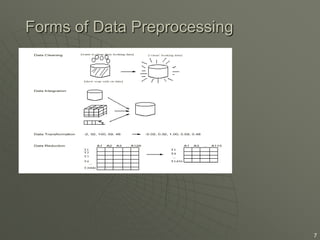
Data preprocessing involves cleaning, transforming, and reducing raw data to prepare it for data mining and analysis. It addresses issues like missing values, inconsistent data, and reducing data size. The key goals of data preprocessing are to handle data problems, integrate multiple data sources, and reduce data size while maintaining the same analytical results. Major tasks involve data cleaning, integration, transformation, and reduction.















![Min-max normalization
Suppose that min_A and max_A are the minimum
and maximum values of an attribute A.
Min-max normalization maps a value v of A to v’ in
the range [new_min_A, new_max_A]
March 6, 2014
17](https://image.slidesharecdn.com/datapreprocessing-140306000027-phpapp02/85/Data-pre-processing-17-320.jpg)