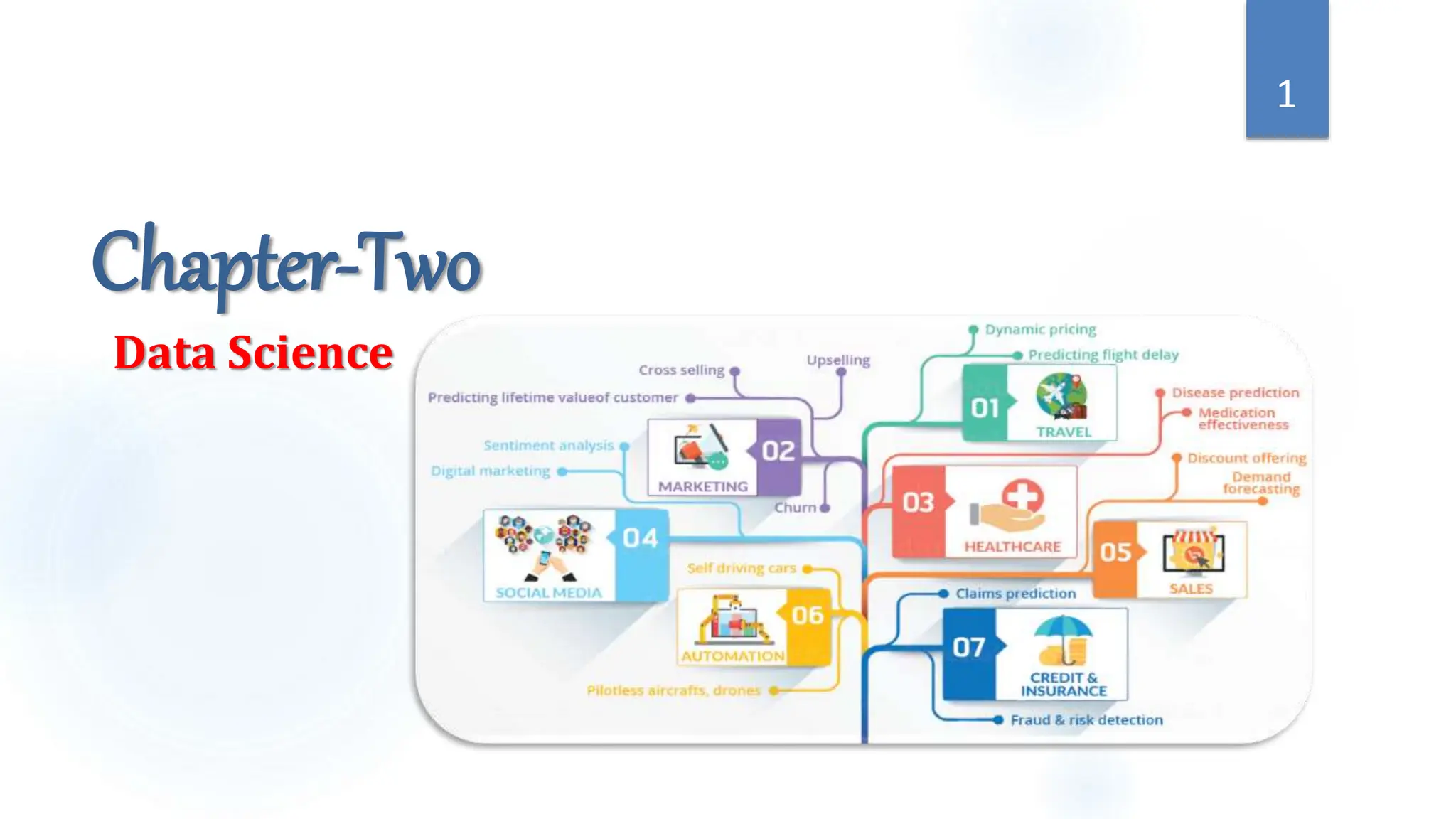
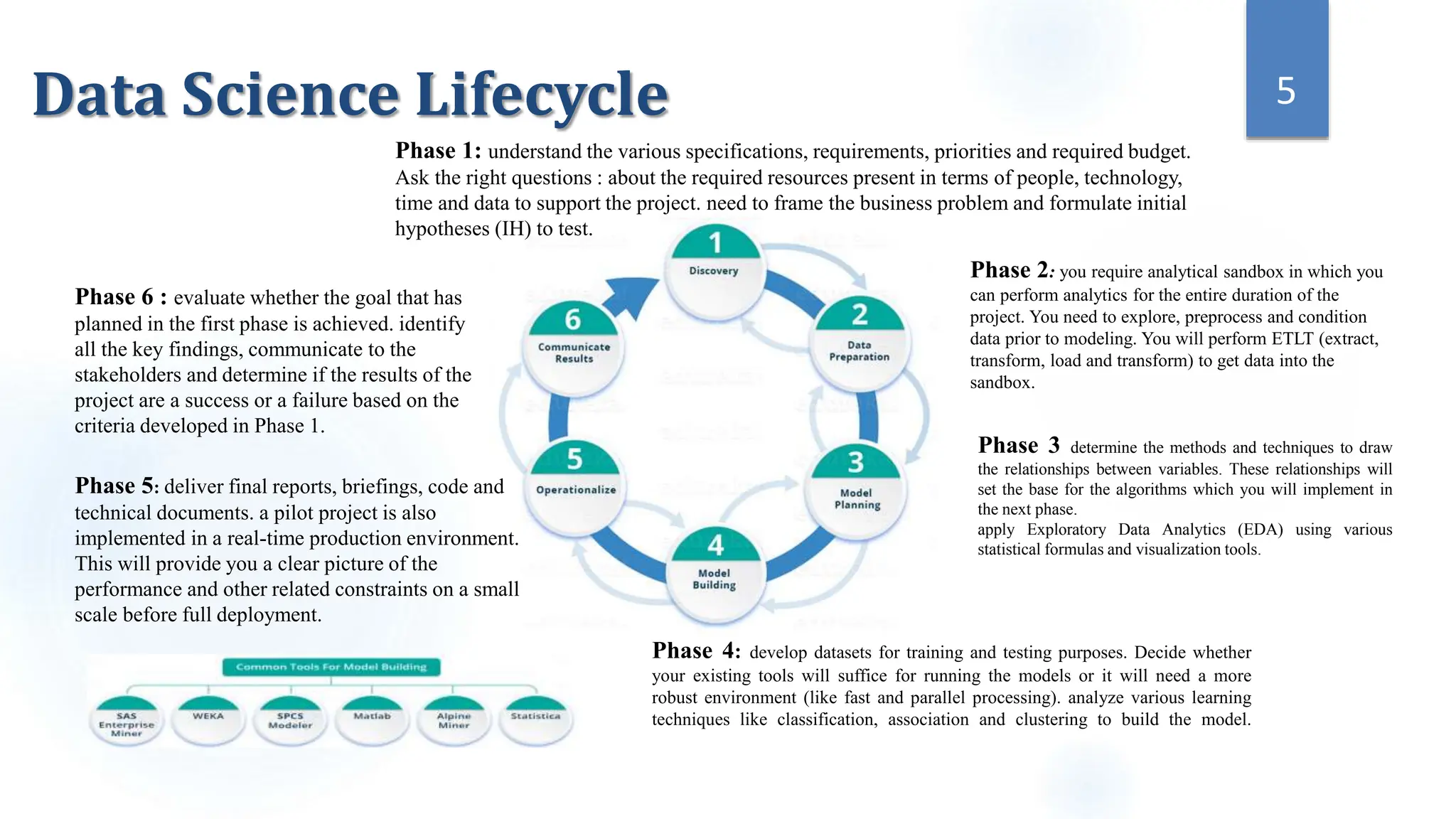
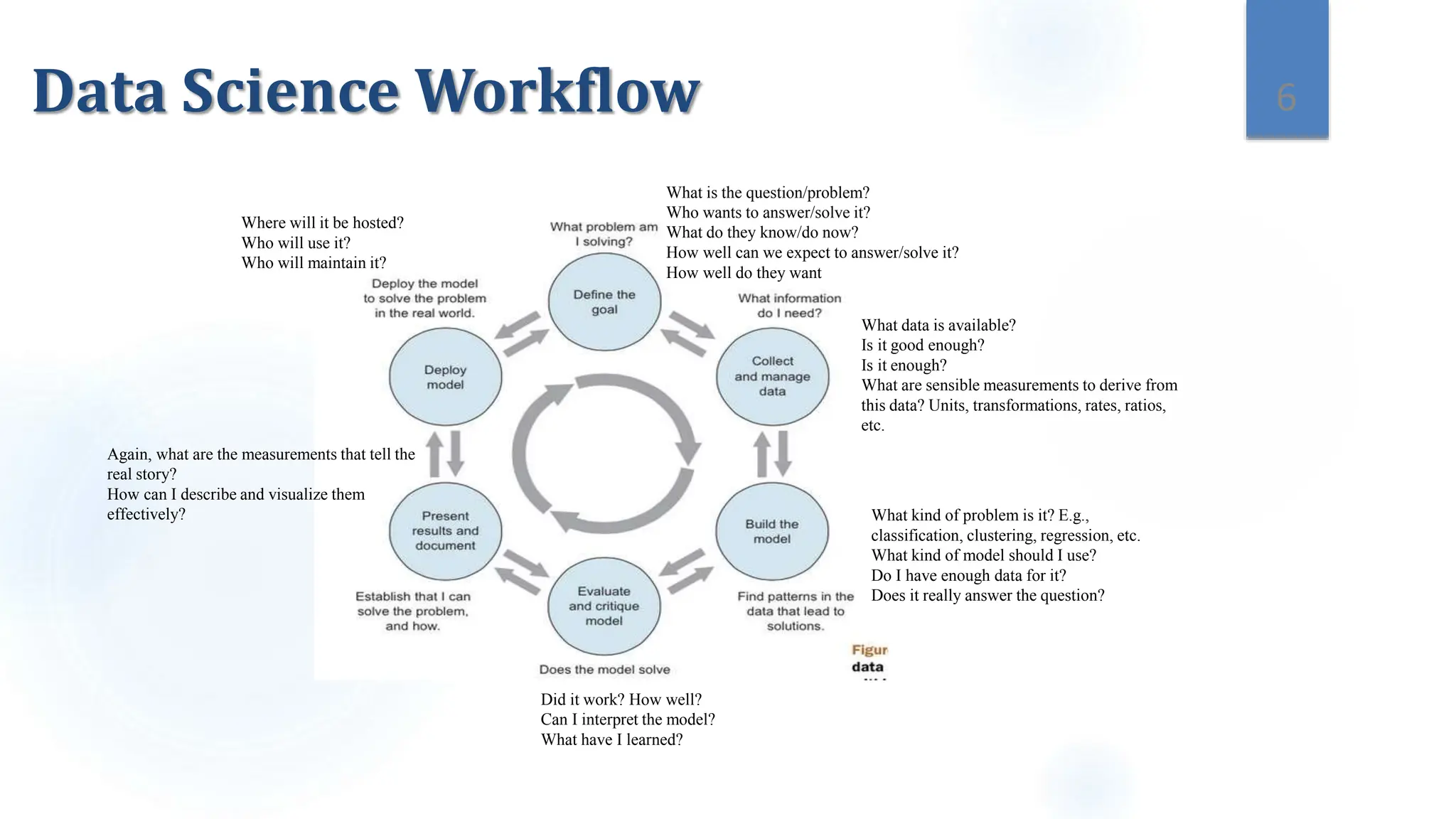
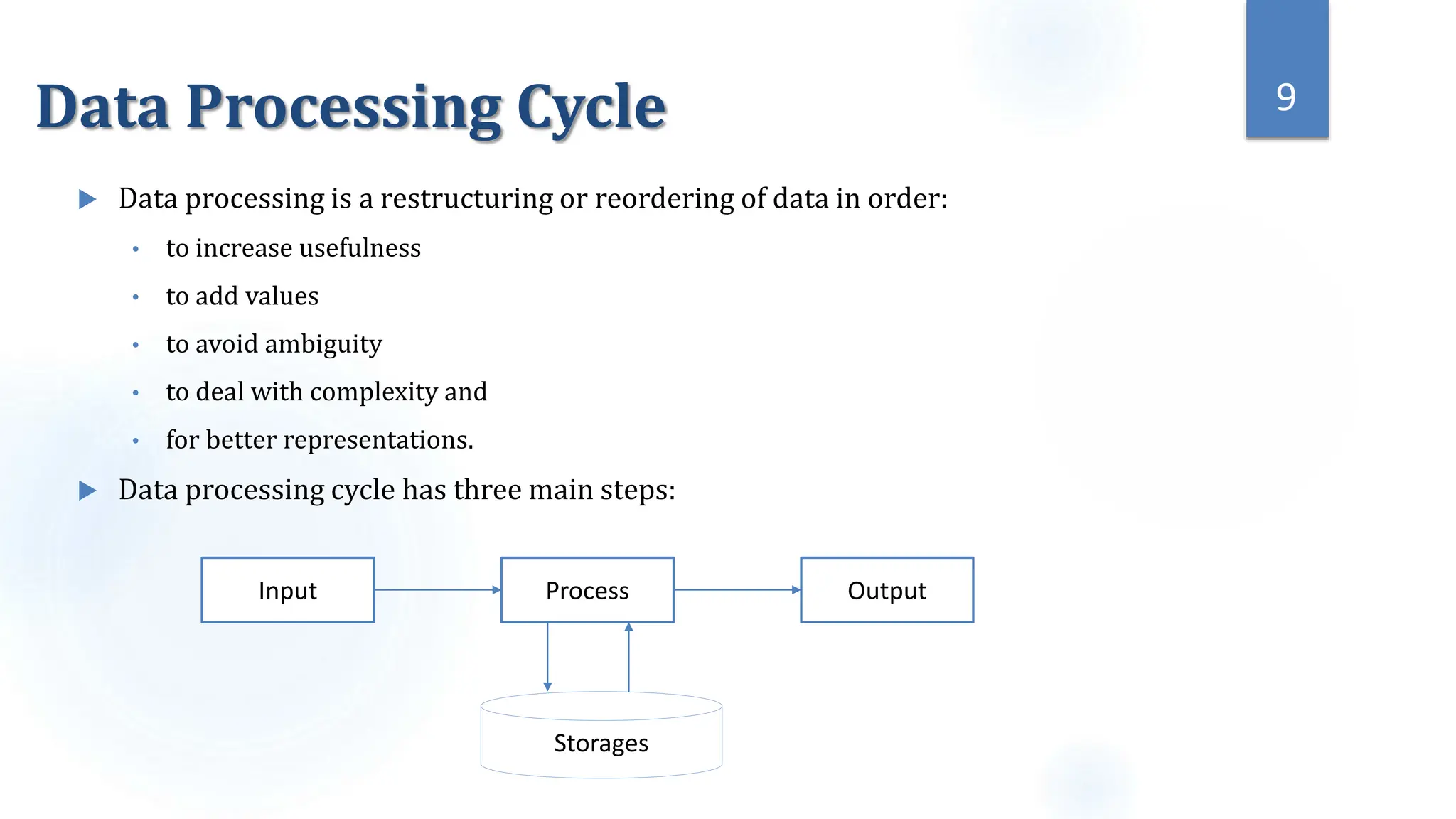
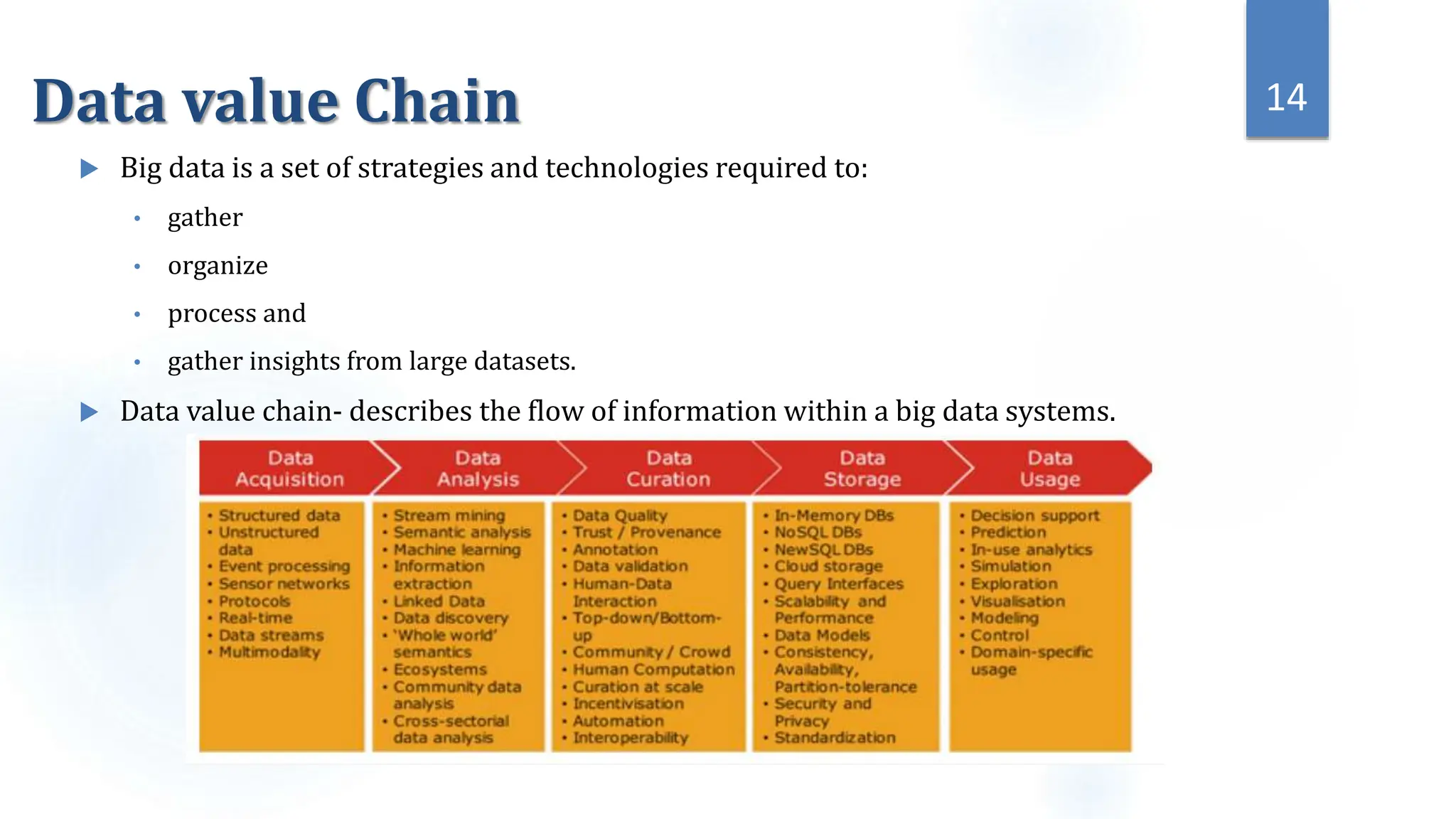
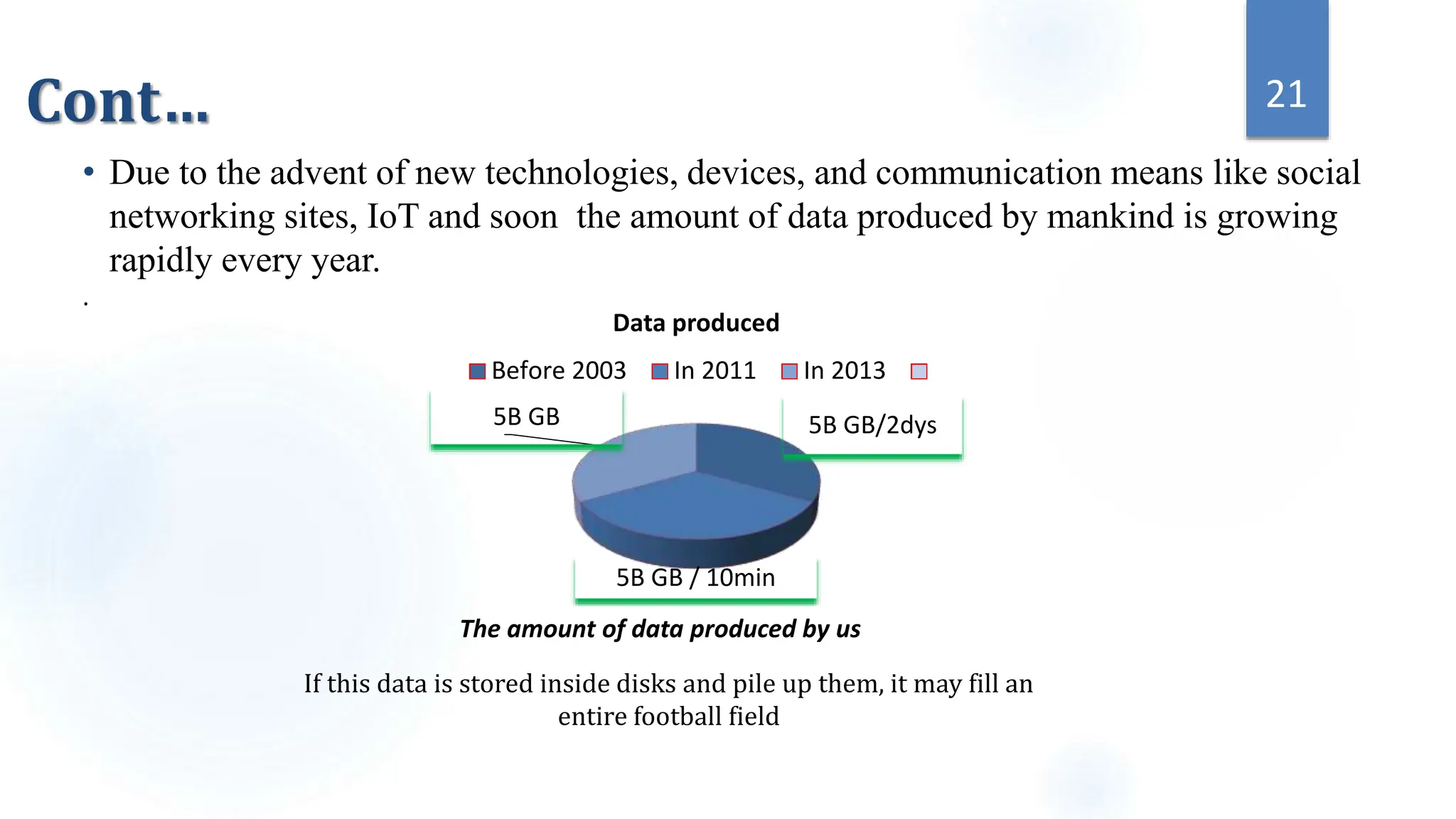
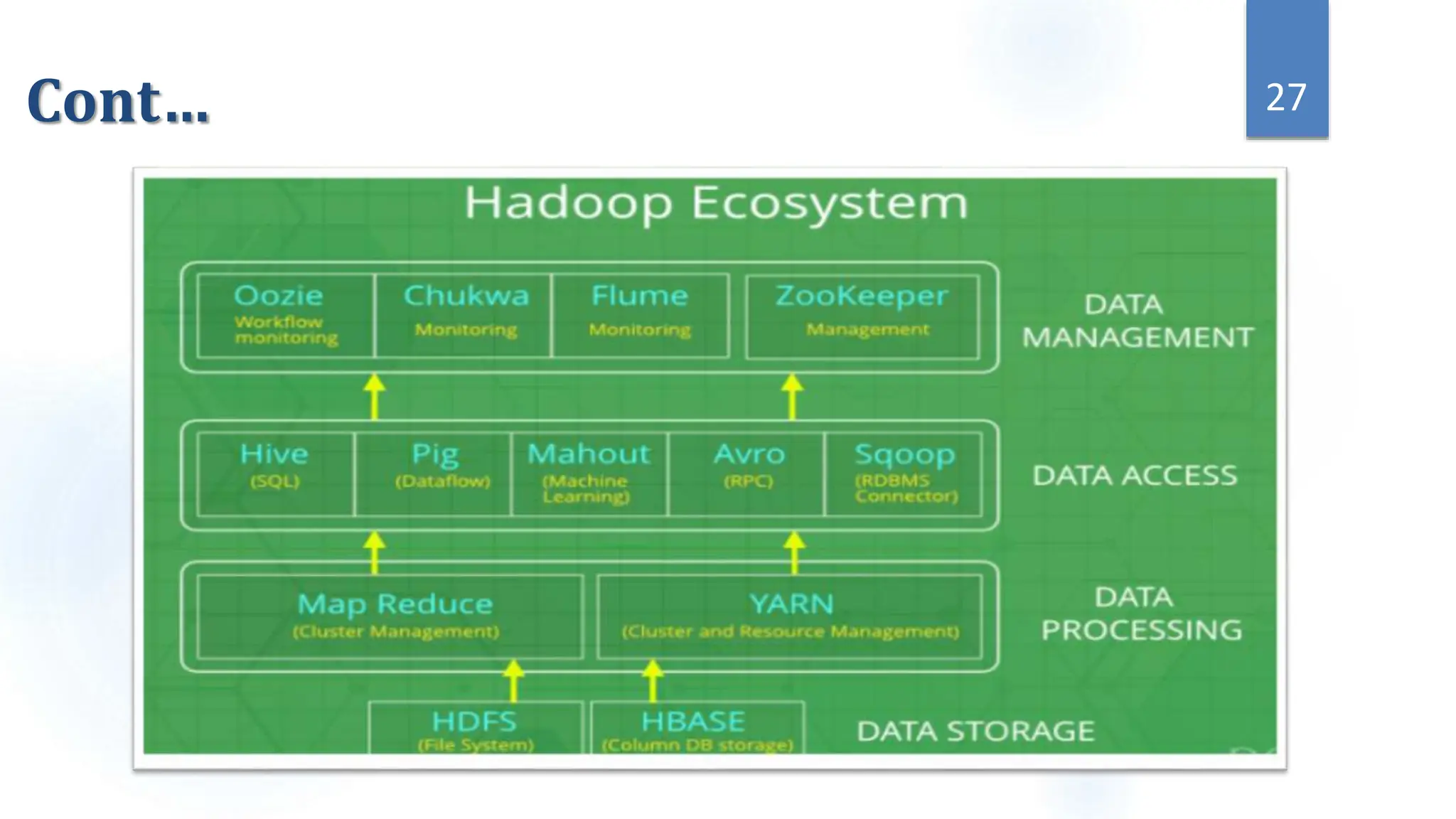
This document provides an overview of data science and its key components. It discusses that data science uses scientific methods and algorithms to extract knowledge from structured, semi-structured, and unstructured data sources. It also notes that data science involves organizing data, packaging it through visualization and statistics, and delivering insights. The document further outlines the data science lifecycle and workflow, covering understanding the problem, exploring and preprocessing data, developing models, and evaluating results.










































![Chapter 2 - Intro to Data Sciences[2].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/chapter2-introtodatasciences2-230326001432-ec8e4032-thumbnail.jpg?width=640&height=640&fit=bounds)



































