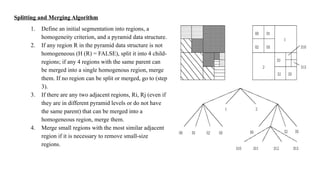
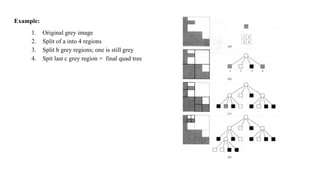
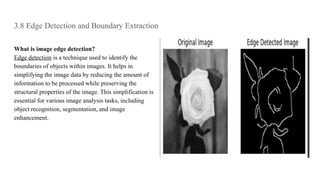
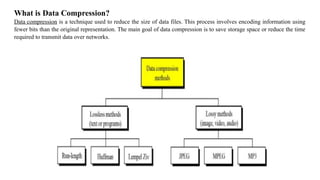
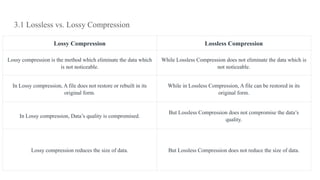
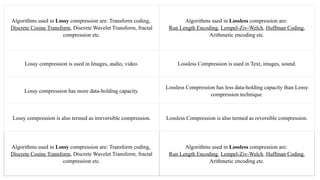
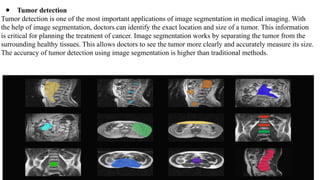
This document discusses image compression and segmentation, highlighting the differences between lossless and lossy compression methods. It explains various compression techniques such as run-length encoding, Huffman coding, and transform coding, as well as the importance of image segmentation in computer vision applications like medical imaging and autonomous vehicles. Key considerations for evaluating compression techniques include compression ratio, speed, and output quality.
























![Thresholding Techniques in Computer Vision
1. Simple Thresholding
Simple thresholding uses a single threshold value to classify pixel intensities. If a pixel's intensity is greater than the
threshold, it is set to 255 (white); otherwise, it is set to 0 (black).
[Tex]begin{equation} T(x, y) = begin{cases} 0 & text{if } I(x, y) leq T 255 & text{if } I(x, y) > T end{cases}
end{equation} [/Tex]
In this formula:
● I(x,y) is the intensity of the pixel at coordinates (x, y).
● T is the threshold value.
● If the pixel intensity I(x,y) is less than or equal to the threshold T, the output pixel value is set to 0 (black).
● If the pixel intensity I(x,y) is greater than the threshold T, the output pixel value is set to 255 (white).
Pros of Simple Thresholding
● Simple and easy to implement.
● Computationally efficient.
Cons of Simple Thresholding
● Ineffective for images with varying lighting conditions.
● Requires manual selection of the threshold value.](https://image.slidesharecdn.com/unit3imagecompressionandsegmentation-241221110313-2a6ce454/85/Unit-3-Image-Compression-and-Segmentation-pptx-28-320.jpg)