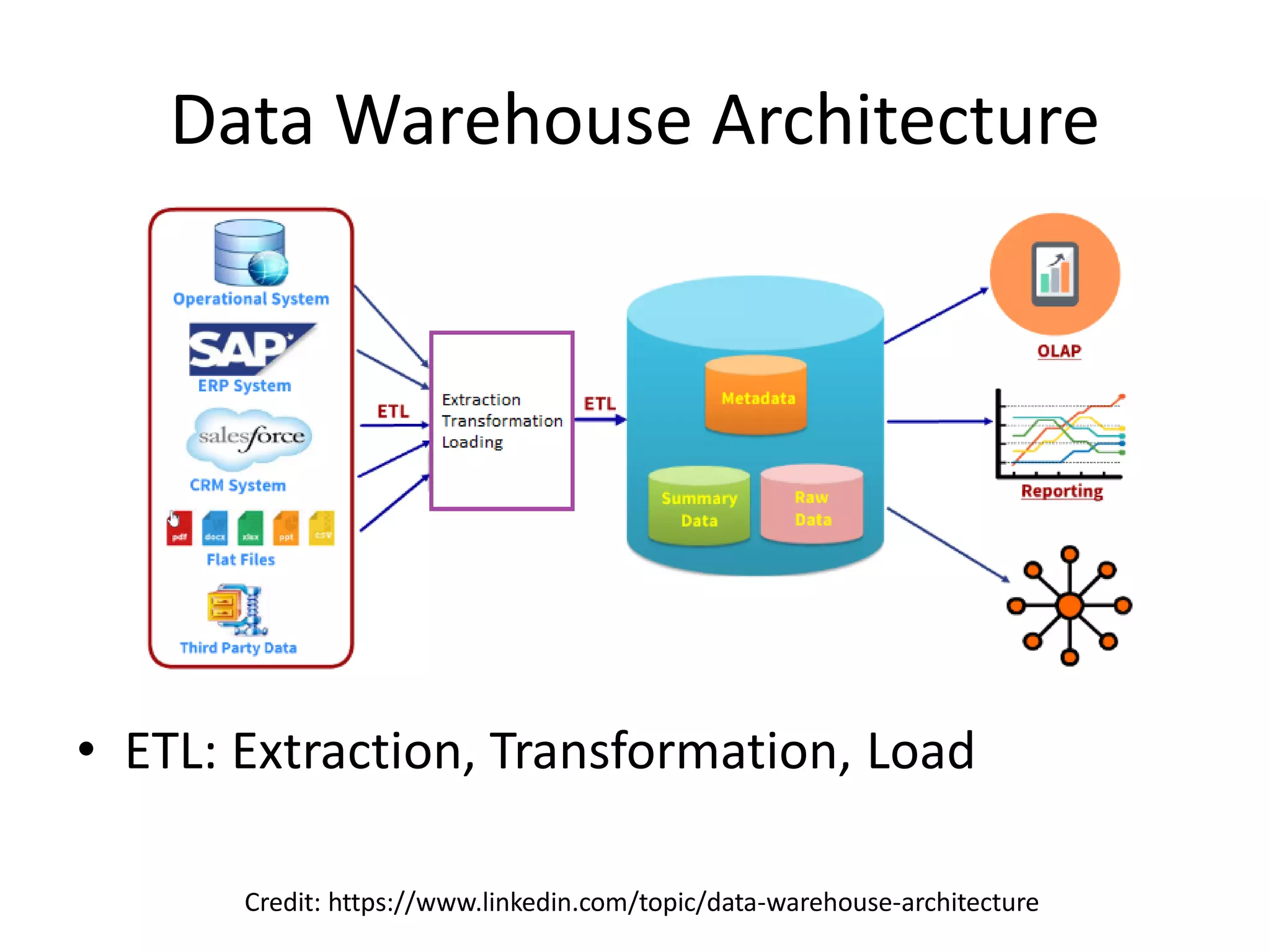
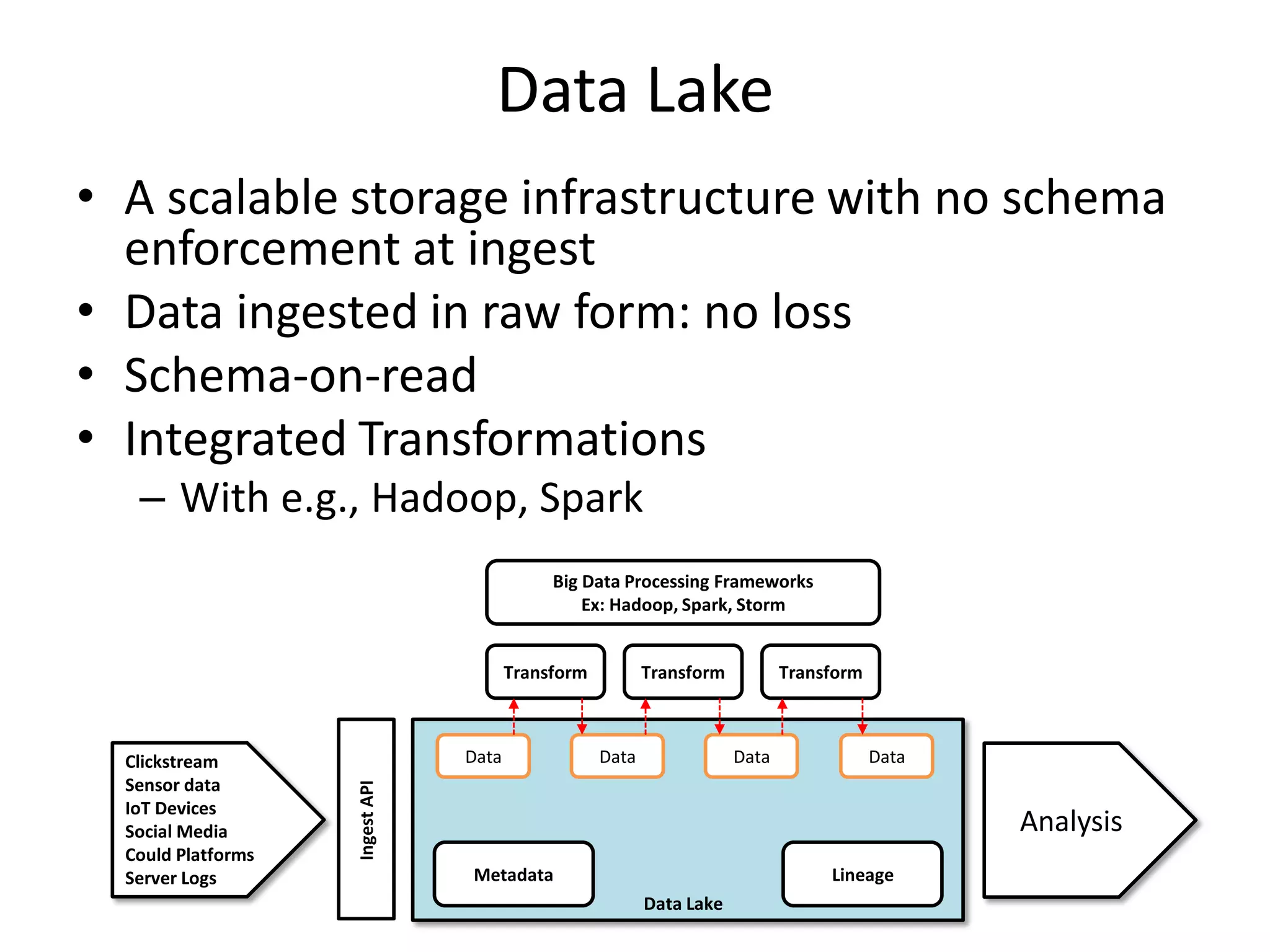
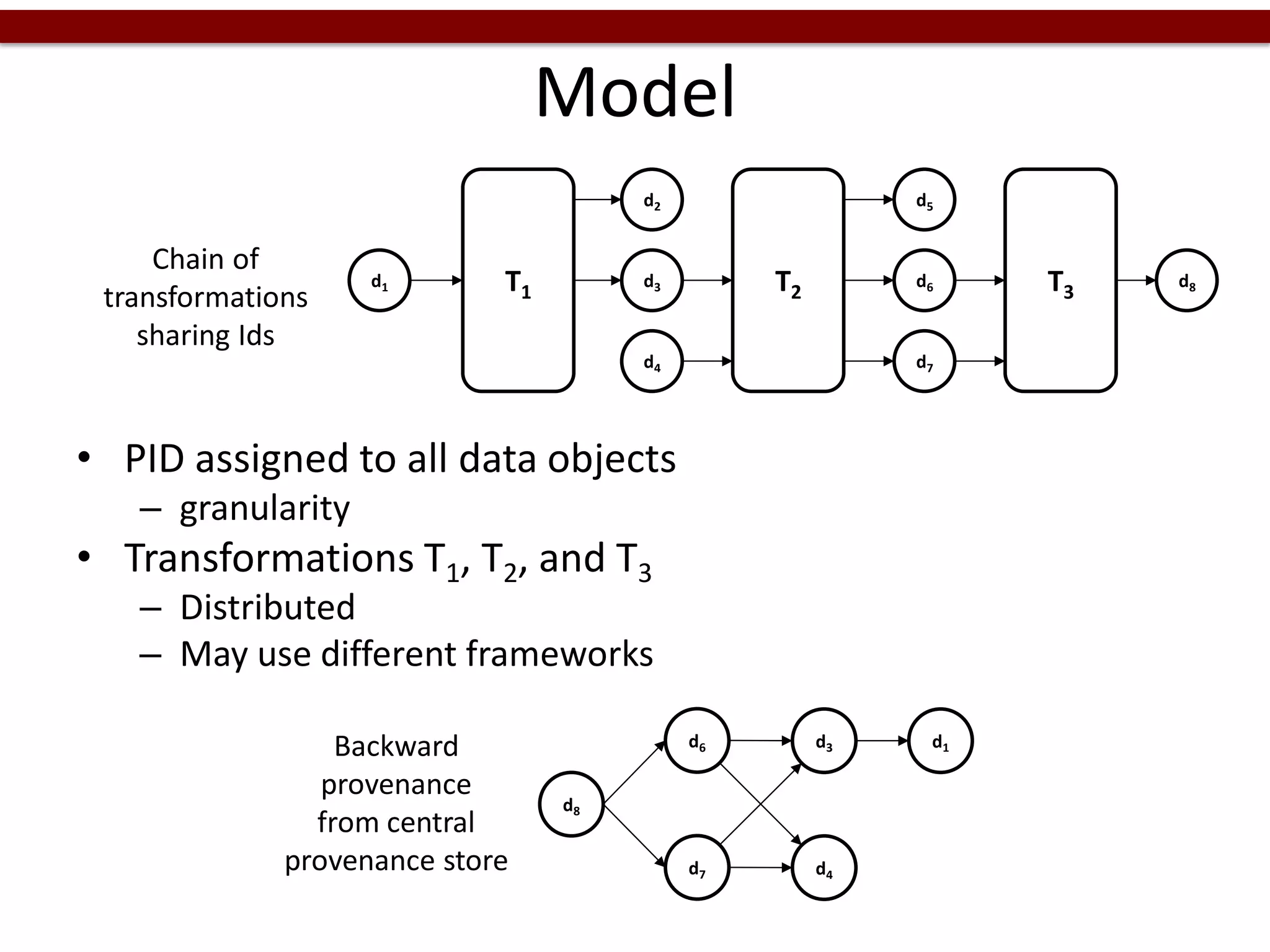
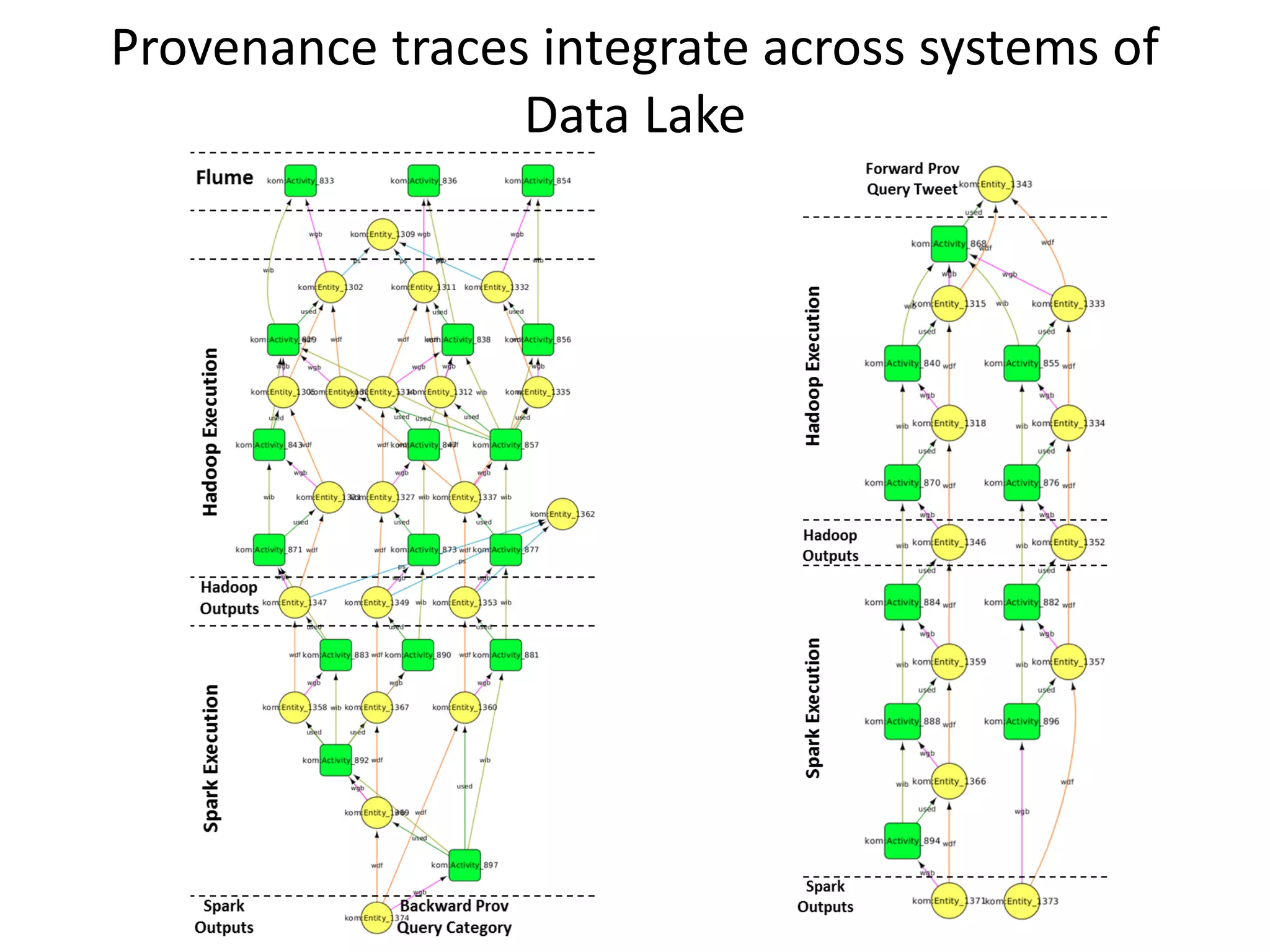
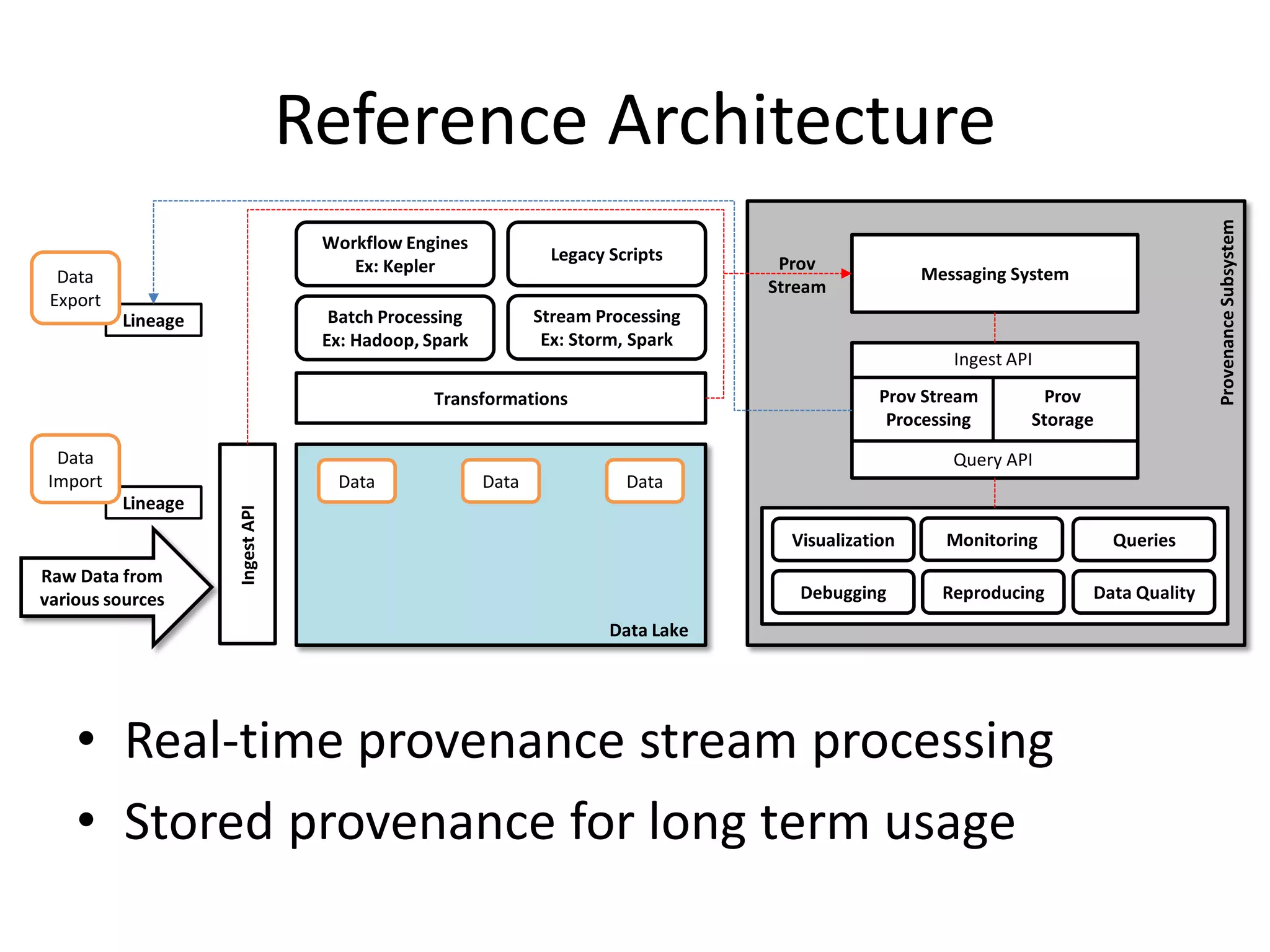
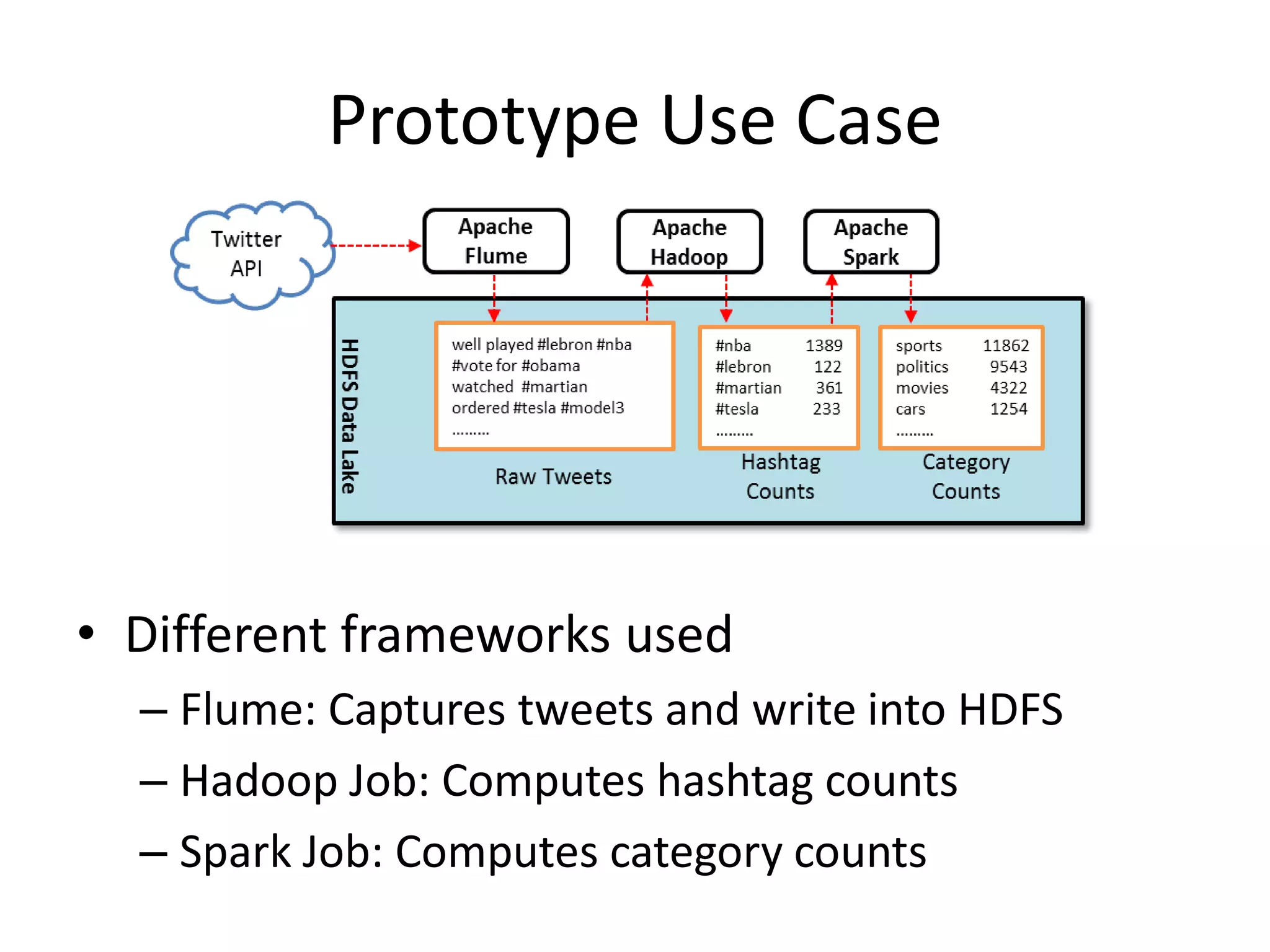
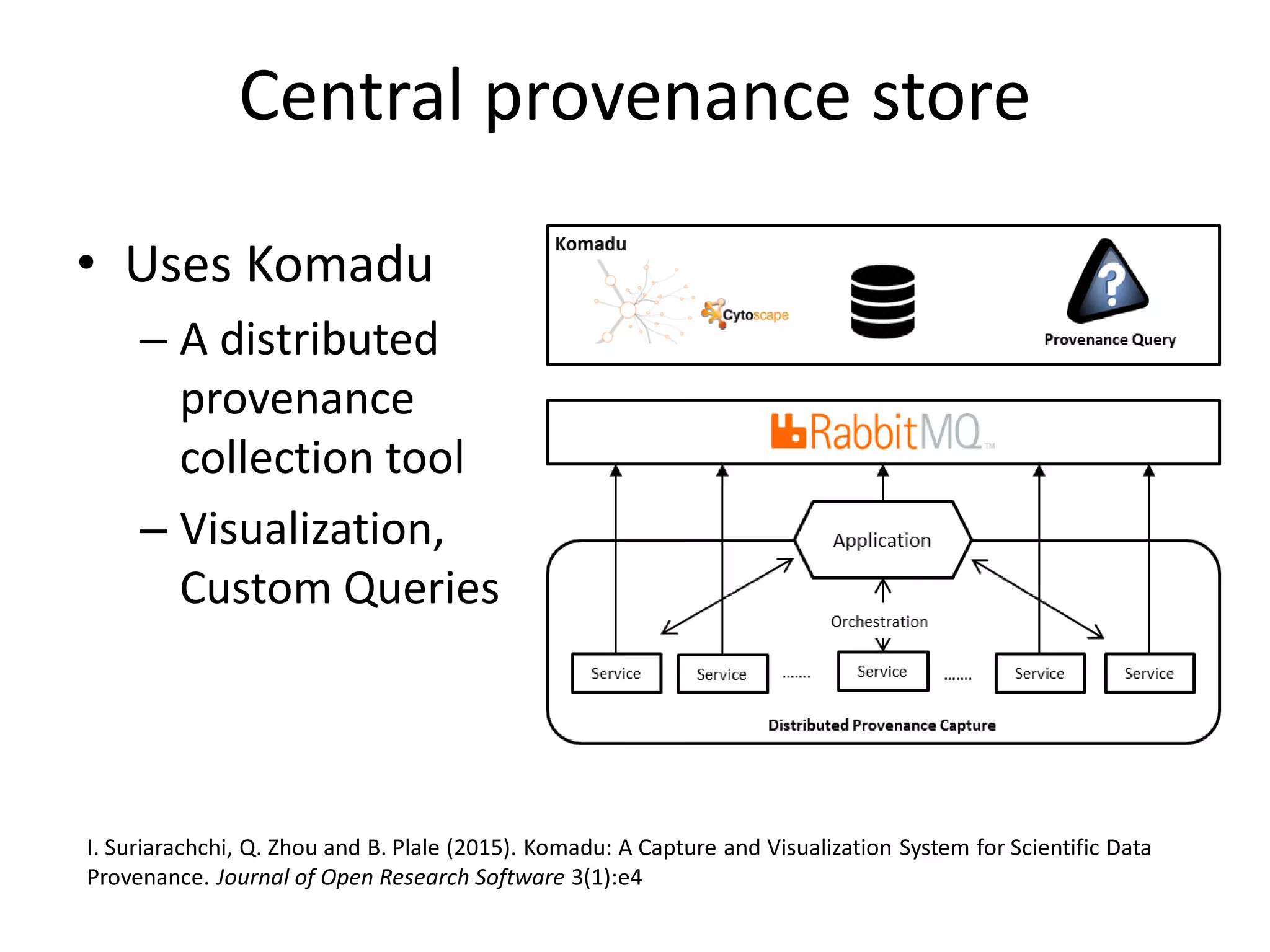
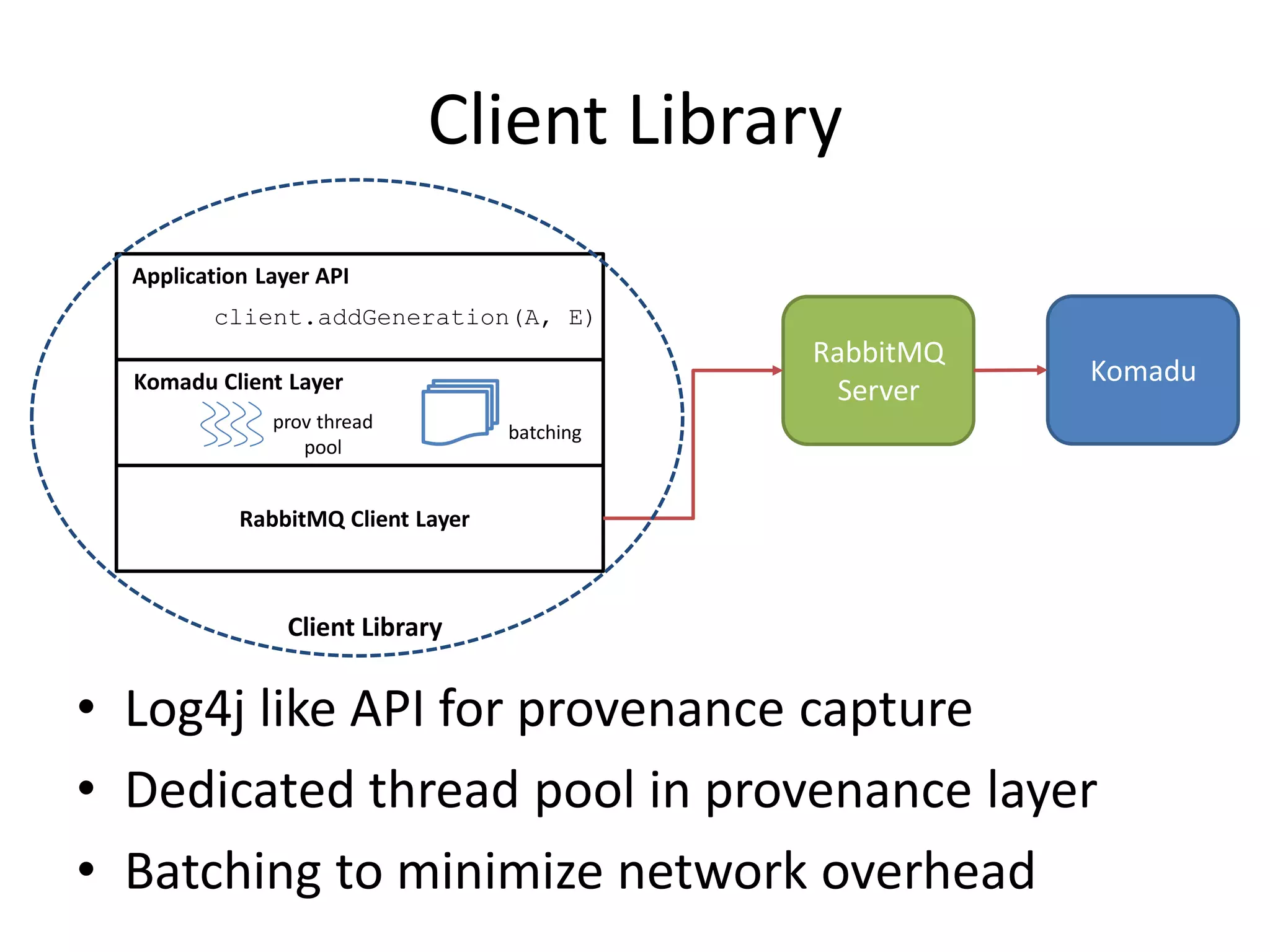
The document discusses the need for integrated provenance in data lakes to ensure effective management and traceability of varied data types. It highlights challenges posed by the flexibility of data lakes, such as increased difficulty in manageability and the concept of 'data swamps.' The authors propose a system for capturing provenance across different analytics frameworks to enhance data traceability and ensure reliable data processing within the data lake environment.


























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












