KNN algorithm
TheK-Nearest Neighbors (KNN) algorithm is a supervised machine
learning algorithm for classification and regression
It can be used to solve classification and regression problems.
The output depends on whether k-nearest neighbors are used for
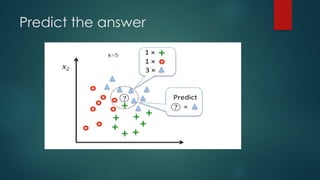
classification or regression. The main idea behind K-NN is to find the K
nearest data points, or neighbors, to a given data point and then
predict the label or value of the given data point based on the labels or
values of its K nearest neighbors.
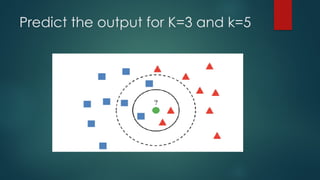
K can be any positive integer, but in practice, K is often small
Key aspects ofK-nearest neighbour's
In the k-nearest neighbor’s classification, the output is a class
membership. An object is classified by a majority vote of its
neighbors, with the object being assigned to the class most
common among its k nearest neighbors (k is a positive integer,
typically small). If k = 1, then the object is simply assigned to
the class of that single nearest neighbor.
In the K-nearest neighbors regression, the output is the property
value for the object. This value is the average of the values of its
k nearest neighbors.
7.
K-nearest neighboris a non-parametric method, which means
that it does not make any assumptions about the underlying
data.
This is advantageous over parametric methods, which do make
such assumptions. The models don’t learn parameters from the
training data set to come up with a discriminative function in
order to classify the test or unseen data set

























![k-nearestneighborknn-231215171119-a5cfb915.pptx [Read-Only].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/k-nearestneighborknn-231215171119-a5cfb915-251010013925-09814a4b-thumbnail.jpg?width=640&height=640&fit=bounds)





















![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)












![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)

