Download as PDF, PPTX



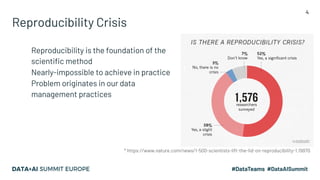












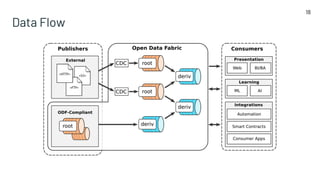

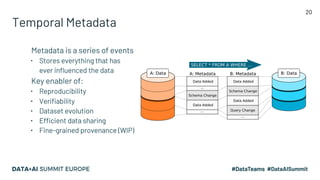
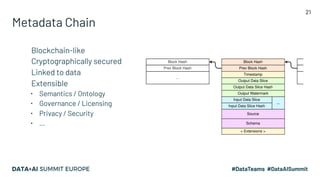

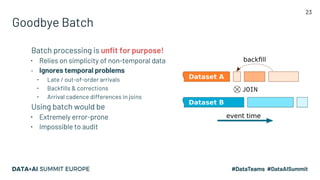
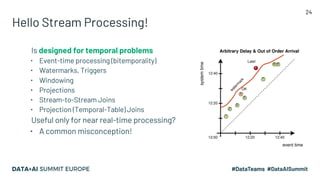

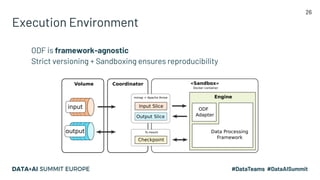


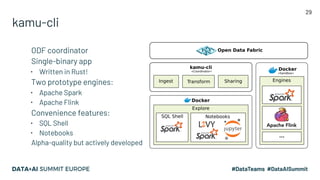






The document discusses the challenges of data management and reproducibility in scientific research, highlighting issues exemplified by the retraction of a hydroxychloroquine study due to data inconsistencies. It advocates for a new data supply chain protocol, Open Data Fabric, to enhance reproducibility and transparency in data handling through a framework-agnostic, stream processing approach. The author calls for a paradigm shift in how data is treated, emphasizing the need for strict ownership of data validity and the adoption of temporal data models.























































































