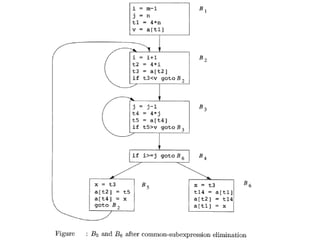
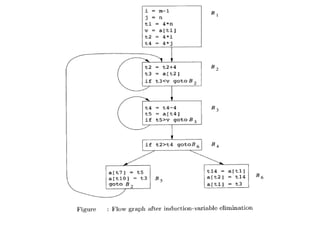
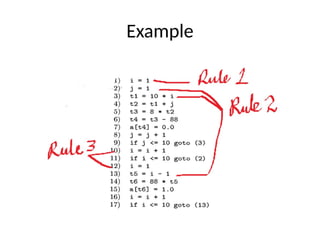
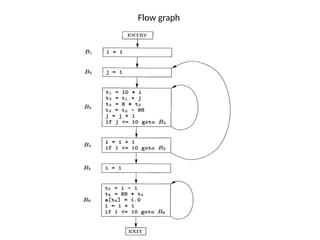
The document discusses machine-independent optimization techniques in programming, focusing on code improvement through local and global optimizations, including eliminating unnecessary instructions and applying transformations like copy propagation and dead code elimination. It introduces data flow analysis and the use of flow graphs to represent control structures and optimize code execution paths. Key concepts like reaching definitions, live variable analysis, and available expressions are illustrated with examples to demonstrate their importance in enhancing program efficiency.



























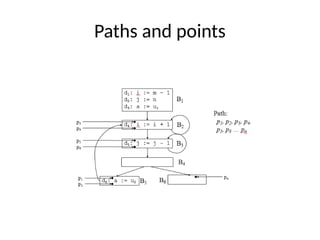
![Data Flow analysis schema
• Every program point is associated with the data flow value that
represents the abstraction of the set of all possible program
states that can be observed for that point.
• The set of all possible data flow values is the domain for this
application.
• We can denote the data flow values before and after each
statement s by IN[s] and OUT[s].
• The data flow problem is to find a solution to set of constraints:
• 1) those based on semantics of he statements(transfer
functions)
• 2) based on flow of control](https://image.slidesharecdn.com/unit-5-240806111216-5e5a777c/85/Machine_Learning_JNTUH_R18_UNIT5_CONCEPTS-pptx-33-320.jpg)

![Control Flow Constraints
• The second set of constraints on data-flow
values is derived from the flow of control.
Within a basic block, control flow is simple. If a
block B consists of statements S1,S2…..Sn in
that order, then the control-flow value out of
Si; is the same as the control-flow value into
Si+1. That is,
IN[Si+1] = OUT[Si] for all = 1,2,.](https://image.slidesharecdn.com/unit-5-240806111216-5e5a777c/85/Machine_Learning_JNTUH_R18_UNIT5_CONCEPTS-pptx-35-320.jpg)
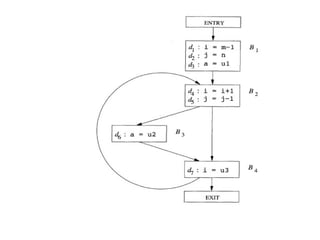
![DATA FLOW SCHEMES ON BASIC BLOCKS
• Control flows from the beginning to the end of the block,
without interruption or branching.
• Thus, we can restate the schema in terms of data-flow
values entering and leaving the blocks.
• We denote the data-flow values immediately before and
immediately after each basic block B by IN[B] and OUT[B],
respectively.
• The constraints involving IN[B] and OUT[B] can be derived
from those involving IN[s] and OUT[s] for the various
statements, sin B as follows.](https://image.slidesharecdn.com/unit-5-240806111216-5e5a777c/85/Machine_Learning_JNTUH_R18_UNIT5_CONCEPTS-pptx-36-320.jpg)










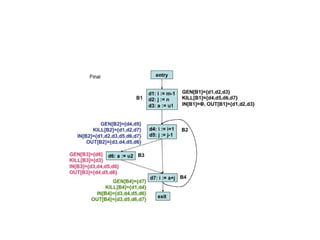

![We first define the transfer functions of individual
statements and then we compute IN[B] and
OUT[B].](https://image.slidesharecdn.com/unit-5-240806111216-5e5a777c/85/Machine_Learning_JNTUH_R18_UNIT5_CONCEPTS-pptx-49-320.jpg)











![• For each block B, let IN{B] be the set of expressions in U
that are available at the point just before the beginning
of B.
• Let OUT[B] be the same for the point following the end
of B.
• Define e.gens to be the expressions generated by B and
e.killp to be the set of expressions in U killed in B.
• Note that IN, OUT, e-gen, and kill can all be represented
by bit vectors.
• The following equations relate the unknowns IN and OUT
to each other and the known quantities egen and e kill:](https://image.slidesharecdn.com/unit-5-240806111216-5e5a777c/85/Machine_Learning_JNTUH_R18_UNIT5_CONCEPTS-pptx-62-320.jpg)
























































