Download to read offline


![9
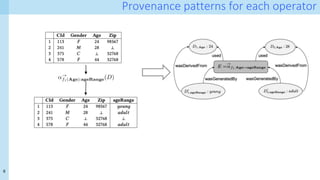
Making your code provenance-aware
df = pd.DataFrame(…)
# Create a new provenance document
p = pr.Provenance(df, savepath)
# create provanance tracker
tracker=ProvenanceTracker.ProvenanceTracker(df, p)
# instance generation
tracker.df = tracker.df.append({'key2': 'K4'},
ignore_index=True)
# imputation
tracker.df = tracker.df.fillna('imputato')
# feature transformation of column D
tracker.df['D'] = tracker.df['D']*2
# Feature transformation of column key2
tracker.df['key2'] = tracker.df['key2']*2
Approach:
A python tracker object intercepts dataframe
operations
Operations that are channeled through the tracker
generate provenance fragments](https://image.slidesharecdn.com/research-223-vldb-talk-clean-211016121718/85/Capturing-and-querying-fine-grained-provenance-of-preprocessing-pipelines-in-data-science-DP4DS-9-320.jpg)
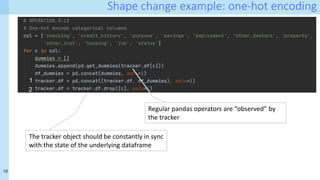
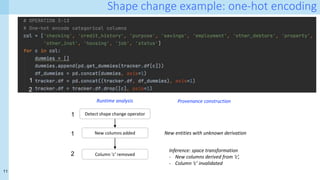
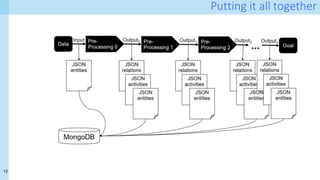
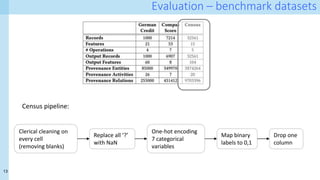
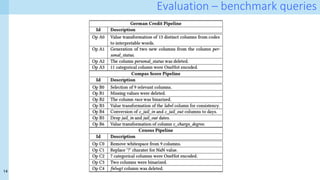
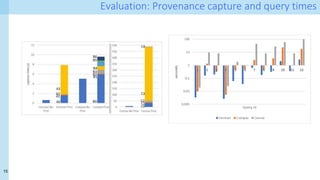
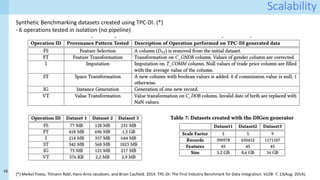
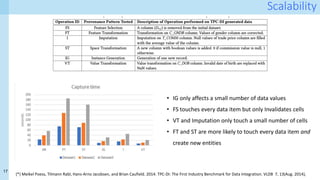


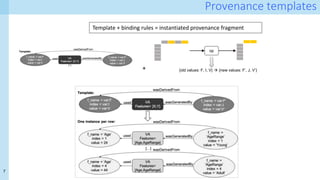
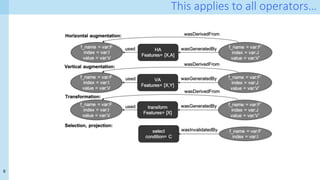
The document discusses a method for capturing and querying fine-grained provenance in data science preprocessing pipelines, highlighting the importance of tracking the effects of various operations on data. It outlines the implementation of a provenance tracker in Python that monitors DataFrame operations, generating provenance fragments that detail how data transformations affect data shape and integrity. The evaluation includes scalability tests and considerations for extending this approach to arbitrary Python and pandas programs.








































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)












