The document discusses machine learning algorithms with a focus on k-nearest neighbors (KNN), a non-parametric and lazy supervised algorithm that classifies data points based on the majority voting from their nearest neighbors. It explains the principles of KNN, how to determine the value of k, the importance of distance metrics, and the algorithm's applications in various fields such as banking and politics. KNN is noted for its high accuracy for small datasets but has challenges related to computational expense and sensitivity to data scale.







![ Let m be the number of training data samples. Let p
be an unknown point.
Store the training samples in an array of data points
arr[]. This means each element of this array
represents a tuple (x, y).
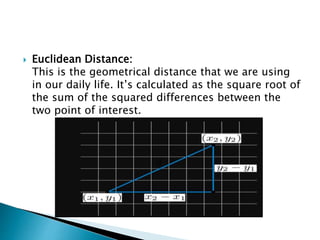
for i=0 to m: Calculate Euclidean distance d(arr[i], p).
Make set S of K smallest distances obtained. Each of
these distances correspond to an already classified
data point.
Return the majority label among S.](https://image.slidesharecdn.com/knnclassifierintroductiontok-nearestneighboralgorithm-240530191932-9f3ec240/85/KNN-CLASSIFIER-INTRODUCTION-TO-K-NEAREST-NEIGHBOR-ALGORITHM-pptx-8-320.jpg)
![ Let m be the number of training data
samples. Let p be an unknown point.
Store the training samples in an array of data
points arr[]. This means each element of this
array represents a tuple (x, y).
for i=0 to m: Calculate Euclidean distance
d(arr[i], p).
Make set S of K smallest distances obtained.
Each of these distances corresponds to an
already classified data point.
Return the majority label among S.](https://image.slidesharecdn.com/knnclassifierintroductiontok-nearestneighboralgorithm-240530191932-9f3ec240/85/KNN-CLASSIFIER-INTRODUCTION-TO-K-NEAREST-NEIGHBOR-ALGORITHM-pptx-9-320.jpg)