Downloaded 77 times




![softmaxfunction
[0.34, 0.57, 0.09]
predicted class: 1
correct class: 0
np.argmax
logits prediction
𝒇
hidden
layer
input
layer
output
layer
𝑊
activation
function
bias units
4-5-3 Neural Net Architecture
[17.0, 28.5, 4.50]
𝒇
𝒇
𝒇
𝒇
𝒇
𝒇
𝒇
𝒇
𝒇
𝒇
𝒇](https://image.slidesharecdn.com/machine-duping-101-clarence-chio-defcon24-presented-160808221831/75/Machine-Duping-101-Pwning-Deep-Learning-Systems-6-2048.jpg)
![softmaxfunction
[0.34, 0.57, 0.09]
predicted class: 1
correct class: 0
np.argmax
logits prediction
𝒇
hidden
layer
input
layer
output
layer
𝑊
activation
function
bias units
4-5-3 Neural Net Architecture
[17.0, 28.5, 4.50]
𝒇
𝒇](https://image.slidesharecdn.com/machine-duping-101-clarence-chio-defcon24-presented-160808221831/75/Machine-Duping-101-Pwning-Deep-Learning-Systems-7-2048.jpg)
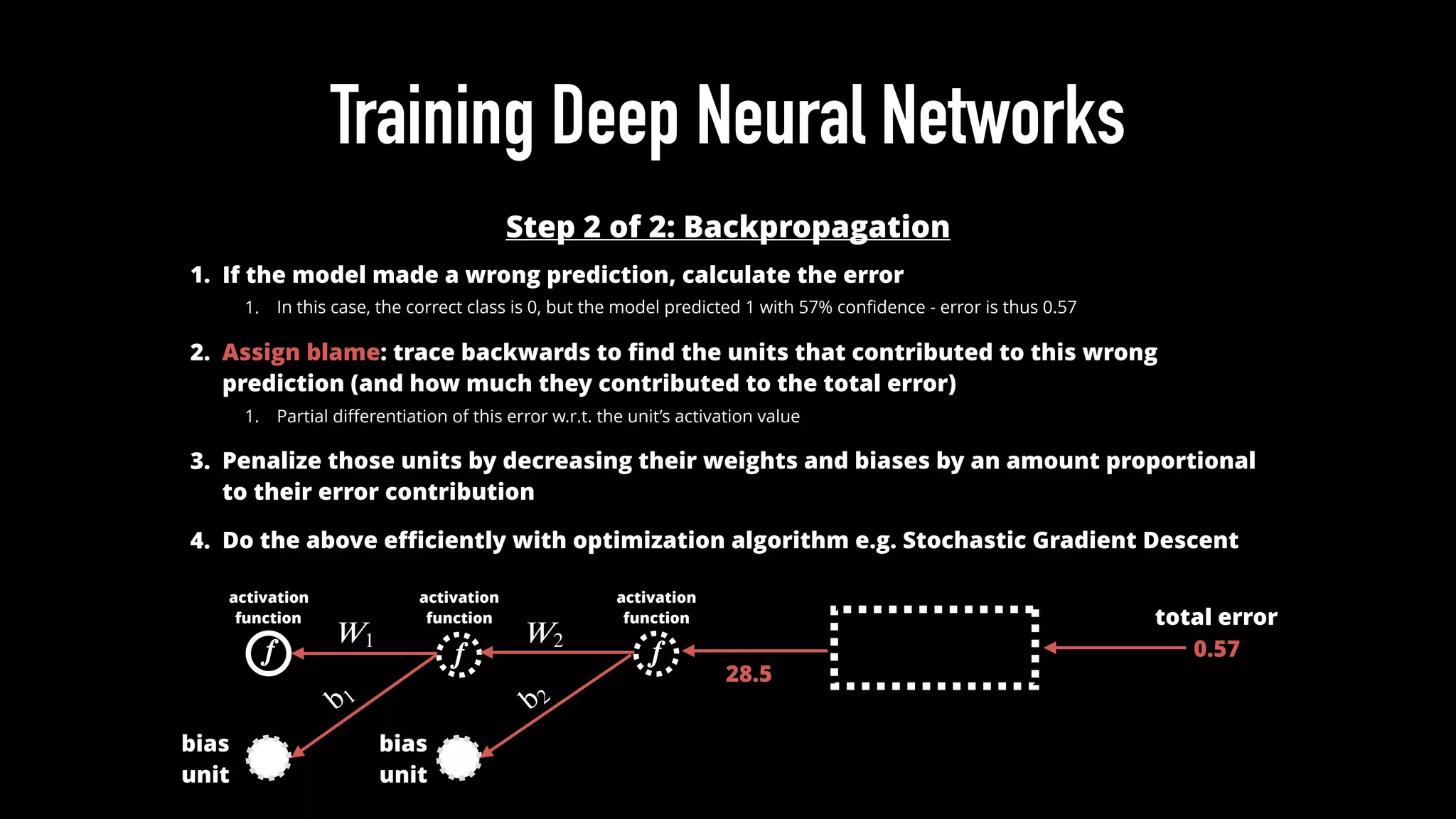
![Training Deep Neural Networks
Step 1 of 2: Feed Forward
1. Each unit receives output of the neurons in the previous layer (+ bias
signal)
2. Computes weighted average of inputs
3. Apply weighted average through nonlinear activation function
4. For DNN classifier, send final layer output through softmax function
softmax
function
[0.34, 0.57, 0.09]logits
prediction
𝒇
𝑊1
activation
function
[17.0, 28.5, 4.50]
𝒇 𝒇
activation
function
activation
function
input 𝑊2
b1 b2
bias
unit
bias
unit](https://image.slidesharecdn.com/machine-duping-101-clarence-chio-defcon24-presented-160808221831/75/Machine-Duping-101-Pwning-Deep-Learning-Systems-8-2048.jpg)

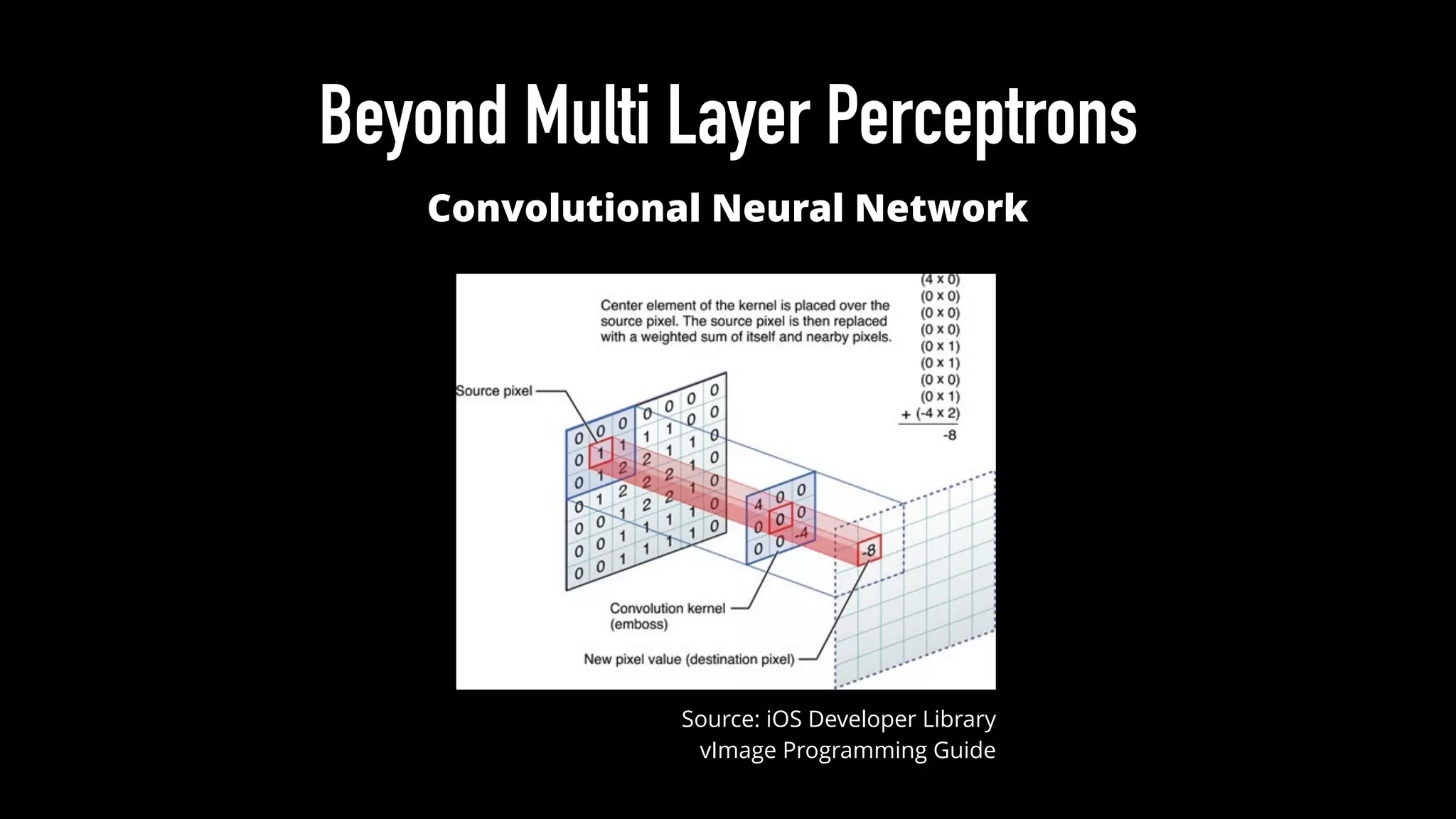
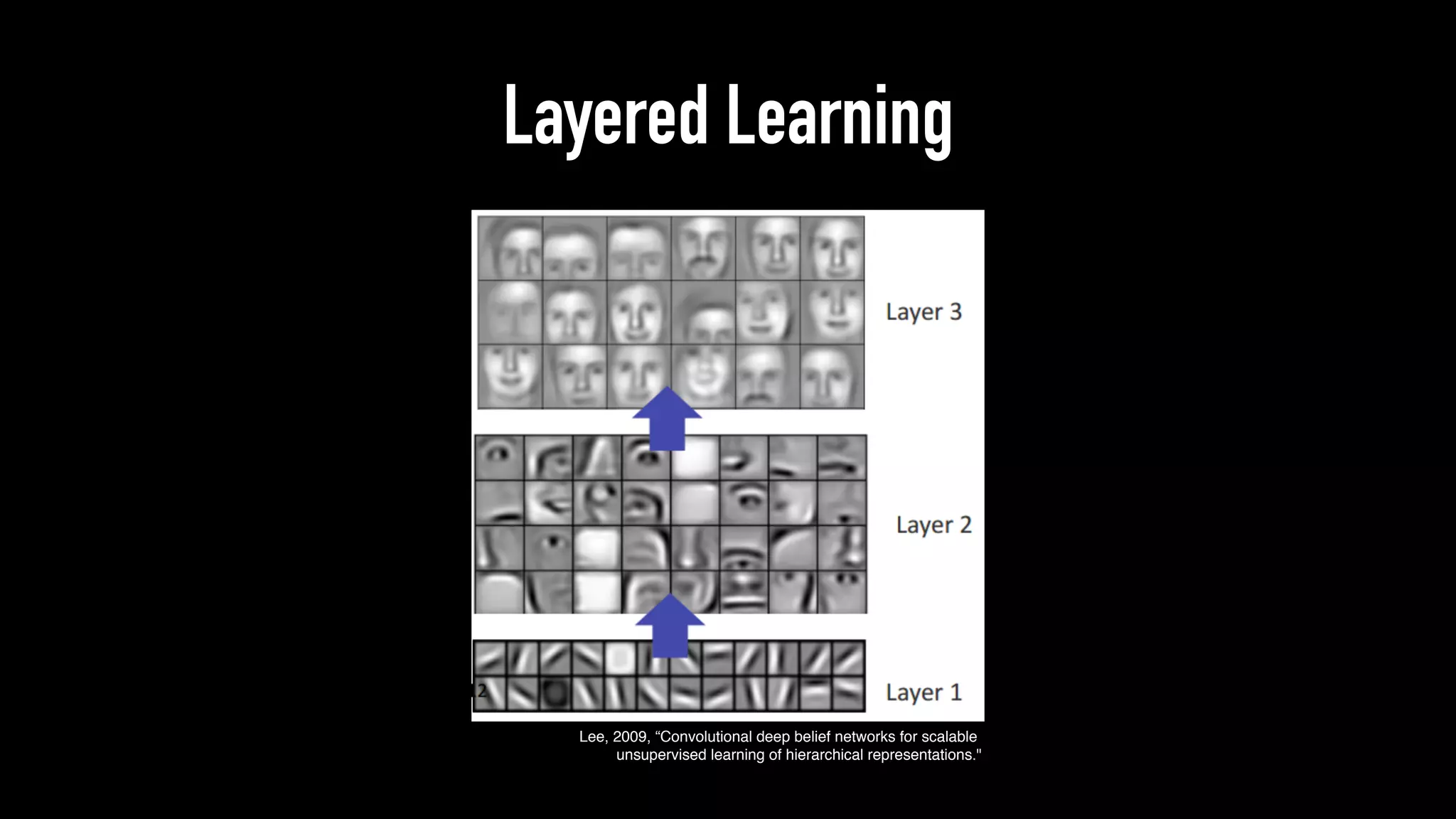
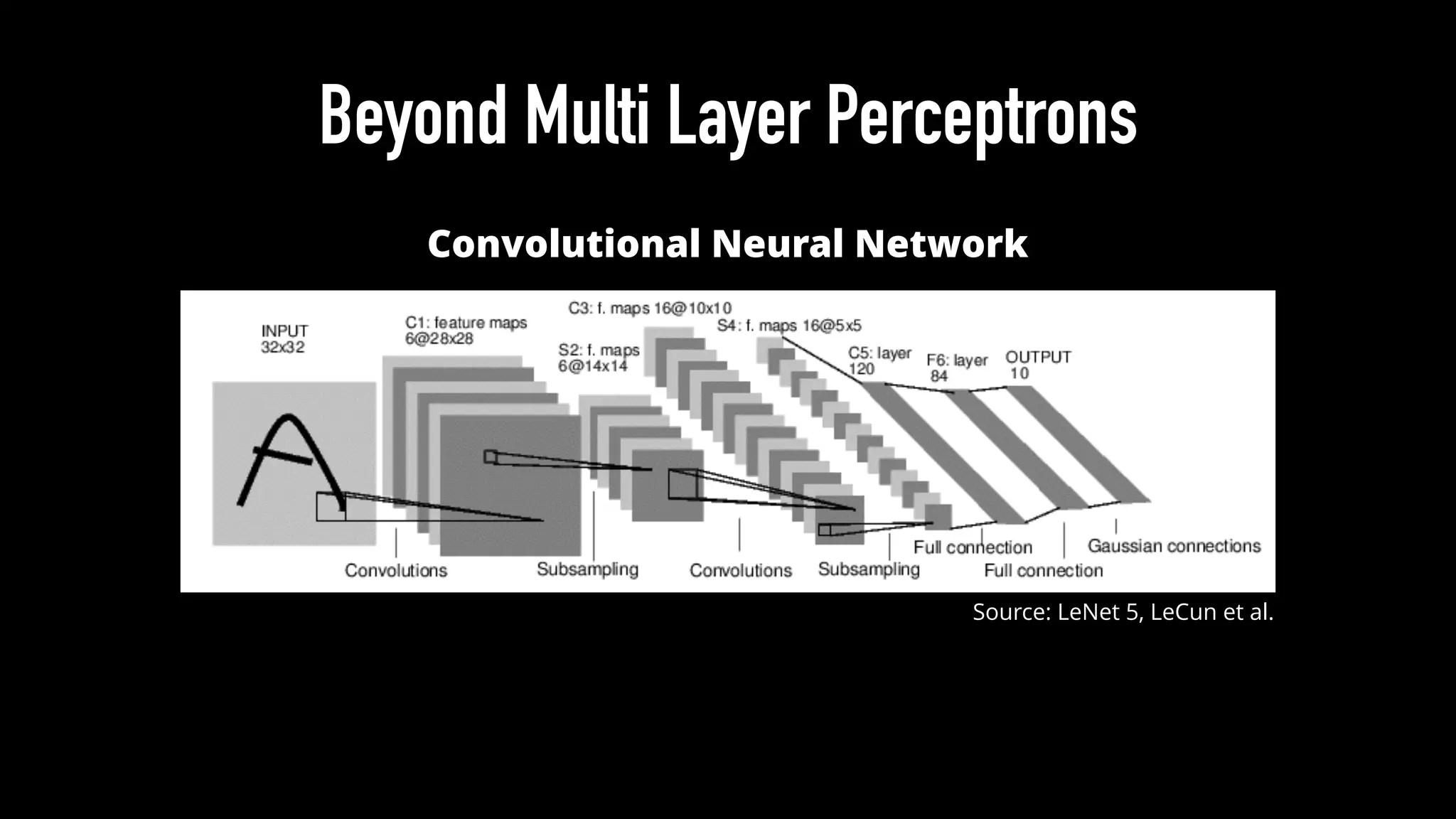
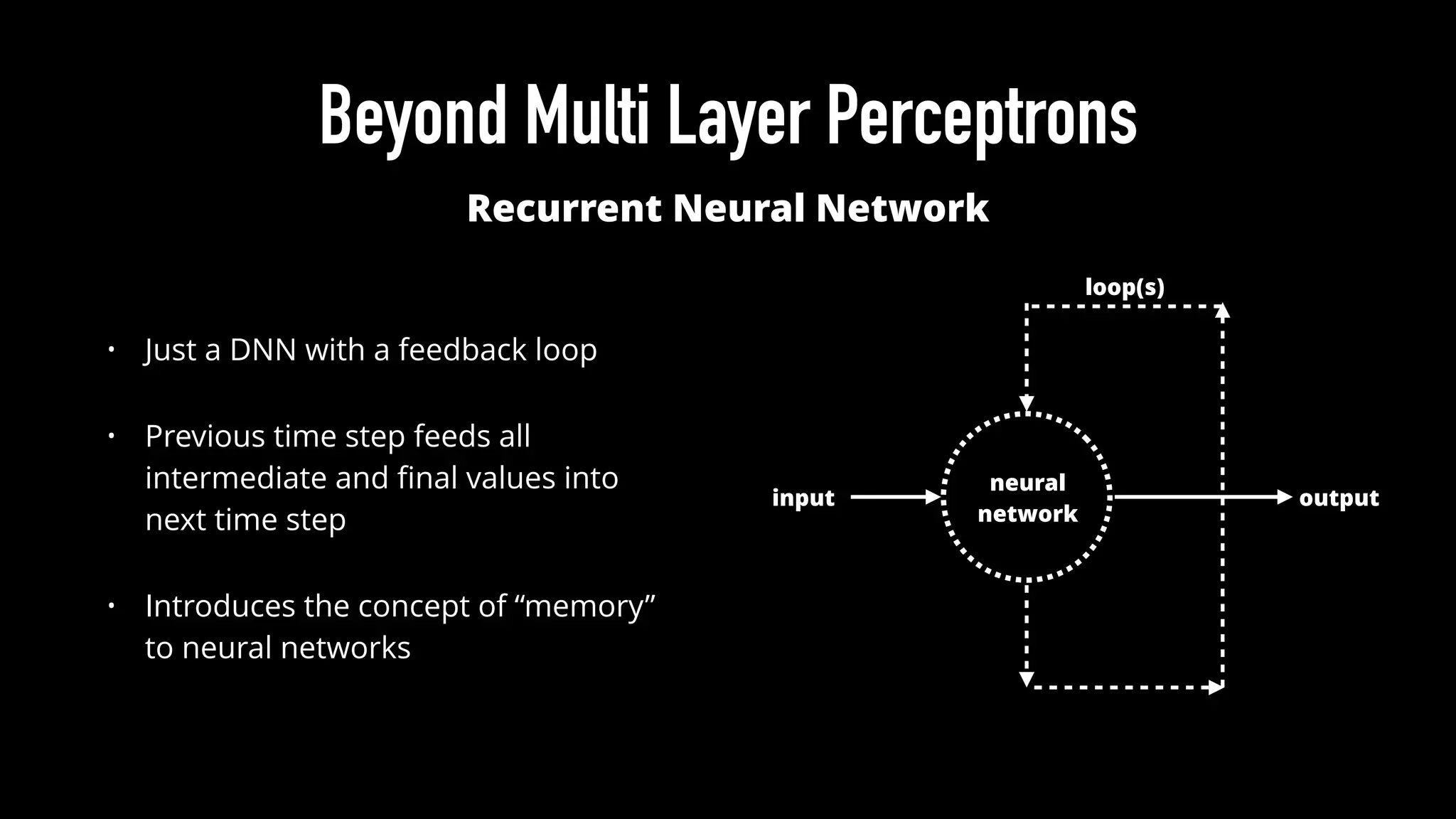
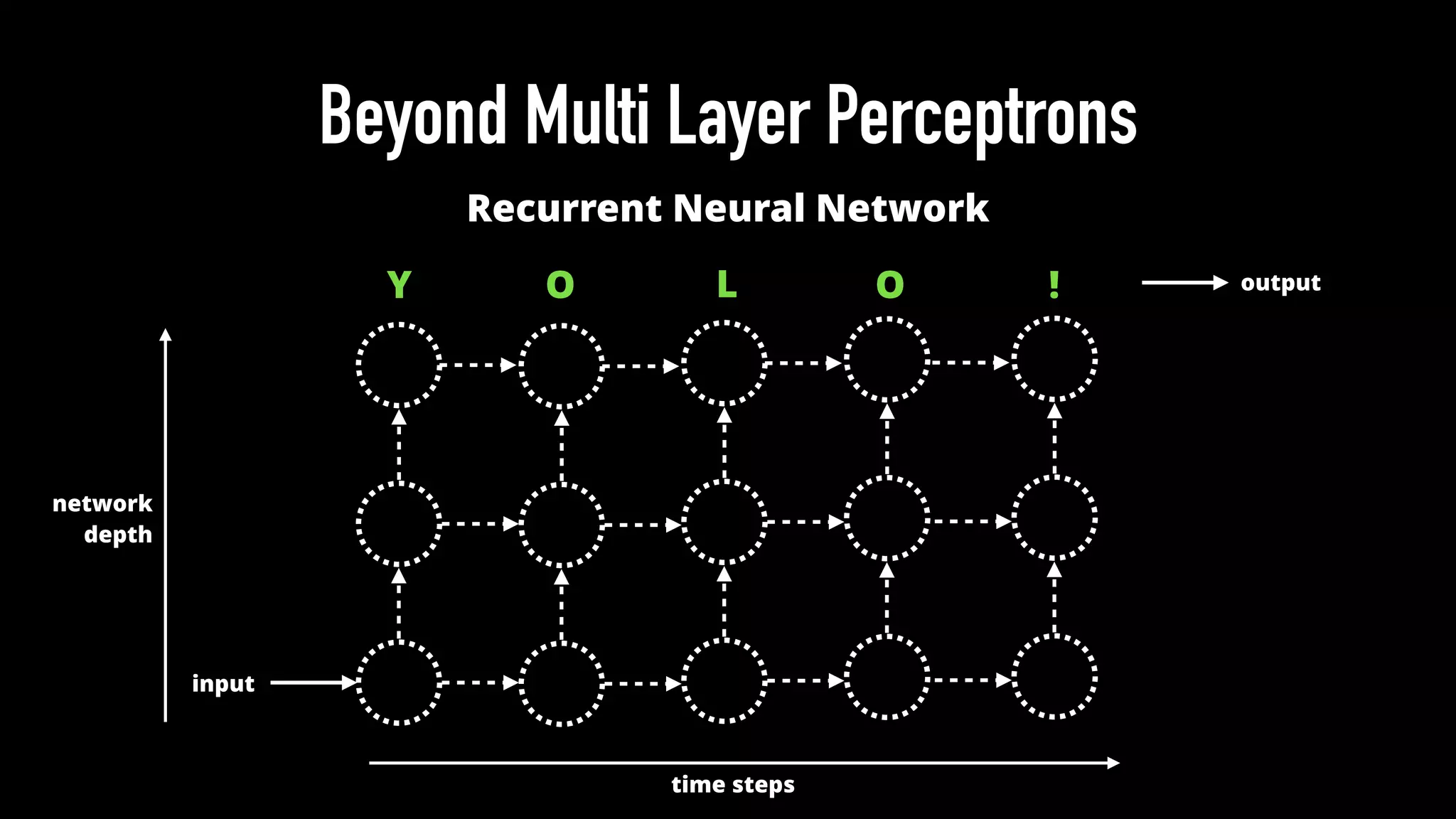

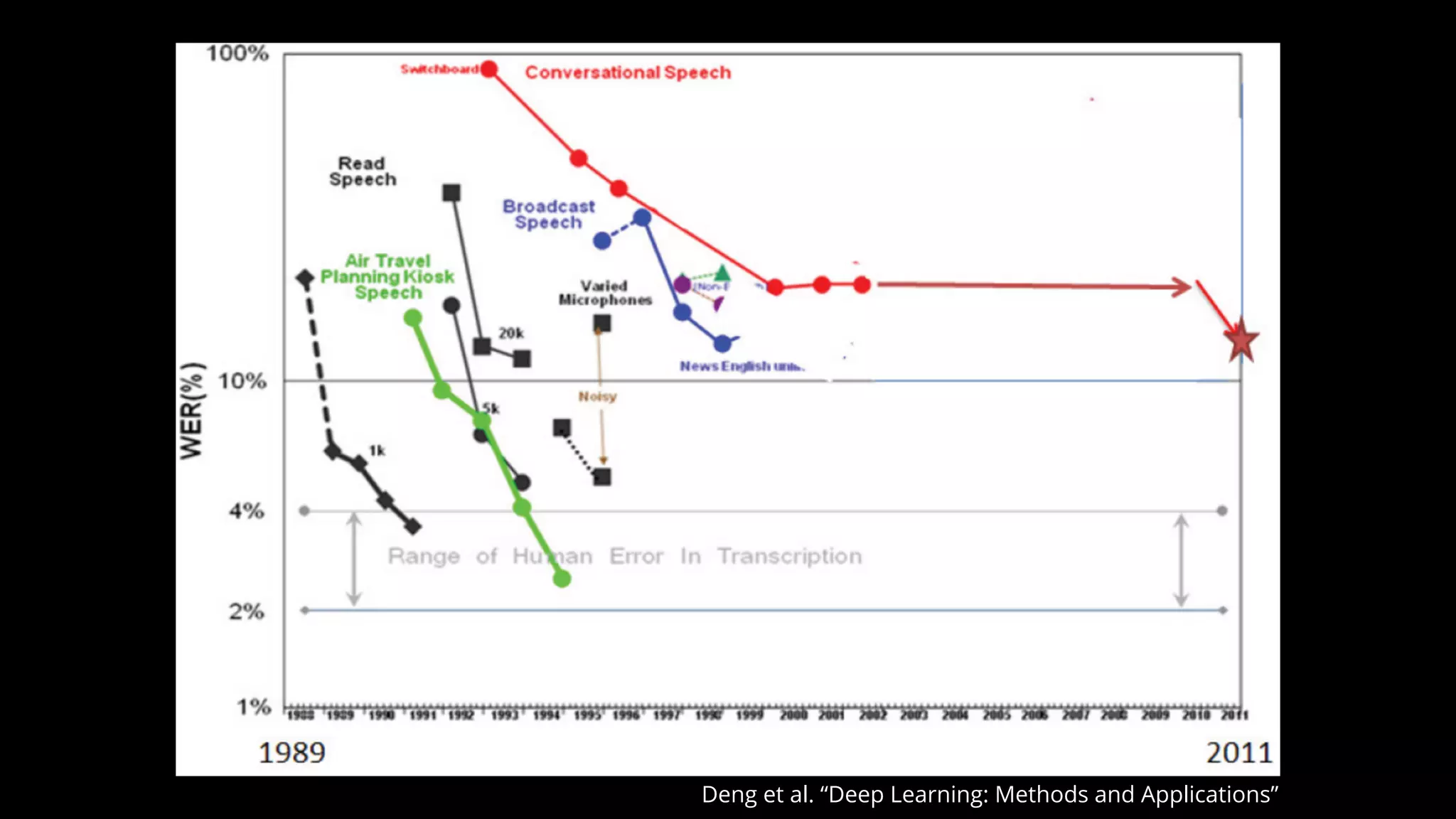

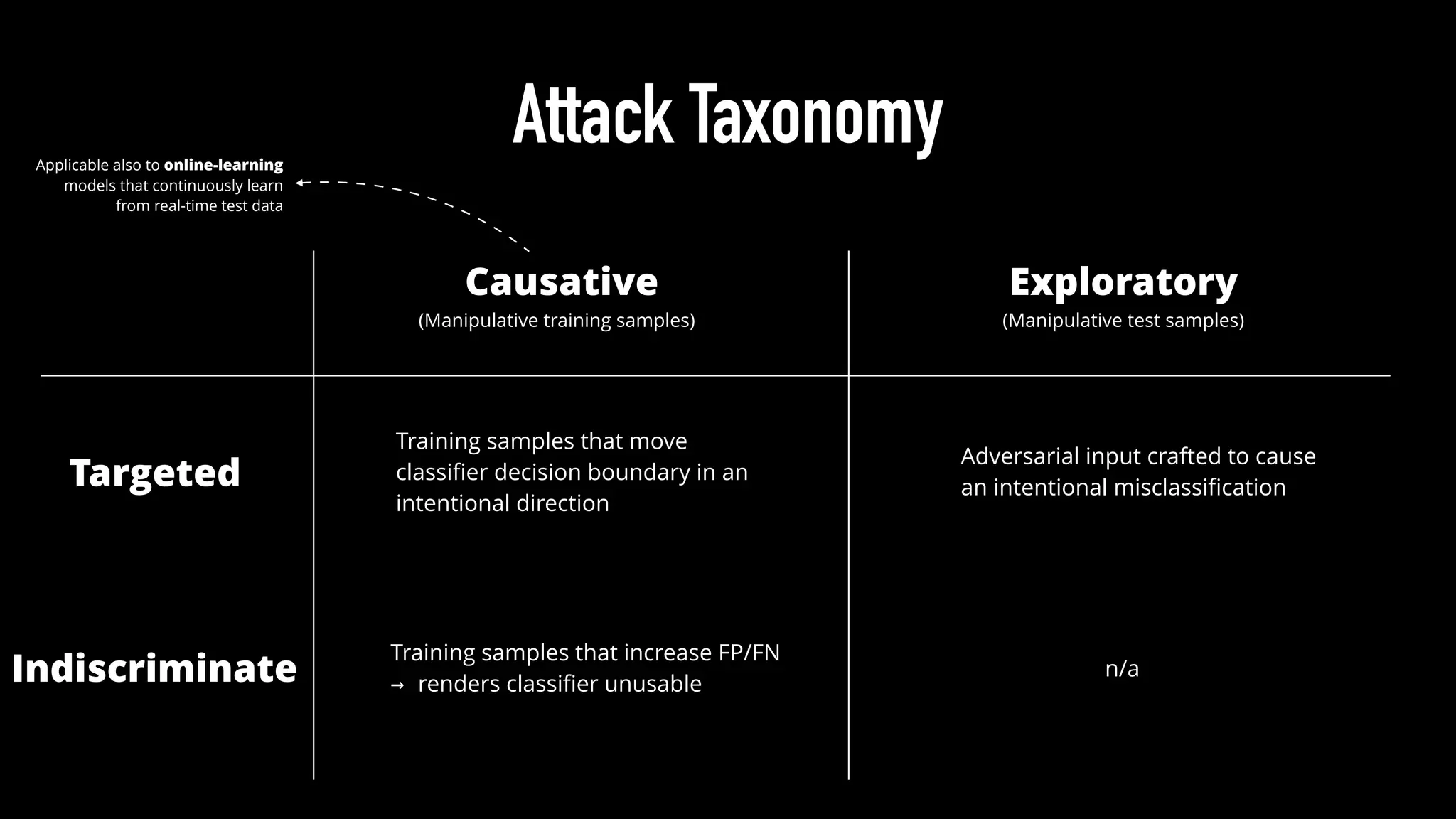





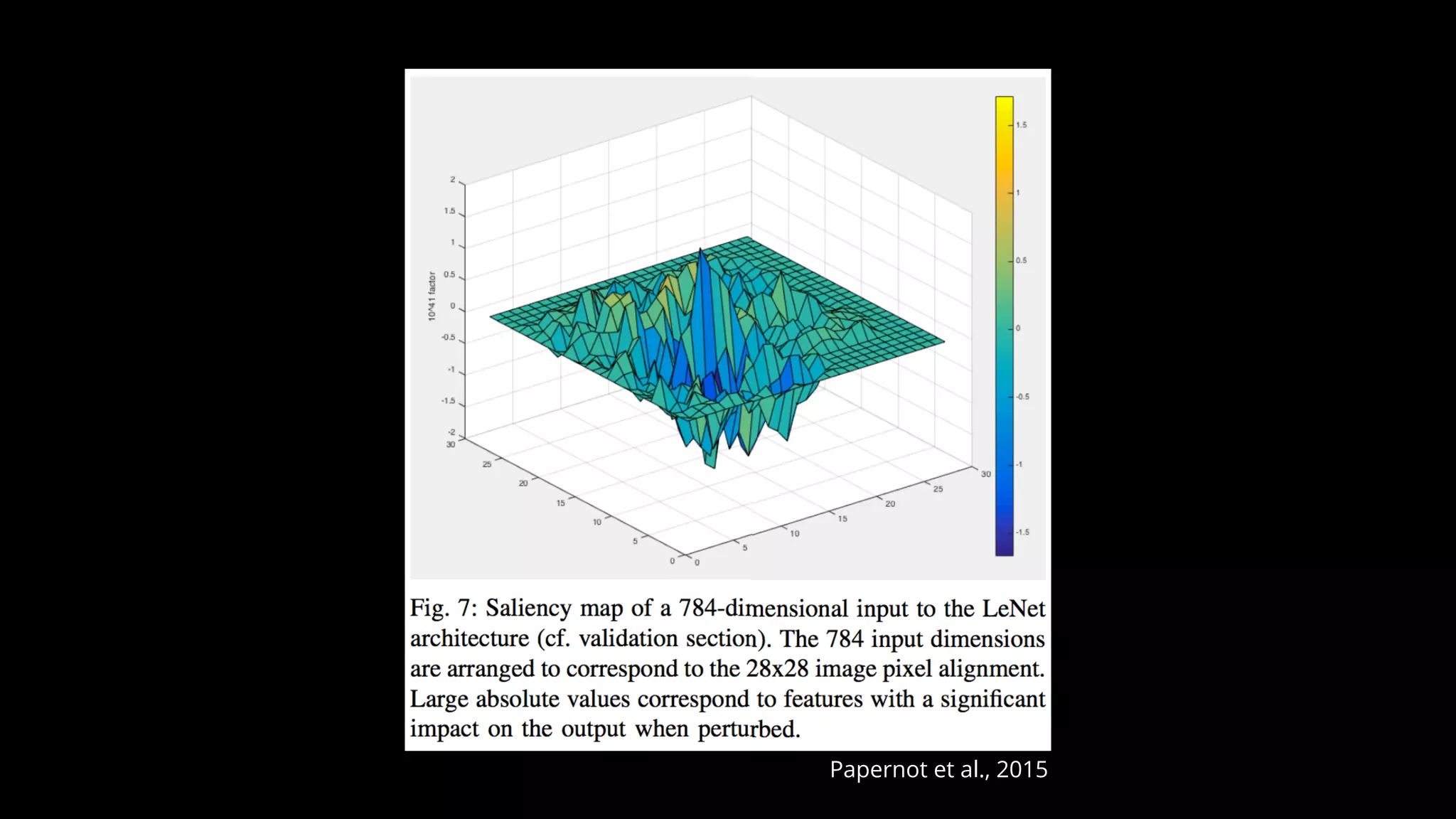
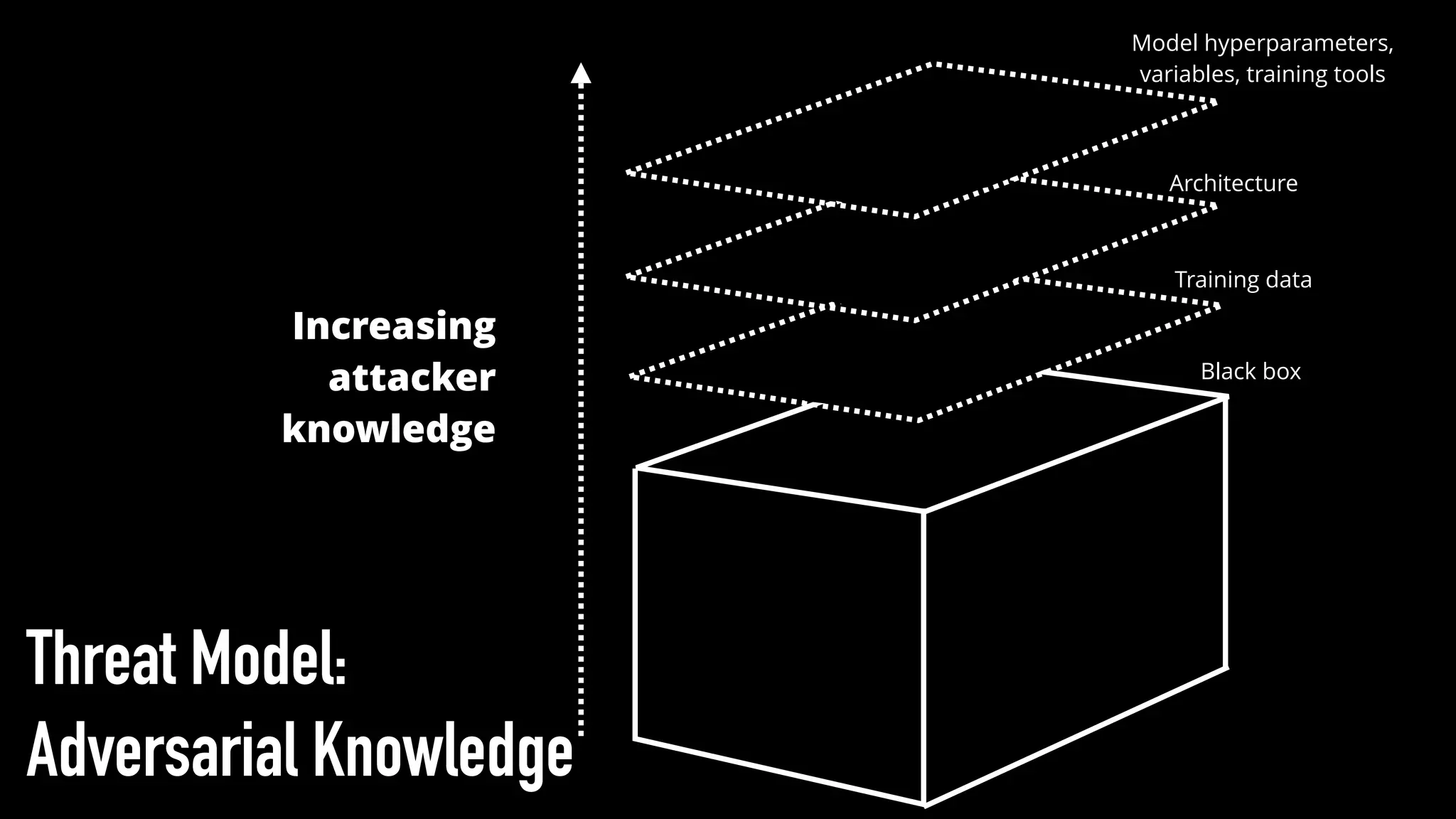



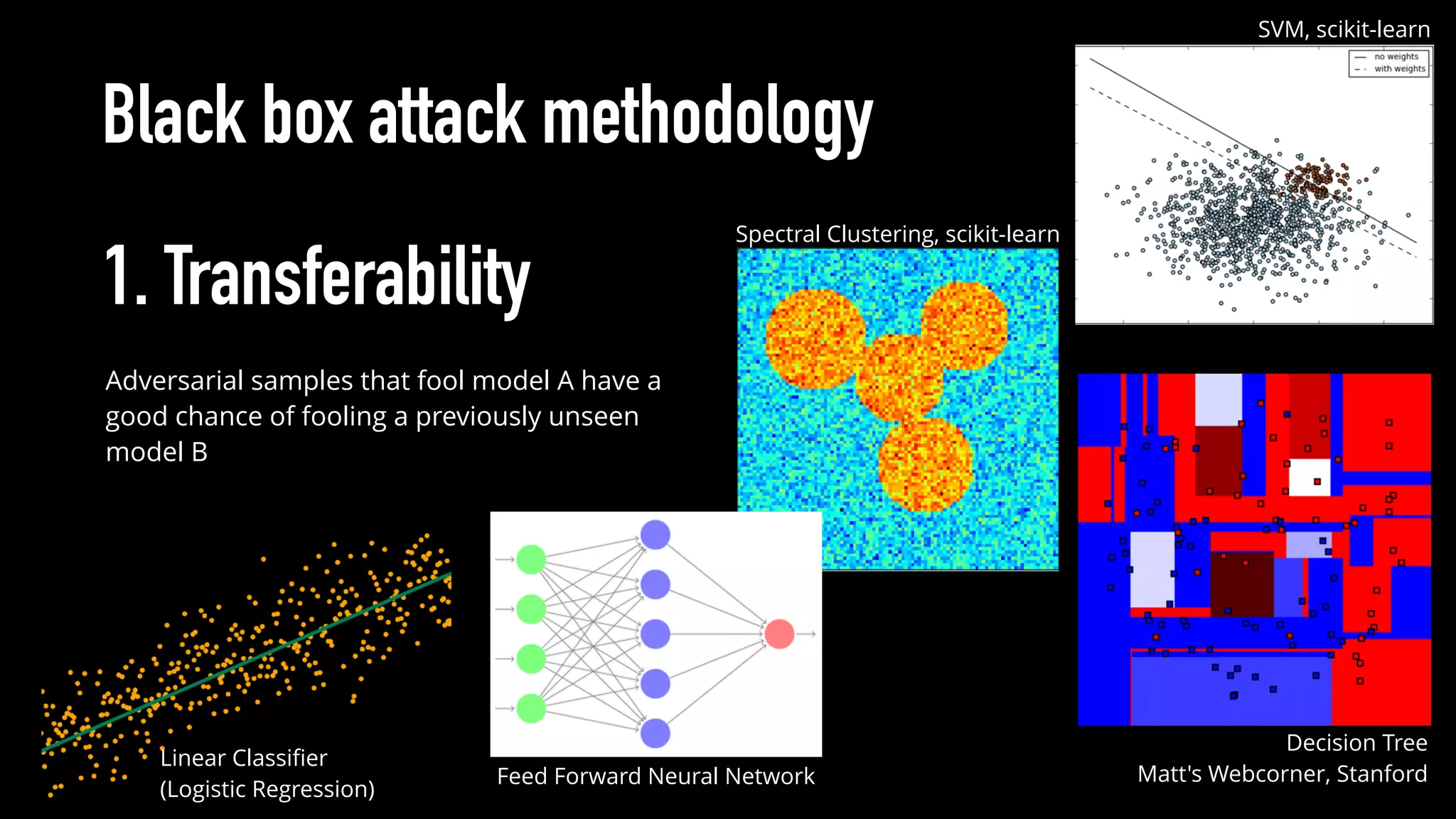
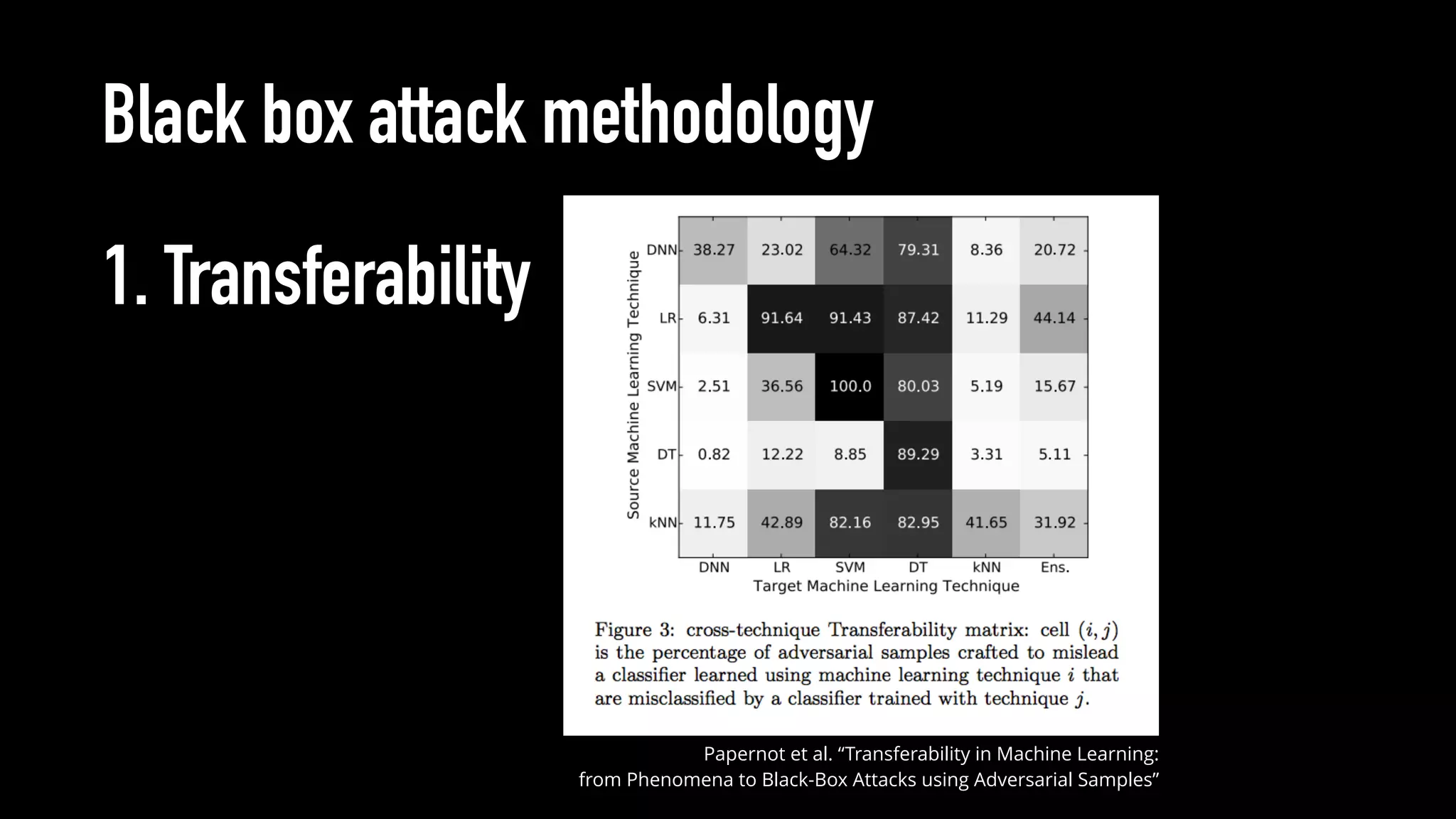
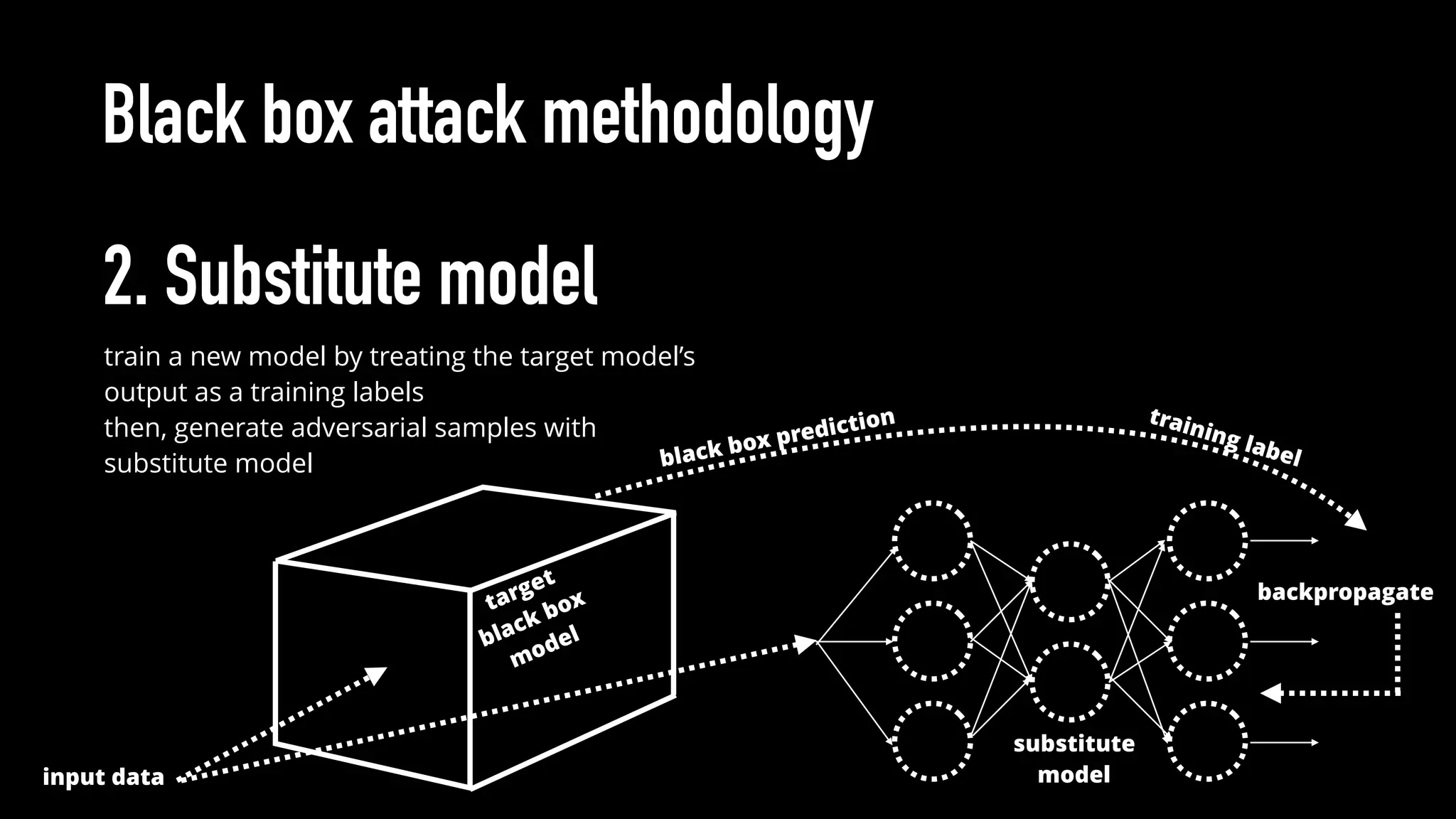












The document discusses various aspects of deep learning systems, focusing on potential vulnerabilities to adversarial attacks and the methodologies behind them, such as black box attacks and transferability of adversarial samples. It emphasizes the need for evaluating models for adversarial resilience and suggests strategies for increasing robustness, including training with adversarial examples. Additionally, it highlights the importance of security and privacy in deep learning, urging the development of robust systems amidst growing reliance on machine learning.


















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















