Downloaded 24 times





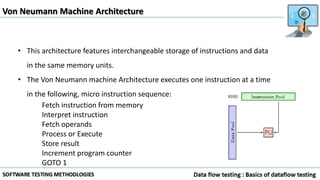
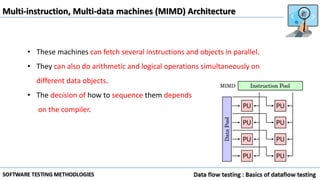

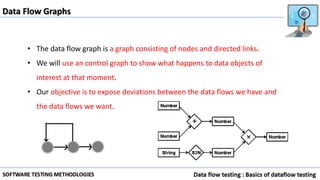
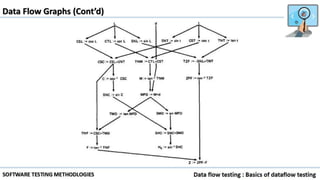










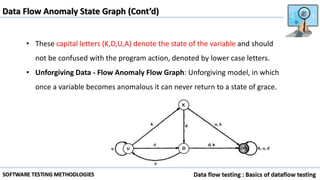

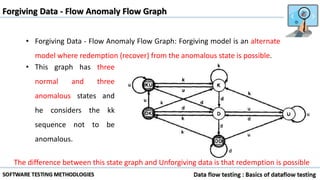













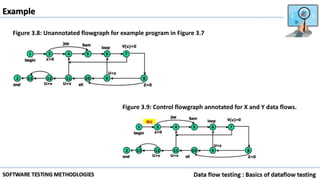
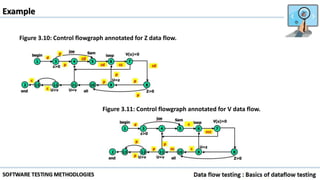


Data flow testing uses a program's control flow graph annotated with symbols like d, k, u to track the state of variables and identify anomalies. Static analysis can detect some anomalies but is insufficient on its own due to limitations in analyzing dynamic features like pointers, concurrency, and interrupts. The data flow model represents each statement as a node and links are weighted with sequences of symbols showing variable states to identify anomalies like ku that indicate bugs.




























































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)






