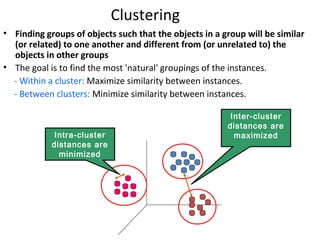
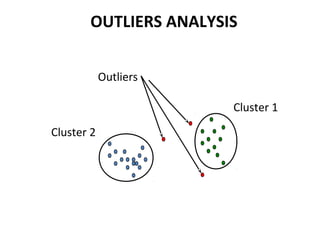
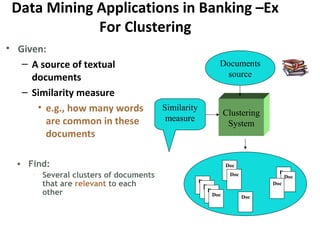
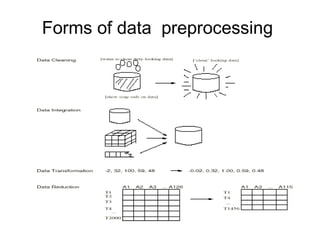
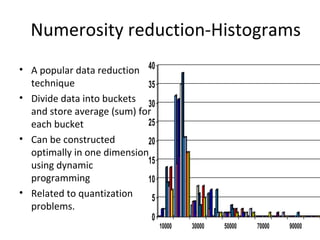
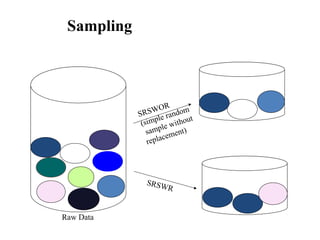
The document discusses key data mining functions including classification, clustering, outlier analysis, and association rules, explaining their applications in various fields such as sales, marketing, and banking. It details the importance of data preprocessing techniques to ensure high-quality data for mining, covering tasks like cleaning, integration, transformation, and reduction. Additionally, the document highlights data mining's role in predicting consumer behavior and managing customer relationships.