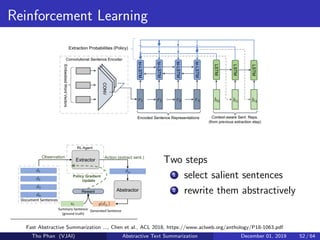
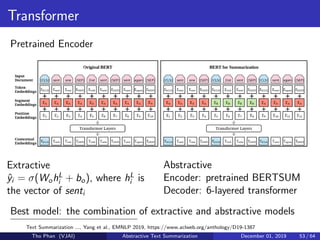
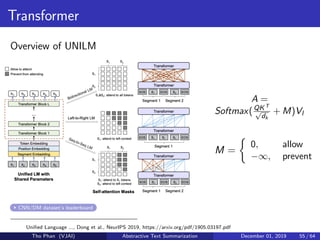
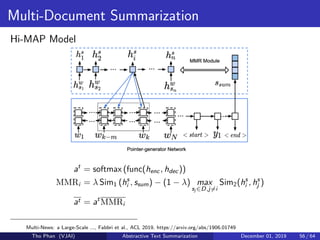
The document discusses the concepts of abstractive text summarization using sequence-to-sequence models with attention mechanisms, highlighting their role in natural language generation. It explains the differences between extractive and abstractive summarization, the importance of attention in improving model performance, and various decoding algorithms. Additionally, it covers evaluation metrics like ROUGE and challenges in measuring the quality of generated summaries.






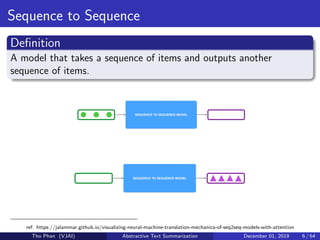
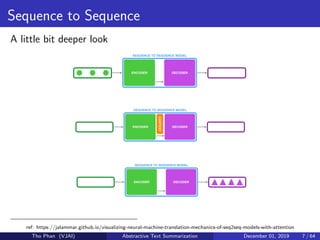
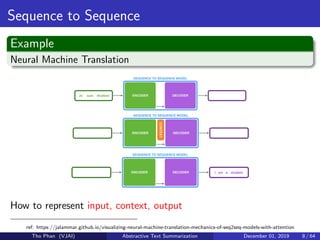

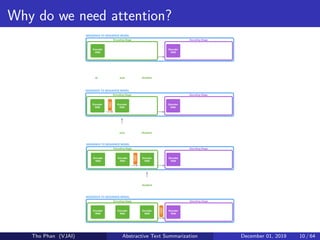

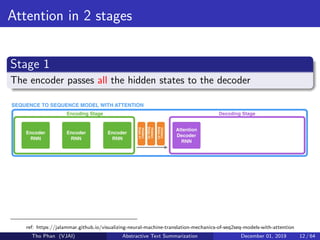

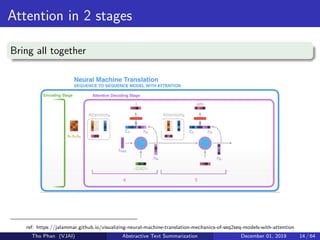
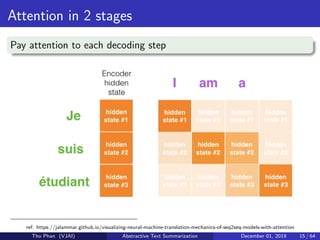






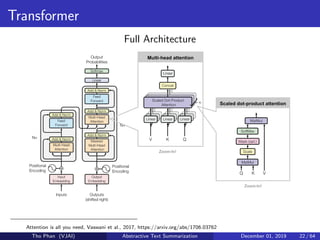
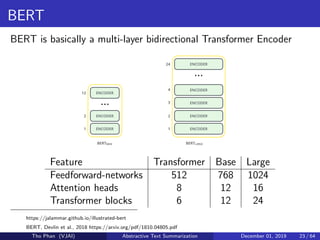








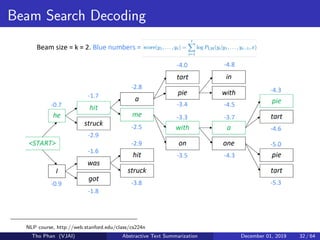






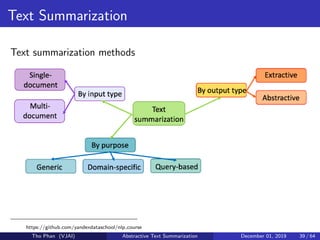









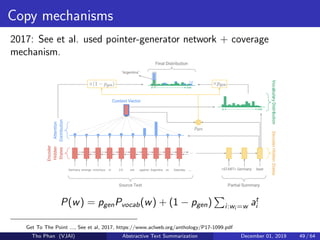



















































![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)


























