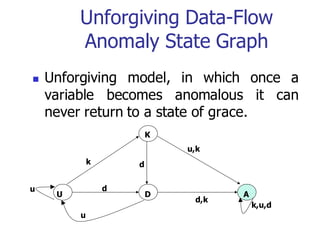
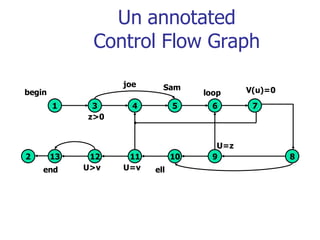
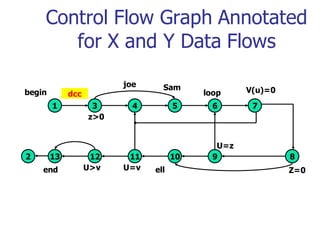
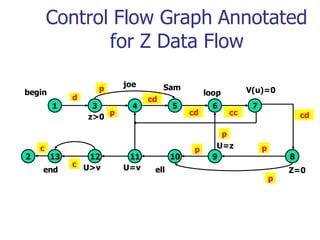
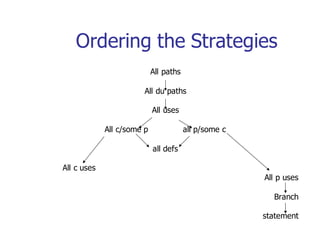
This document discusses data flow testing, which is a type of structural testing based on selecting test paths to ensure that all data objects are initialized before use and all defined objects are used. It describes the basic concepts of data flow testing including data flow graphs, data object states, and data flow anomalies. It also discusses the differences between static and dynamic anomaly detection and provides examples of annotated control flow graphs and data flow testing strategies.