Downloaded 546 times





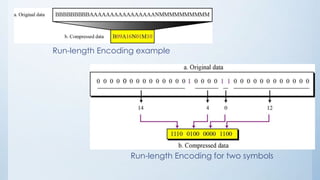

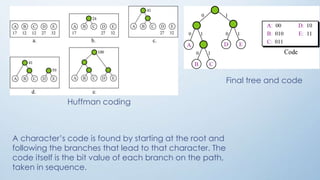


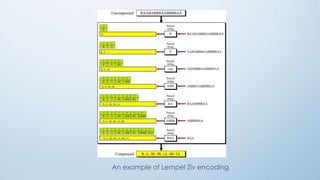





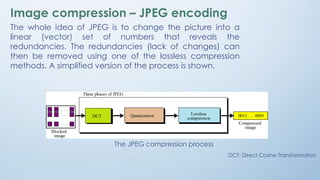




The document provides an overview of data compression, categorizing it into lossless and lossy methods. Lossless compression techniques, such as run-length encoding, Huffman coding, and Lempel-Ziv encoding, allow for perfect reconstruction of original data, while lossy compression methods, like JPEG, MPEG, and MP3, sacrifice some data fidelity for reduced file sizes. Key concepts like data redundancy, the uses of different encoding techniques, and the importance of choosing the right method depending on data integrity requirements are also discussed.






























































































