



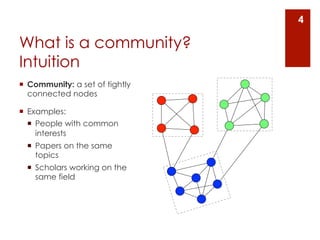
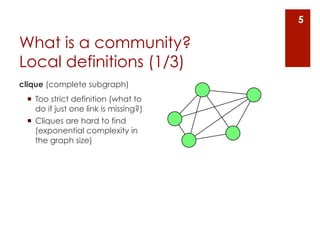
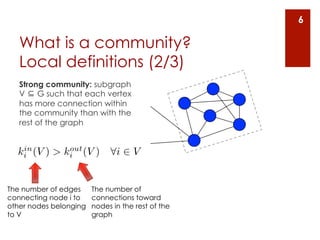





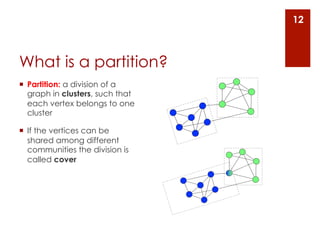



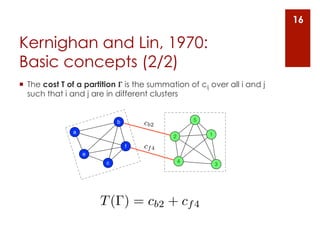
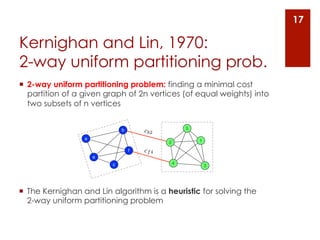





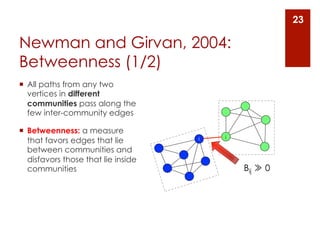




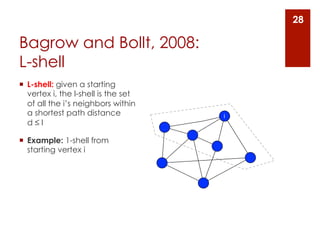
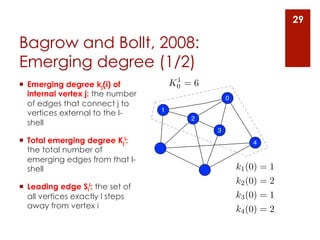
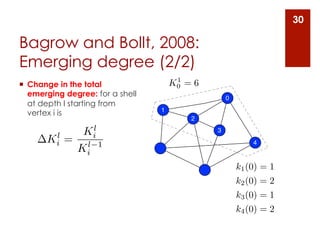


















The document provides an overview of community detection in networks. It defines what a community and partition are, and describes several algorithms for partitioning networks into communities: 1. Kernighan and Lin's algorithm from 1970 which iteratively swaps nodes between partitions to minimize the cost. 2. Newman and Girvan's algorithm from 2004 which removes the edge with the highest betweenness centrality on each iteration. 3. Bagrow and Bollt's algorithm from 2008 which expands a shell of nodes out from a seed node, looking for a drop in the total emerging degree to identify community boundaries. The document also discusses different ways to define communities, assess partition quality, and represent partitioning results as a dendrogram










![Community detection in social networks[1]](https://cdn.slidesharecdn.com/ss_thumbnails/communitydetectioninsocialnetworks1-121022180209-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















































































