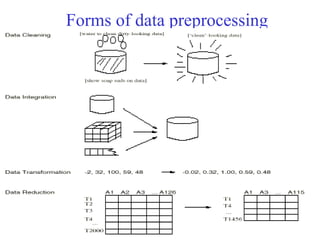








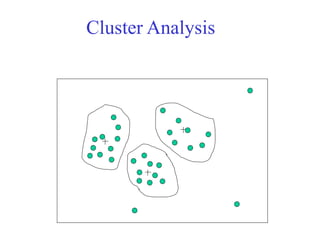
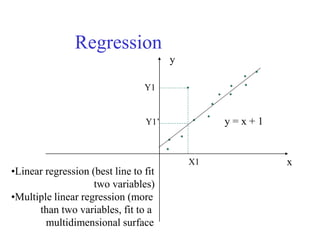











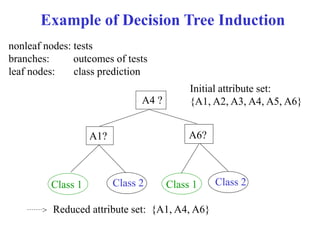

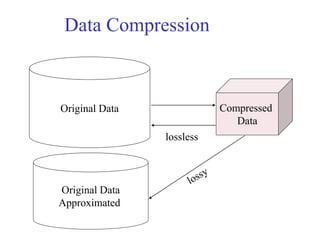


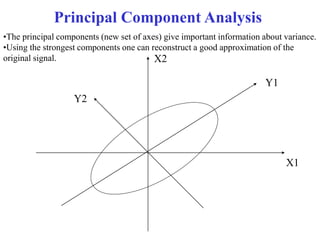



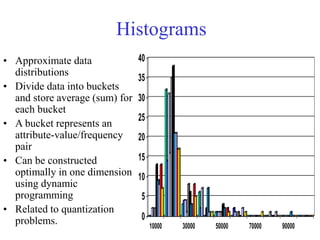


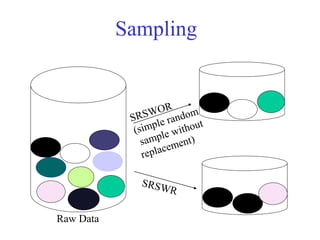
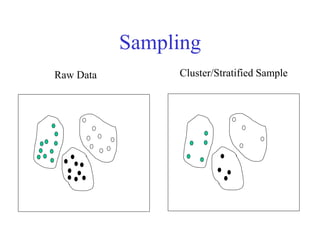







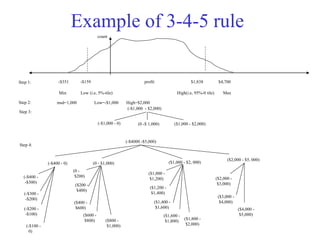





This document provides an overview of key tasks in data preprocessing for knowledge discovery and data mining. It discusses why preprocessing is important, as real-world data is often dirty, noisy, incomplete, and inconsistent. The major tasks covered are data cleaning, integration, transformation, reduction, discretization, and generating concept hierarchies. Data cleaning involves techniques for handling missing data, noisy data, and inconsistencies. Data integration combines multiple data sources. Data transformation includes normalization, aggregation, and generalization. The goal of data reduction is to obtain a smaller yet similar representation, using techniques like cube aggregation, dimensionality reduction, sampling, and discretization.















































