Downloaded 40 times




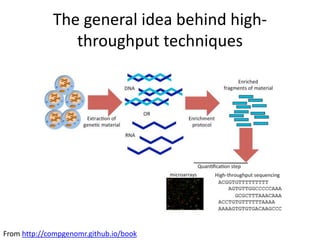

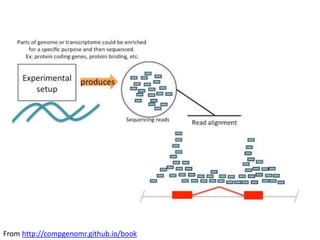


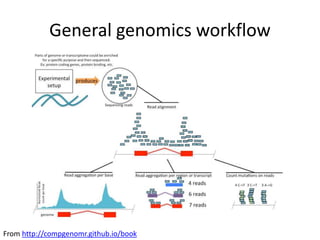
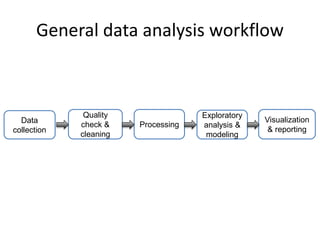





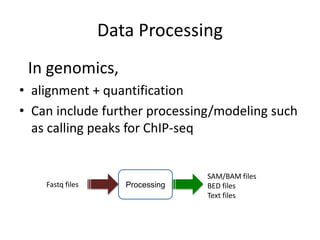











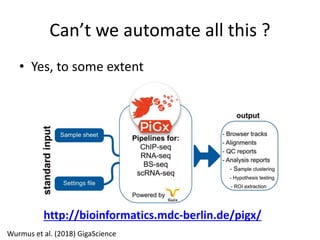

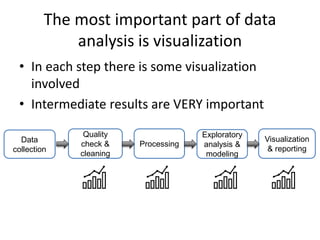






















This document provides an overview of common data analysis patterns, tools, and data types used in genomics. It discusses the general genomics workflow, which includes data collection, quality checking and cleaning, processing, exploratory analysis and modeling, and visualization and reporting. For each step, examples of relevant tools and file formats used in genomics are provided. The document emphasizes that visualization and exploration of data is an important part of analysis. It provides advice for getting started with learning bioinformatics, including using programming languages like R and Galaxy, getting help from others, and not worrying about perfection initially.














































































