The document discusses challenges related to parallel processing and massive parallel architectures. It covers topics like pipeline processors, multiprocessors, processing in memory architectures like Cyclops and picoChip, and cellular architectures. It also discusses code generation issues that arise from massive parallelism and possible solutions using compilers or libraries.




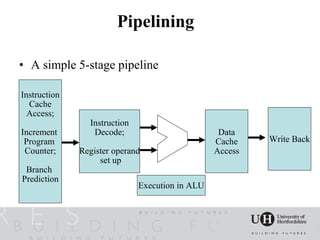

![Pipelining hazards
Data, Control, Structural
• Data hazards
– Read After Write (RAW dependency)
• The result of an operation is required as an operand of a
subsequent operation and that result is not yet available in the
register file
add $1,$2,$3 //$1=$2+$3
addi $4,$1,8 //$4=$1+8 data dependency ($1 is unavailable)
sub $5,$2,$1 //$5=$2-$1 data dependency ($1 is unavailable)
ld $6,8($1) //$6=Mem[$1+8]... $1 may be available
add $7,$6,$8 //load-use dependency...data dependency ($6 is
unavailable)](https://image.slidesharecdn.com/acculdneganmcguinessfullv10-12583249204515-phpapp02/85/The-Challenges-facing-Libraries-and-Imperative-Languages-from-Massively-Parallel-Architectures-7-320.jpg)


































































































![[Harvard CS264] 01 - Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201101-introductionshare-110206153841-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















