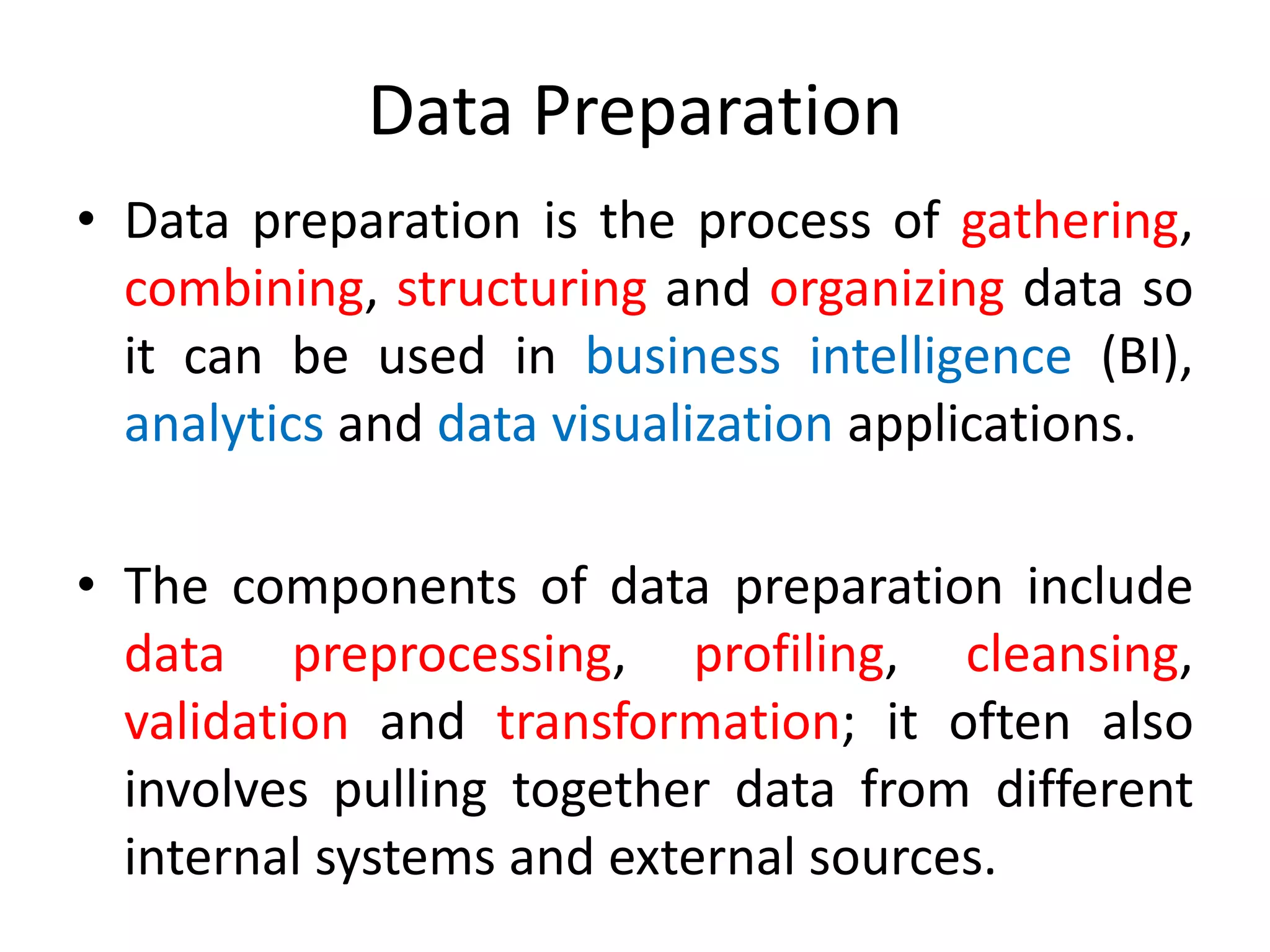
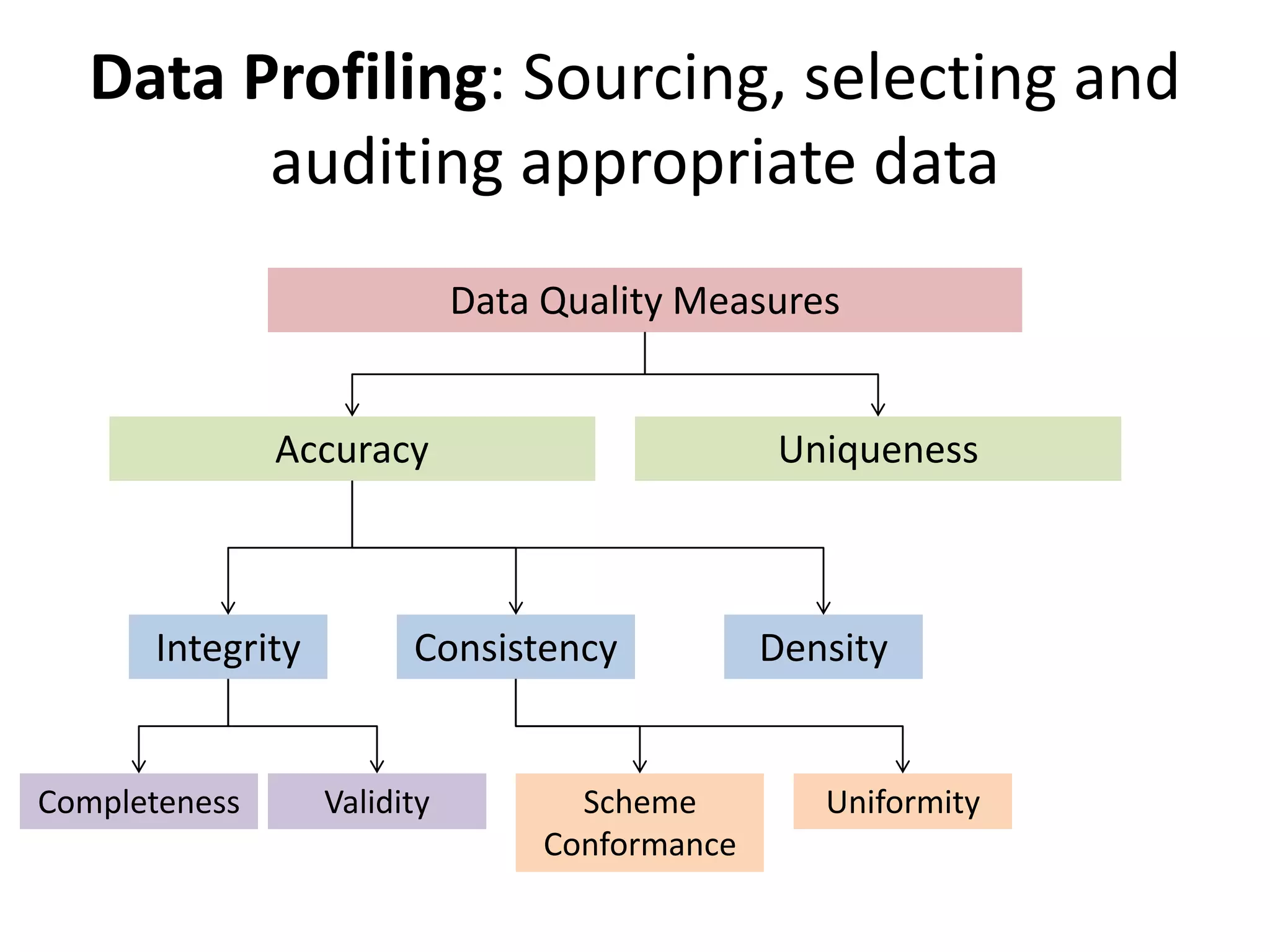
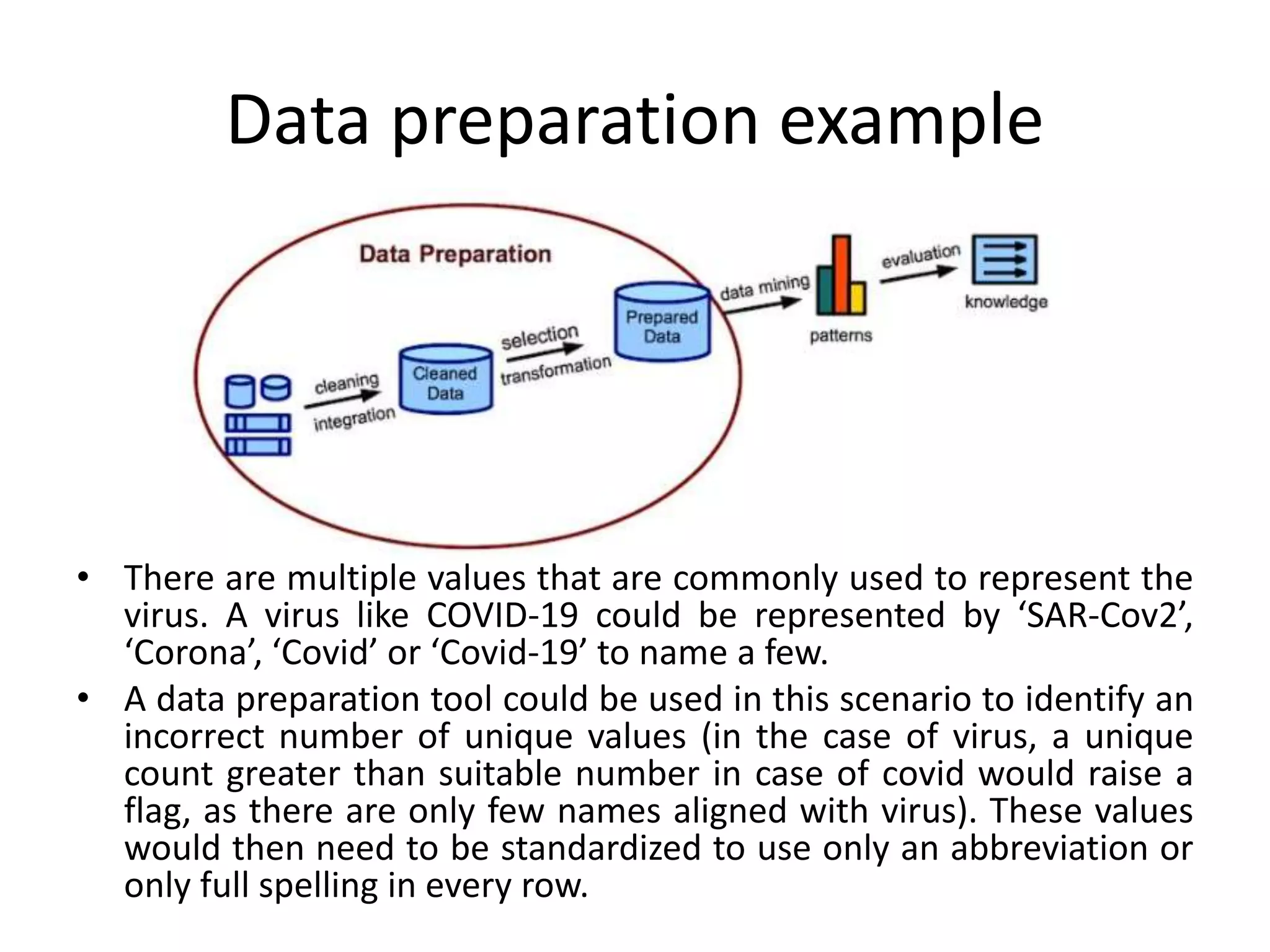
The document discusses various aspects of data preparation including data issues, the data preparation process, reasons for data preparation, benefits of data preparation, and key steps in data preparation such as data profiling, cleaning, integration, transformation, discretization, and binning. Specifically, it covers profiling data to ensure quality, cleaning data by handling anomalies and missing values, integrating and enriching data from multiple sources, transforming data for modeling purposes, discretizing continuous variables, and binning data to reduce effects of small errors. The overall goal of data preparation is to organize and structure raw data for analysis and modeling.























![• There are 2 methods of dividing data into bins.
• Equal Frequency Binning: bins have equal
frequency.
• Equal Width Binning: bins have equal width
with a range of each bin are defined as [min +
w], [min + 2w] …. [min + nw] where w = (max
— min) / (no of bins).](https://image.slidesharecdn.com/datapreparation-221228020537-e90bdcf2/75/Data-Preparation-pptx-27-2048.jpg)


































































![Where to Buy LinkedIn Accounts_ [12 Best Sites] (2).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/wheretobuylinkedinaccounts12bestsites2-251124191348-c246988b-thumbnail.jpg?width=640&height=640&fit=bounds)








