Download to read offline





































![@nicolas_frankel
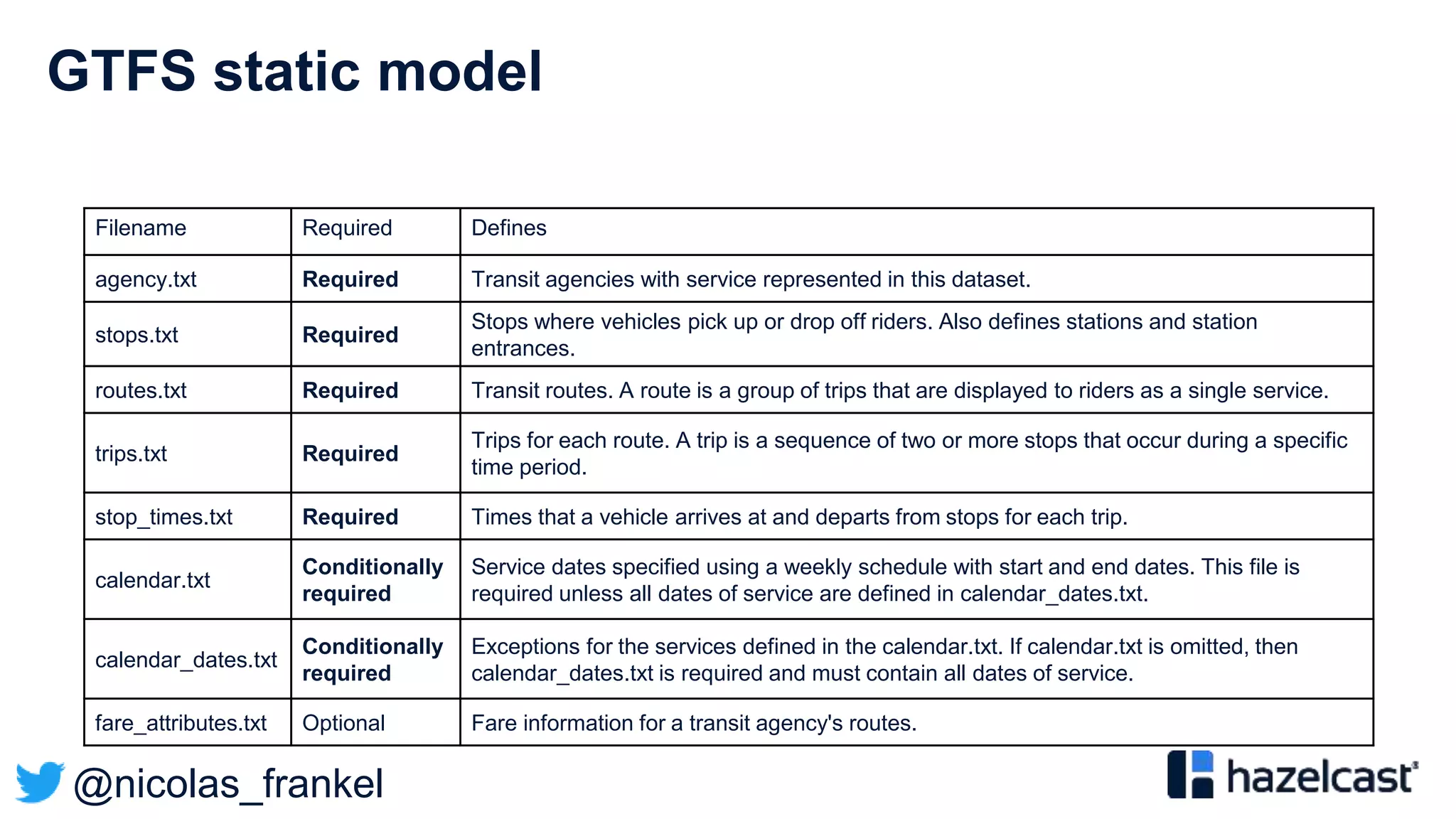
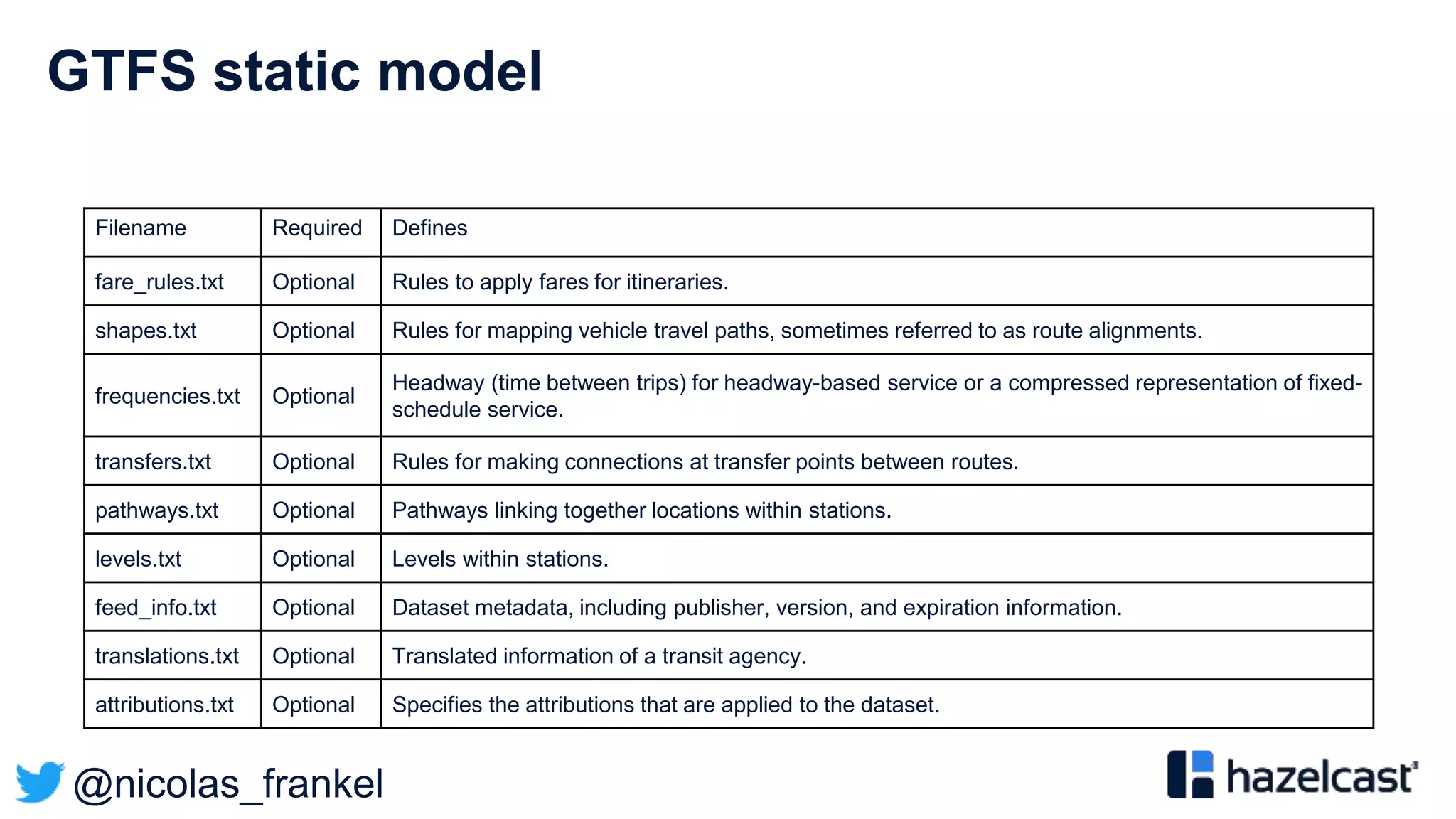
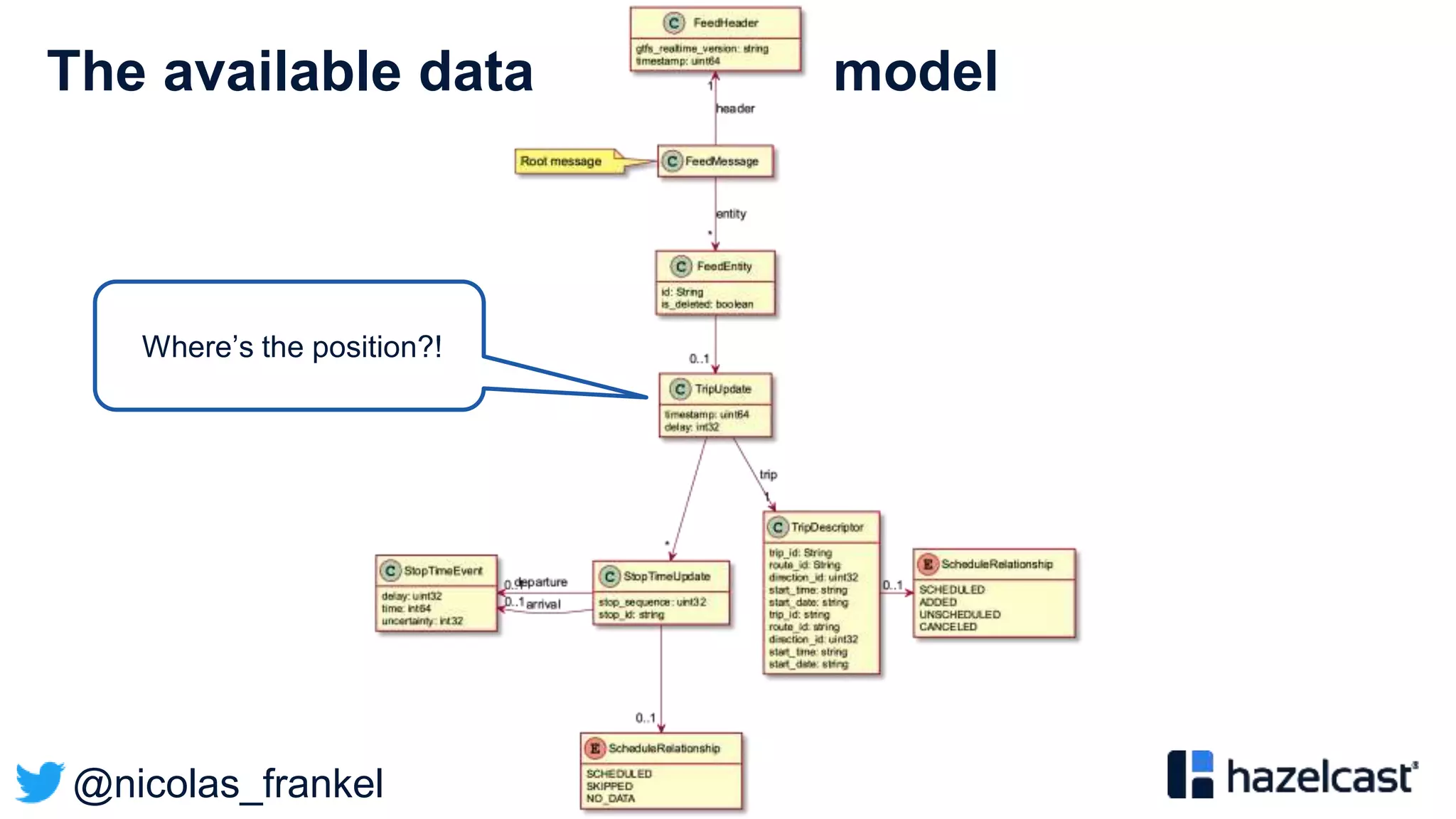
General Transit Feed Specification
”The General Transit Feed Specification (GTFS) […] defines a
common format for public transportation schedules and
associated geographic information. GTFS feeds let public
transit agencies publish their transit data and developers write
applications that consume that data in an interoperable way.”](https://image.slidesharecdn.com/vjug-introductiontodatastreaming-200521171905/75/vJUG-Introduction-to-data-streaming-43-2048.jpg)
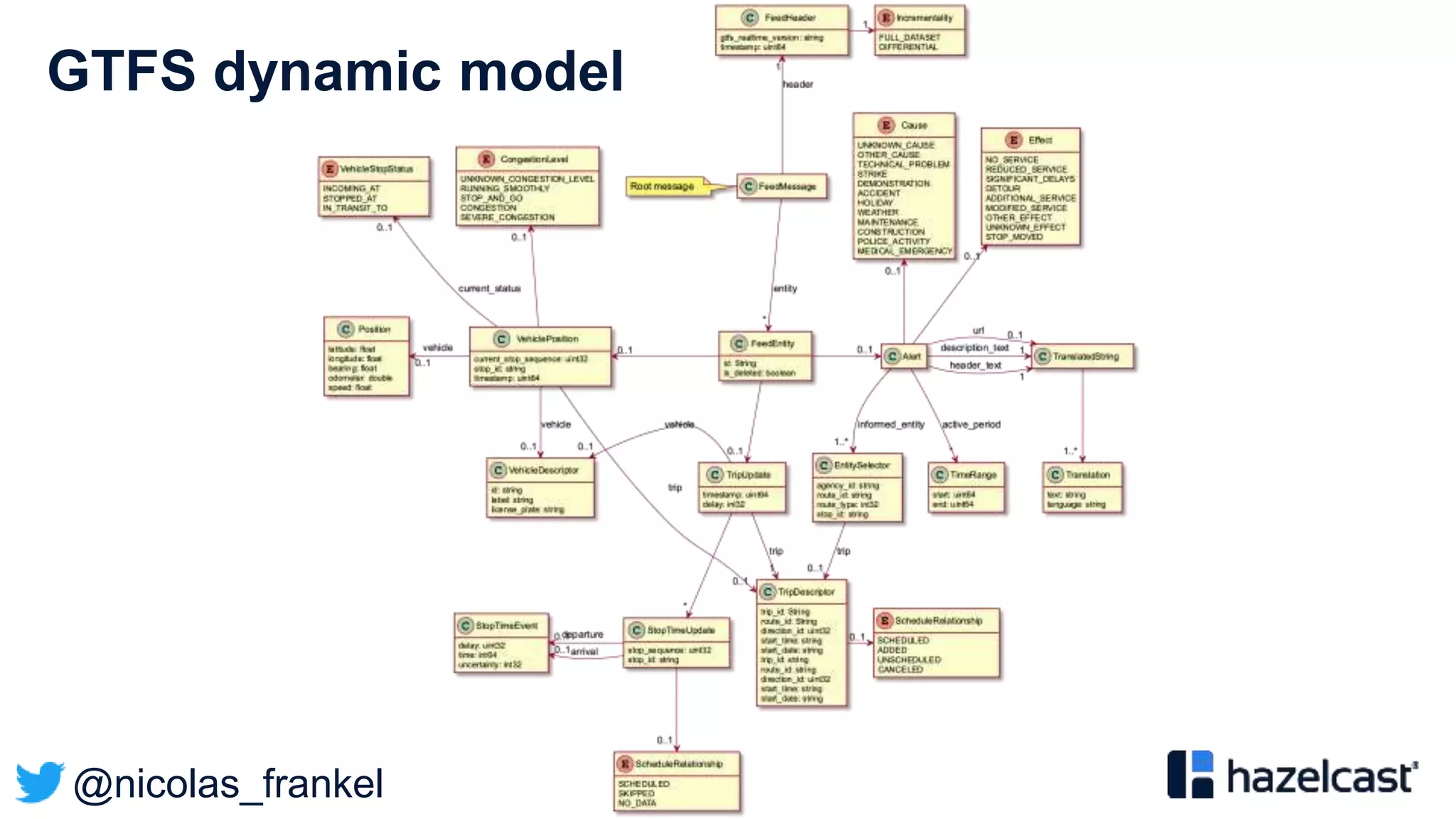


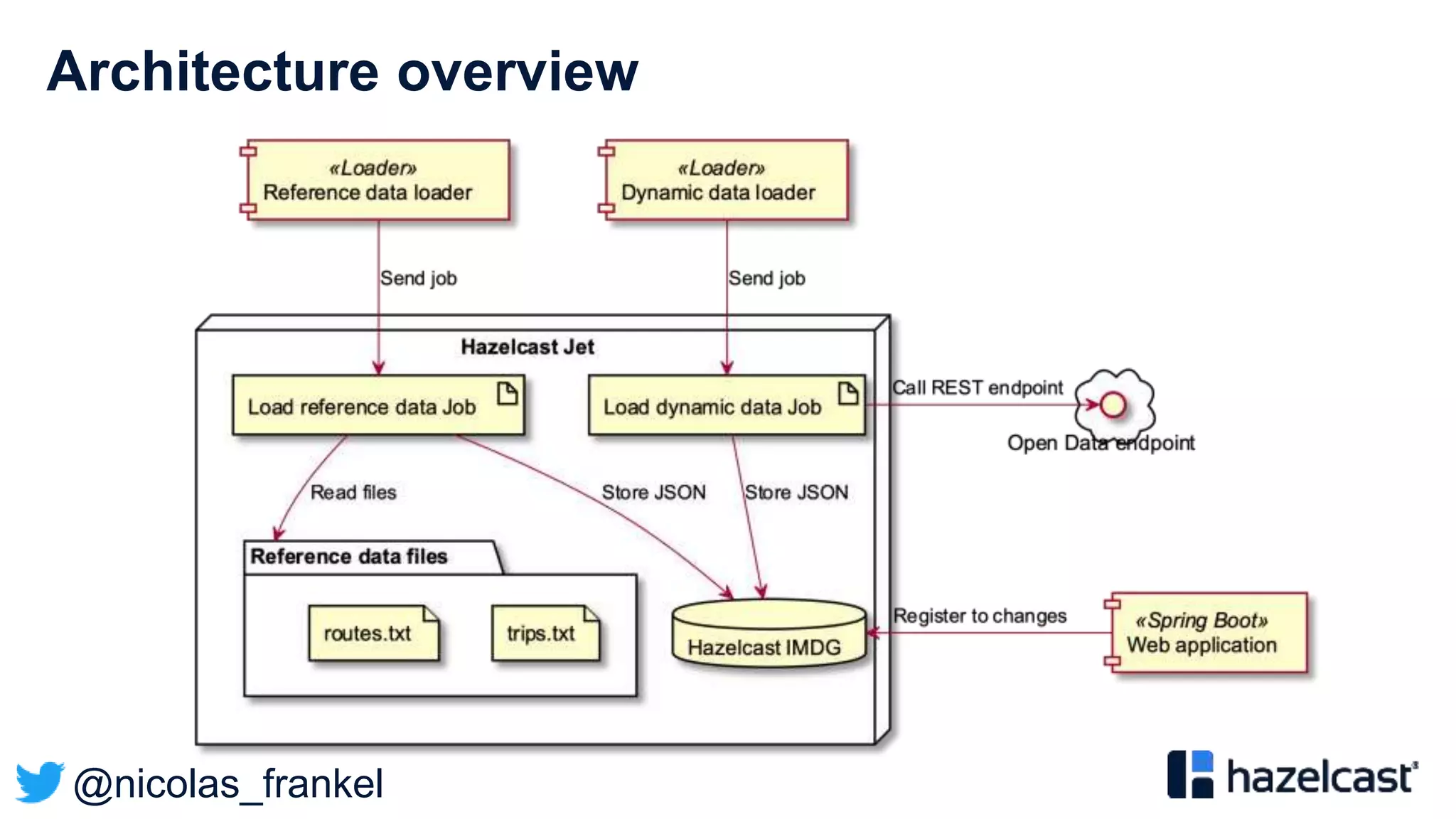




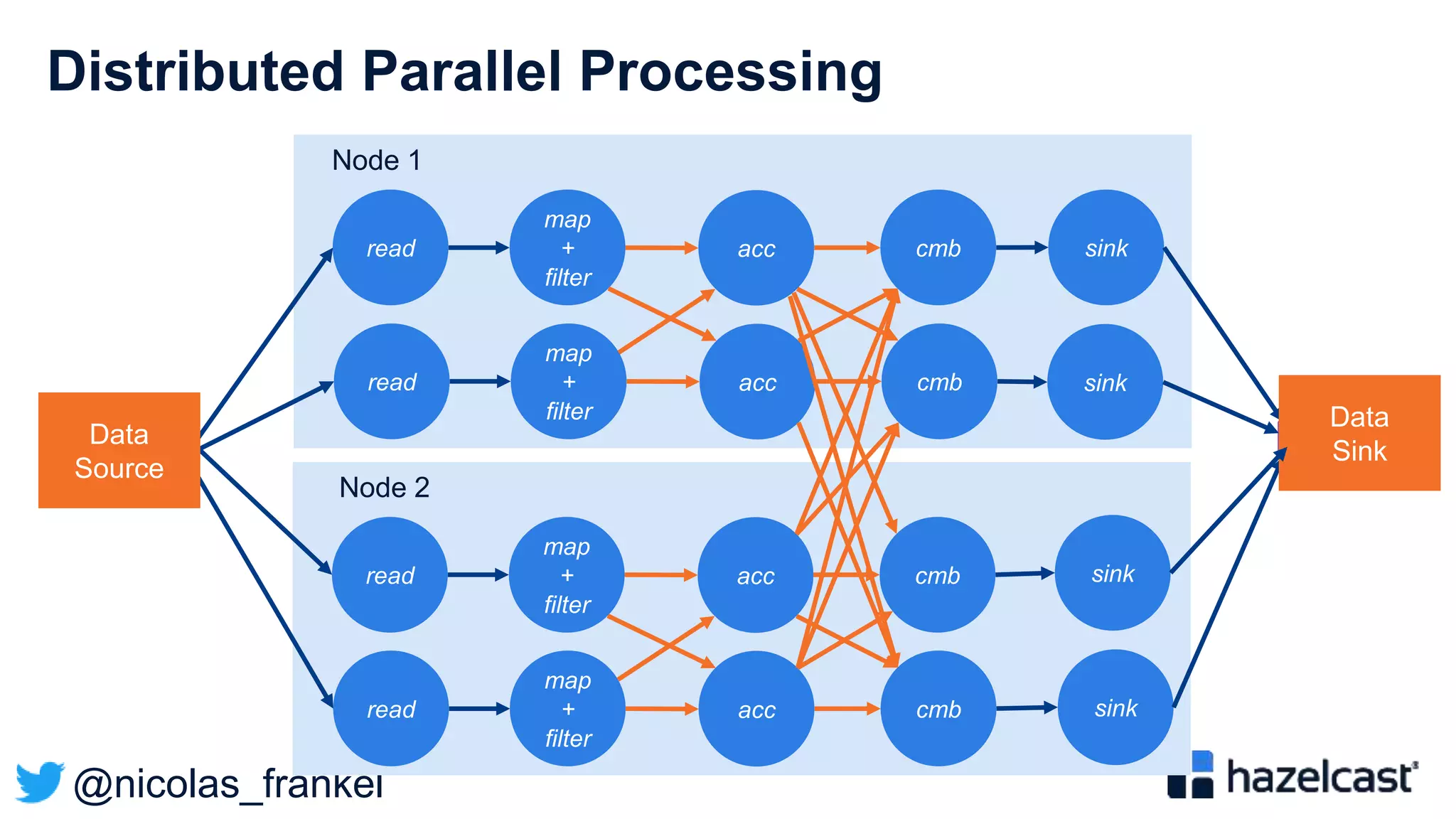
The document discusses stream processing and provides an overview of Hazelcast Jet. It begins with explaining why streaming is useful and describes different streaming approaches like event-driven programming. It then provides details on Hazelcast Jet, including its concepts of pipelines and jobs. The document also discusses open data standards like GTFS and demonstrates a sample streaming pipeline that enriches public transportation data from open APIs.








































![[NYJavaSig] Riding the Distributed Streams - Feb 2nd, 2017](https://cdn.slidesharecdn.com/ss_thumbnails/ridingdistributedstreams-nyjavasig-02-02-2017-170203005616-thumbnail.jpg?width=640&height=640&fit=bounds)














































