Module 4.1 of chennai's slides wo hanve dot do thhopps otps
1.
Module 4 –Semantics
Analysis
Semantics- Lexical Semantics- Word Senses - Relations between Senses -
Word Sense Disambiguation (WSD) – Word Similarity Analysis using
Thesaurus and Distributional methods – Word2vec – fastText word
Embedding - Lesk Algorithm – Thematic Roles, Semantic Role labelling -
Pragmatics Analysis - Anaphora Resolution.
2.
2
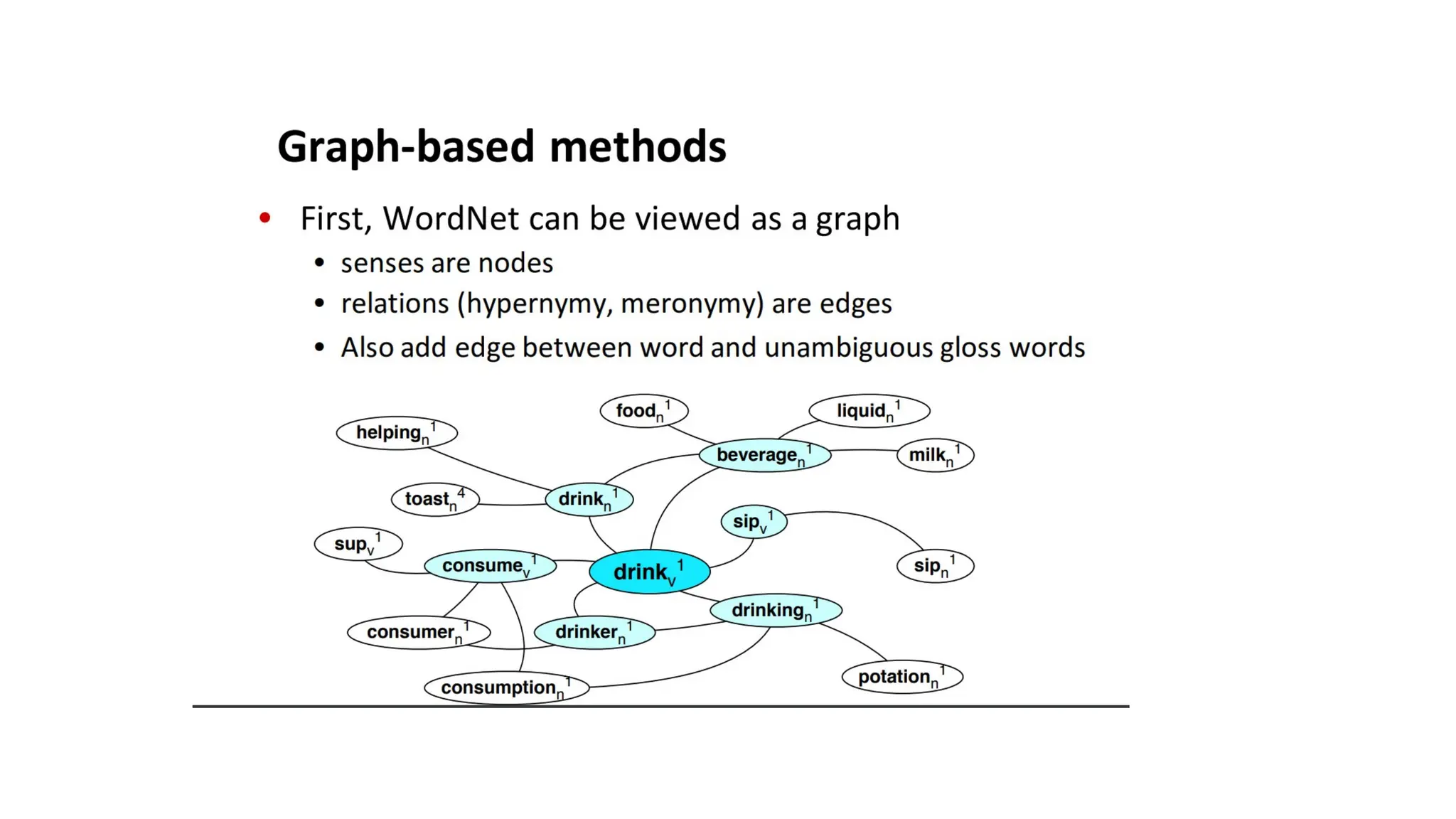
Semantic Analysis
• Assigningmeanings to the structures created by syntactic analysis.
• Mapping words and structures to particular domain objects in way
consistent with our knowledge of the world.
• Semantic can play an import role in selecting among competing
syntactic analyses and discarding logical analyses.
• I robbed the bank -- bank is a river bank or a financial institution
• We have to decide the formalisms- which will be used in the meaning
representation.
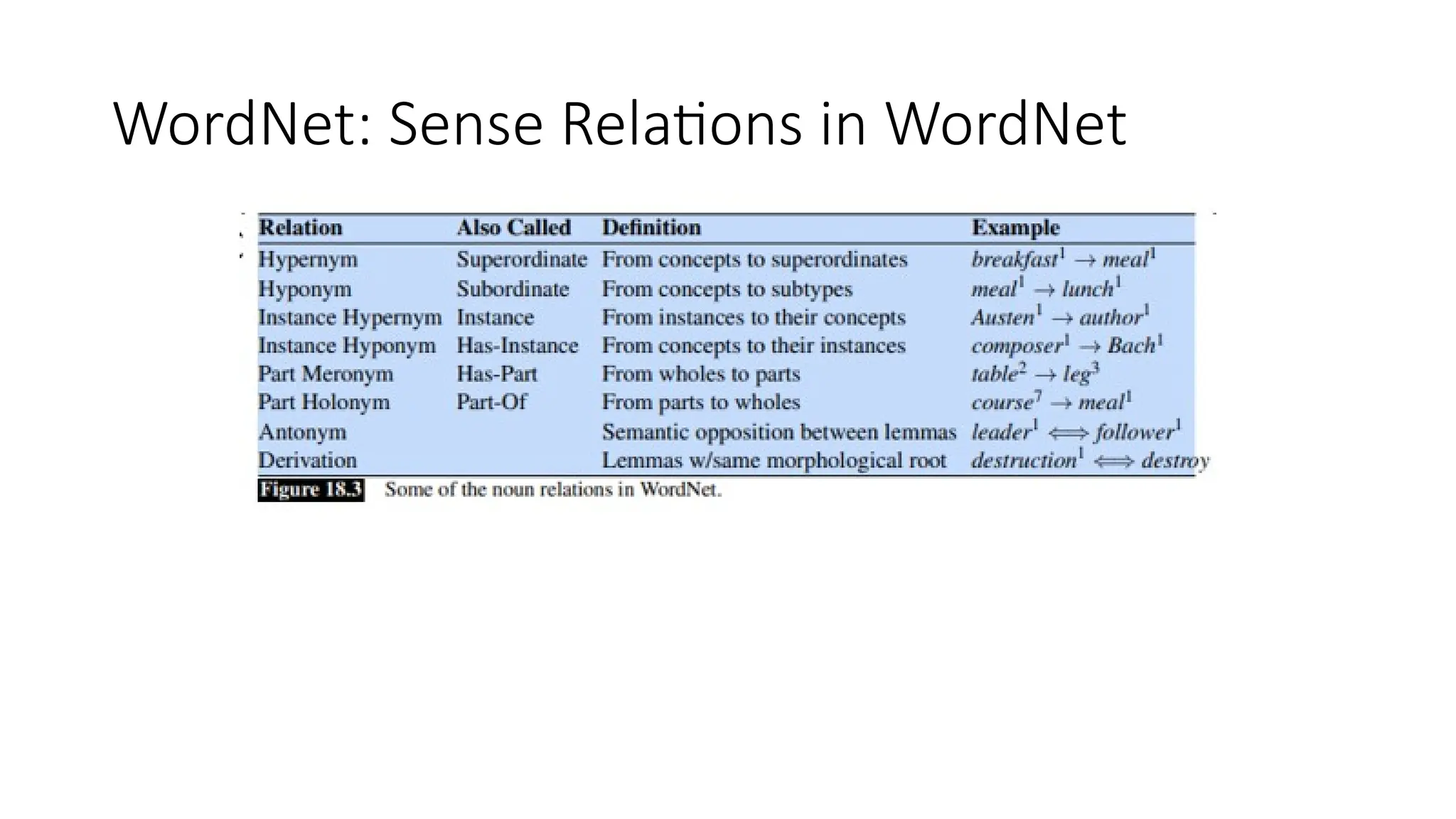
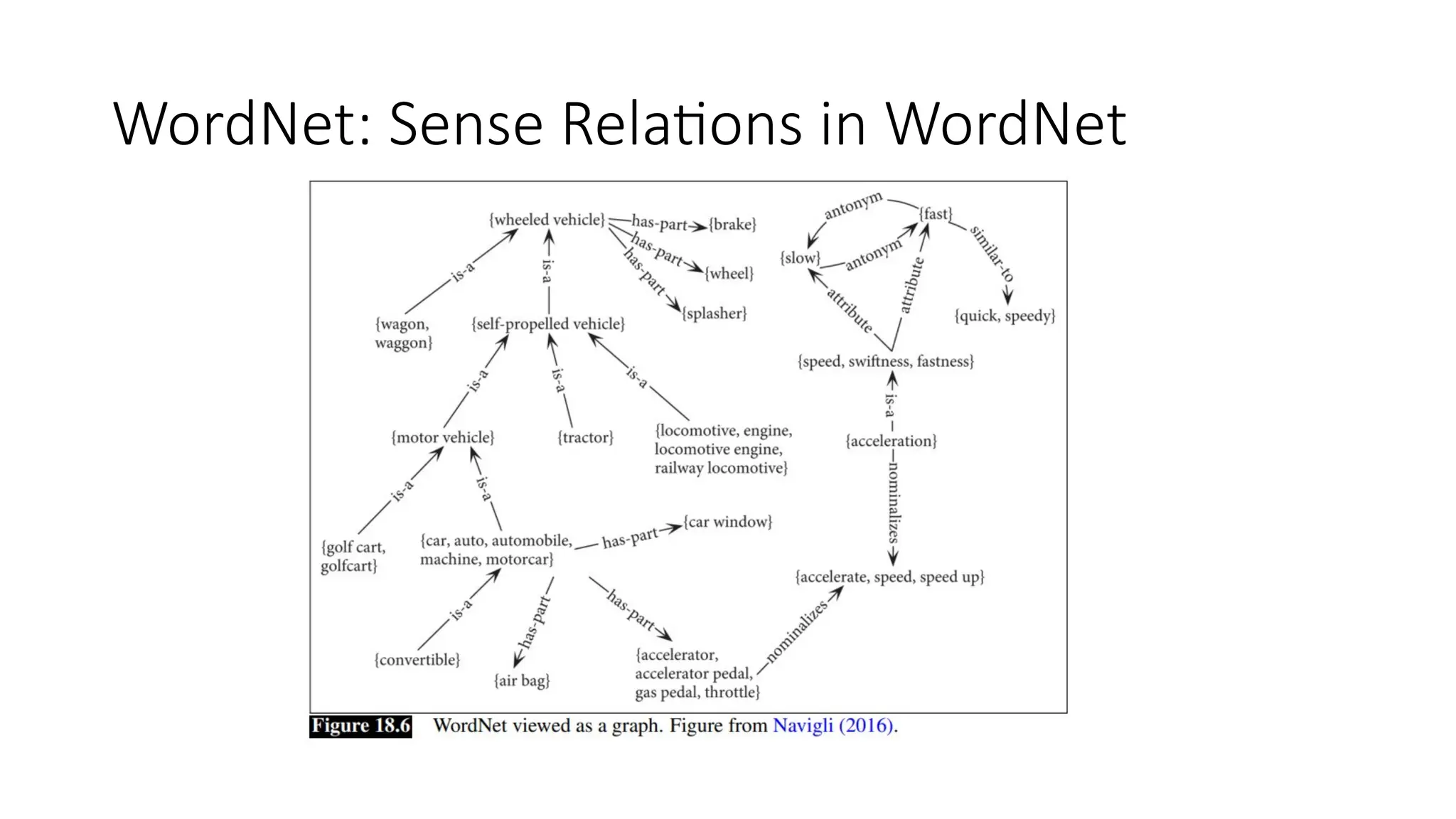
WordNet Synset Relationships
•Antonym: front back
• Attribute: benevolence good (noun to adjective)
• Pertainym: alphabetical alphabet (adjective to noun)
• Similar: unquestioning absolute
• Cause: kill die
• Entailment: breathe inhale
• Holonym: chapter text (part to whole)
• Meronym: computer cpu (whole to part)
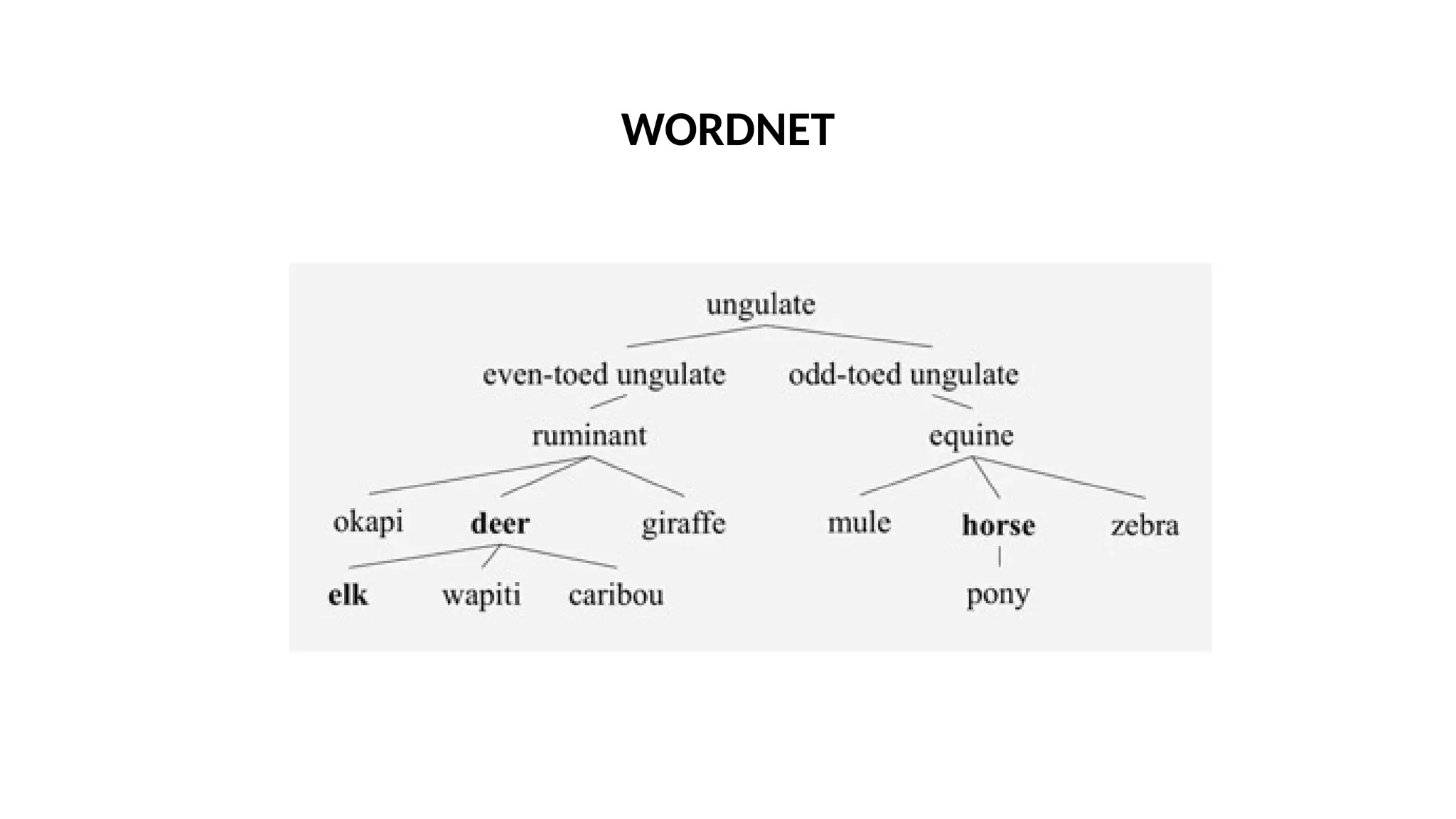
• Hyponym: plant tree (specialization)
• Hypernym: apple fruit (generalization)
20.
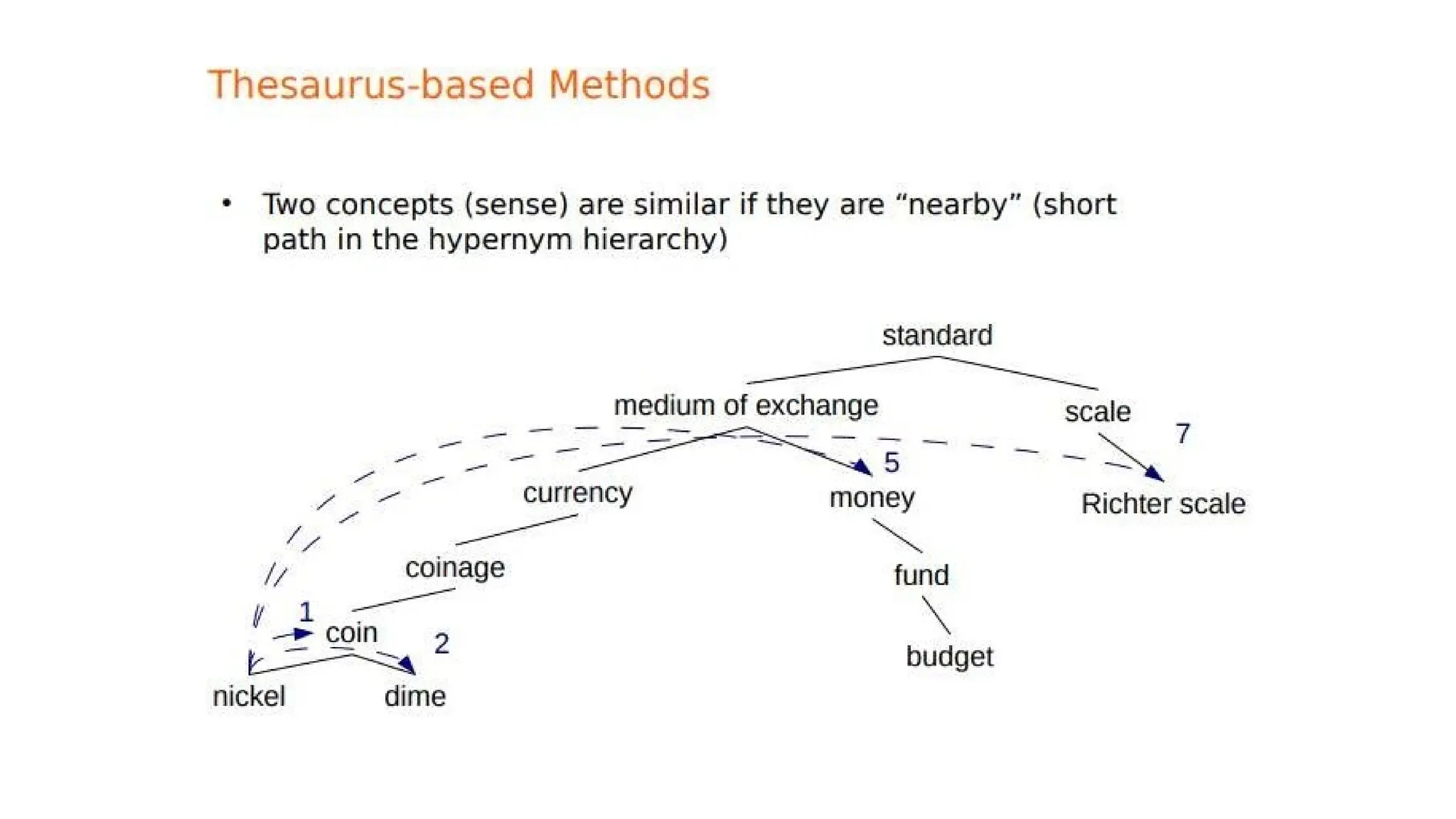
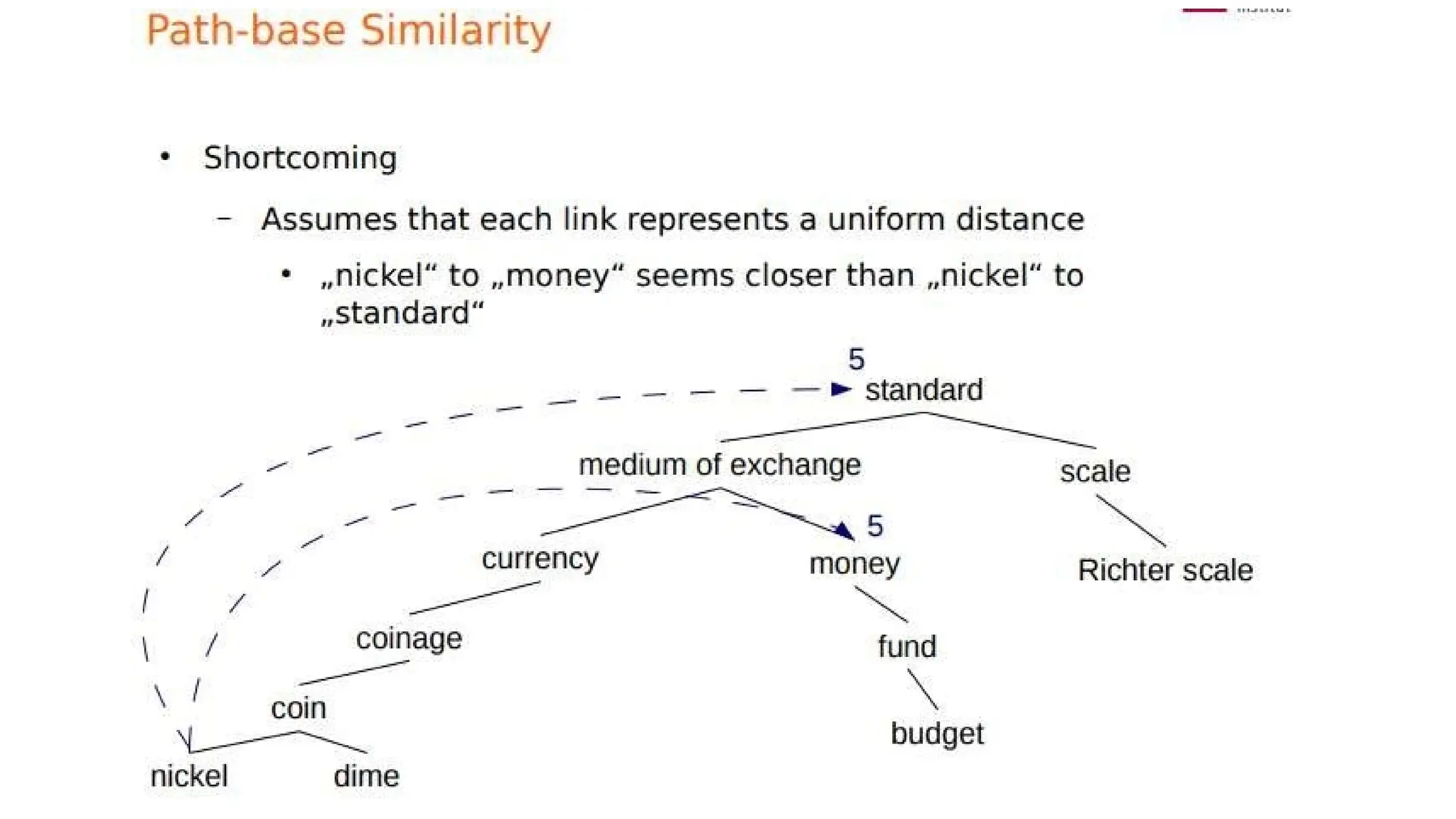
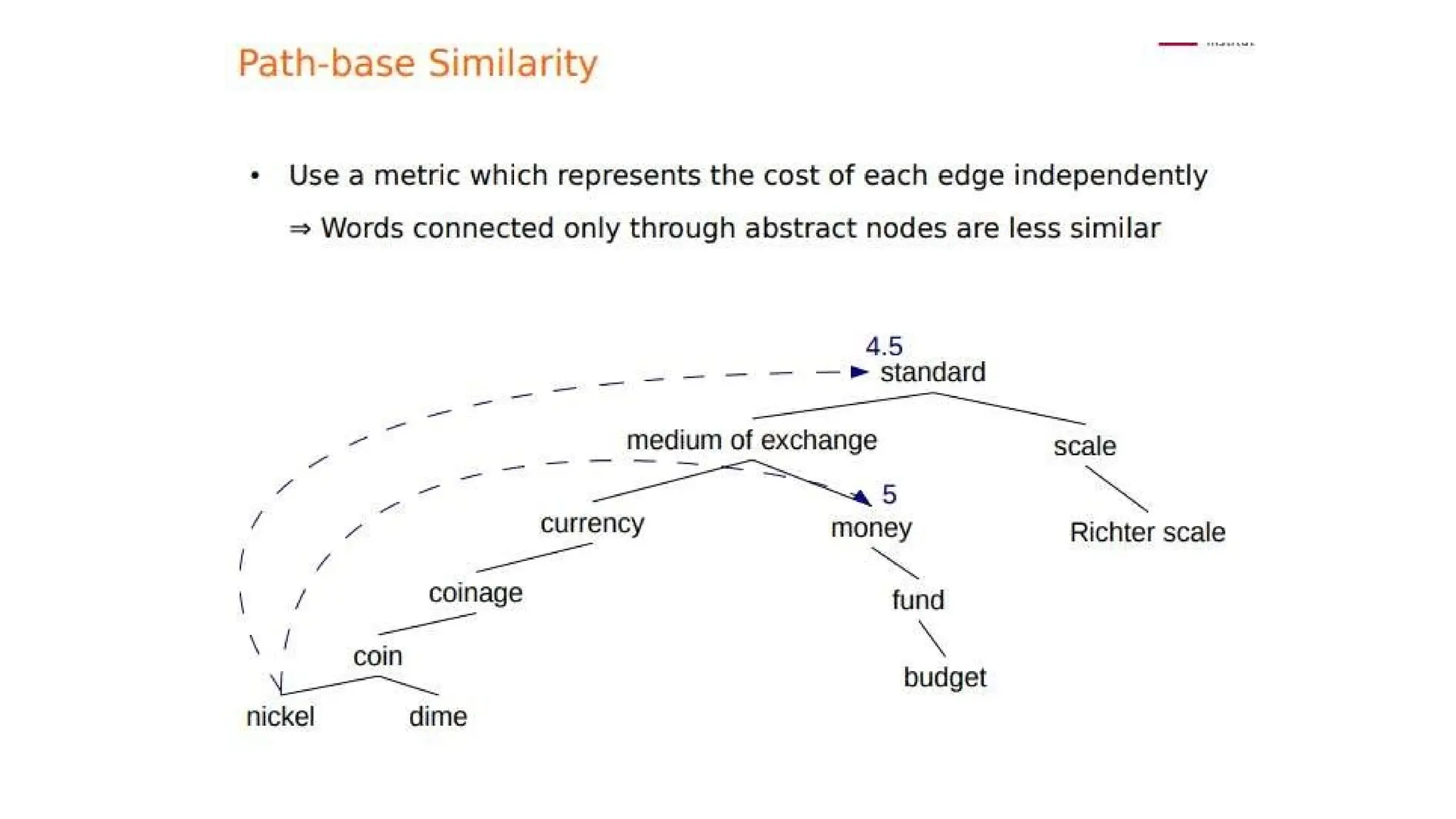
ways that dictionariesand thesauruses offer for defining senses
Glosses: textual definitions for each sense. Glosses are not a formal meaning
representation; they are just written for people.
Ex: Two sense for bank
1. financial institution that accepts deposits and channels the money into
lending activities 2. sloping land (especially the slope beside a body of
water)
Dictionary definitions: Defining a sense through its relationship with other
senses. Formal meaning
Word Sense
21.
WordNet: A Databaseof Lexical Relations
• WordNet lexical database: English WordNet consists of three separate
databases, one each for nouns and verbs and a third for adjectives
and adverbs.
• Each database contains a set of lemmas, each one annotated with a
set of senses.
• The WordNet 3.0 release has 117,798 nouns, 11,529 verbs, 22,479
adjectives, and 4,481 adverbs.
• The average noun has 1.23 senses, and the average verb has 2.16
senses.
22.
WordNet: A Databaseof Lexical Relations
• The set of near-synonyms for a WordNet sense is called a synset (for synonym set);
synsets are an important primitive in WordNet. The entry for bass includes synsets like
{bass6 , bass voice1 , basso2}
23.
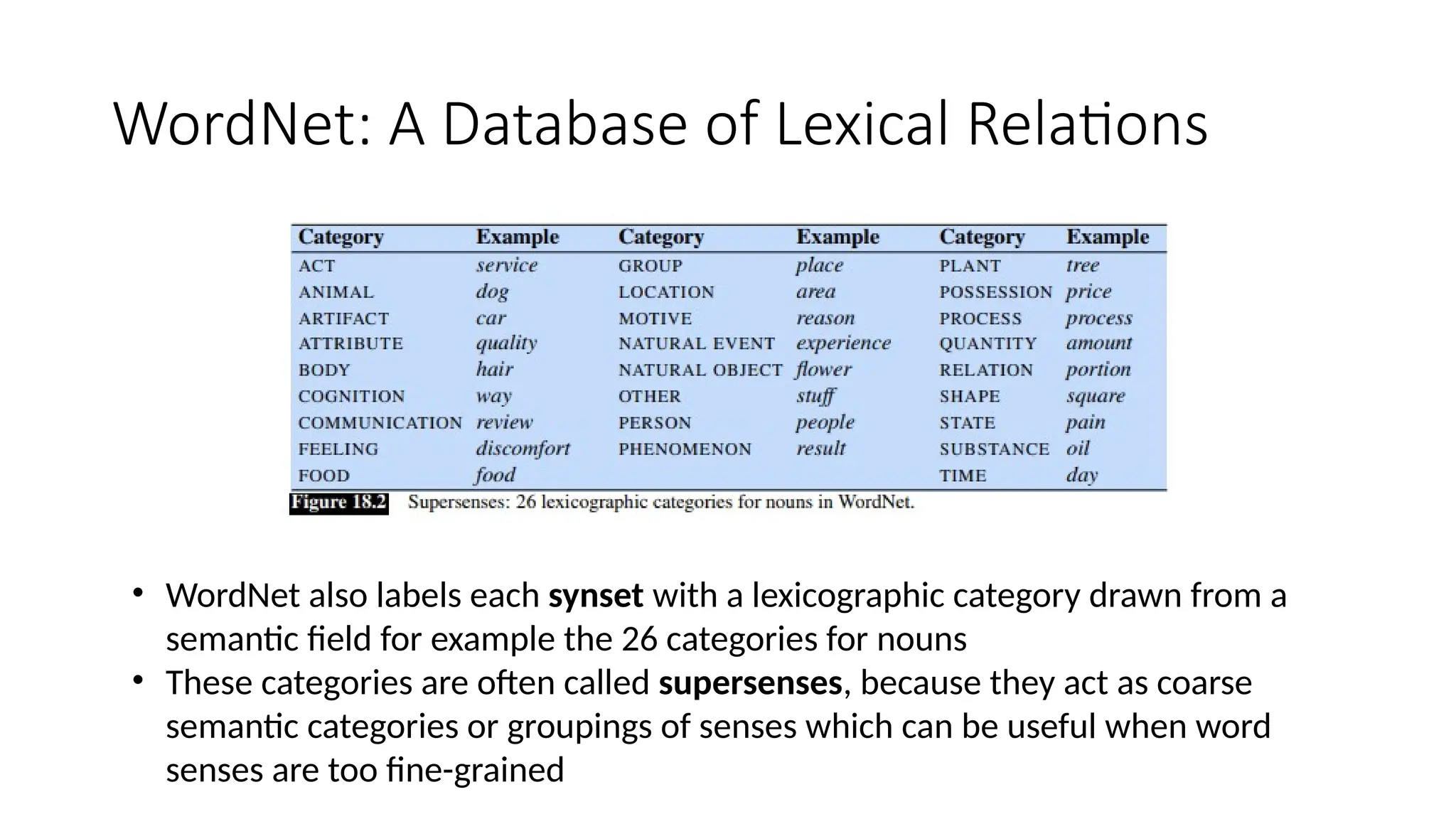
WordNet: A Databaseof Lexical Relations
• WordNet also labels each synset with a lexicographic category drawn from a
semantic field for example the 26 categories for nouns
• These categories are often called supersenses, because they act as coarse
semantic categories or groupings of senses which can be useful when word
senses are too fine-grained
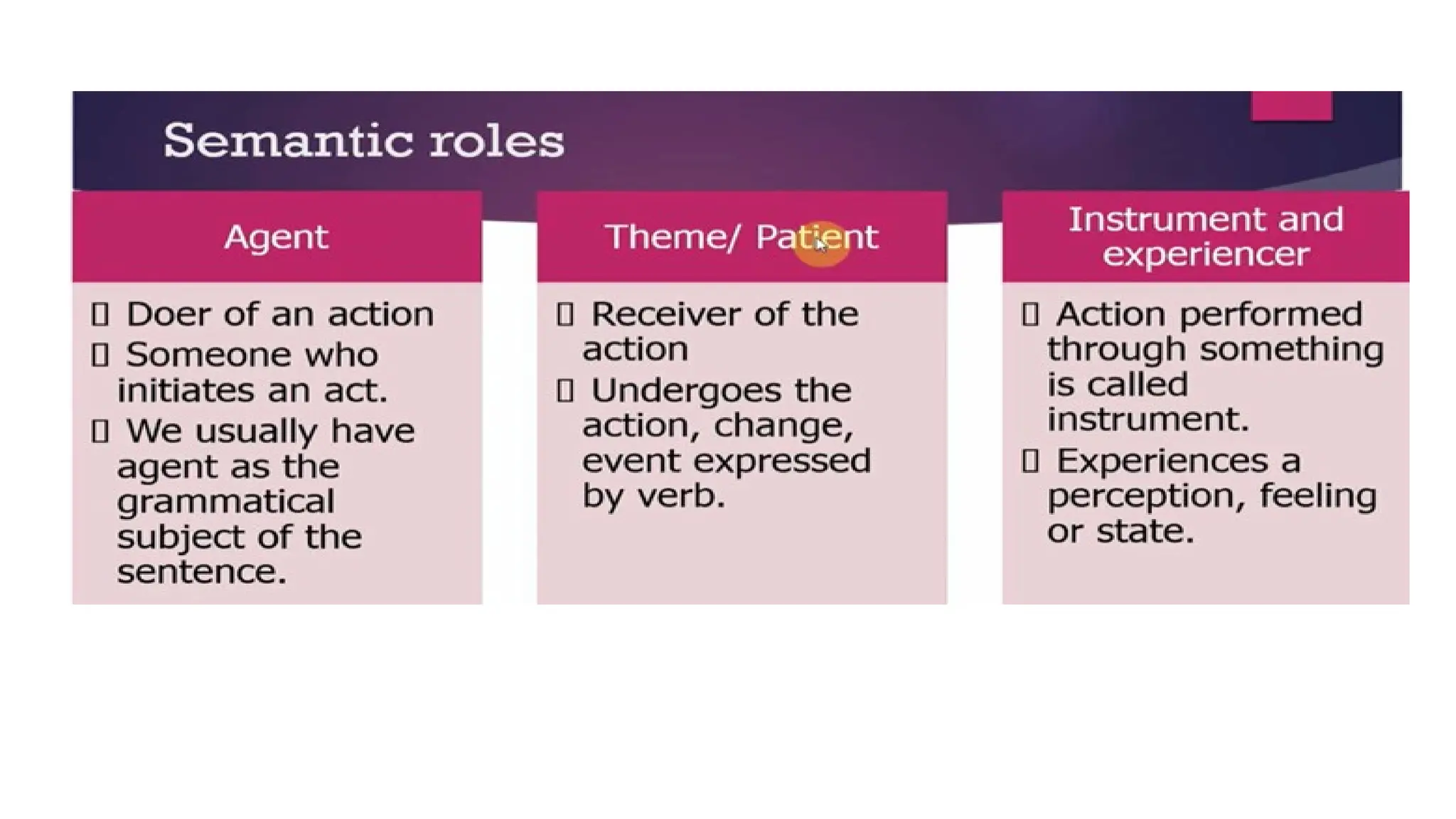
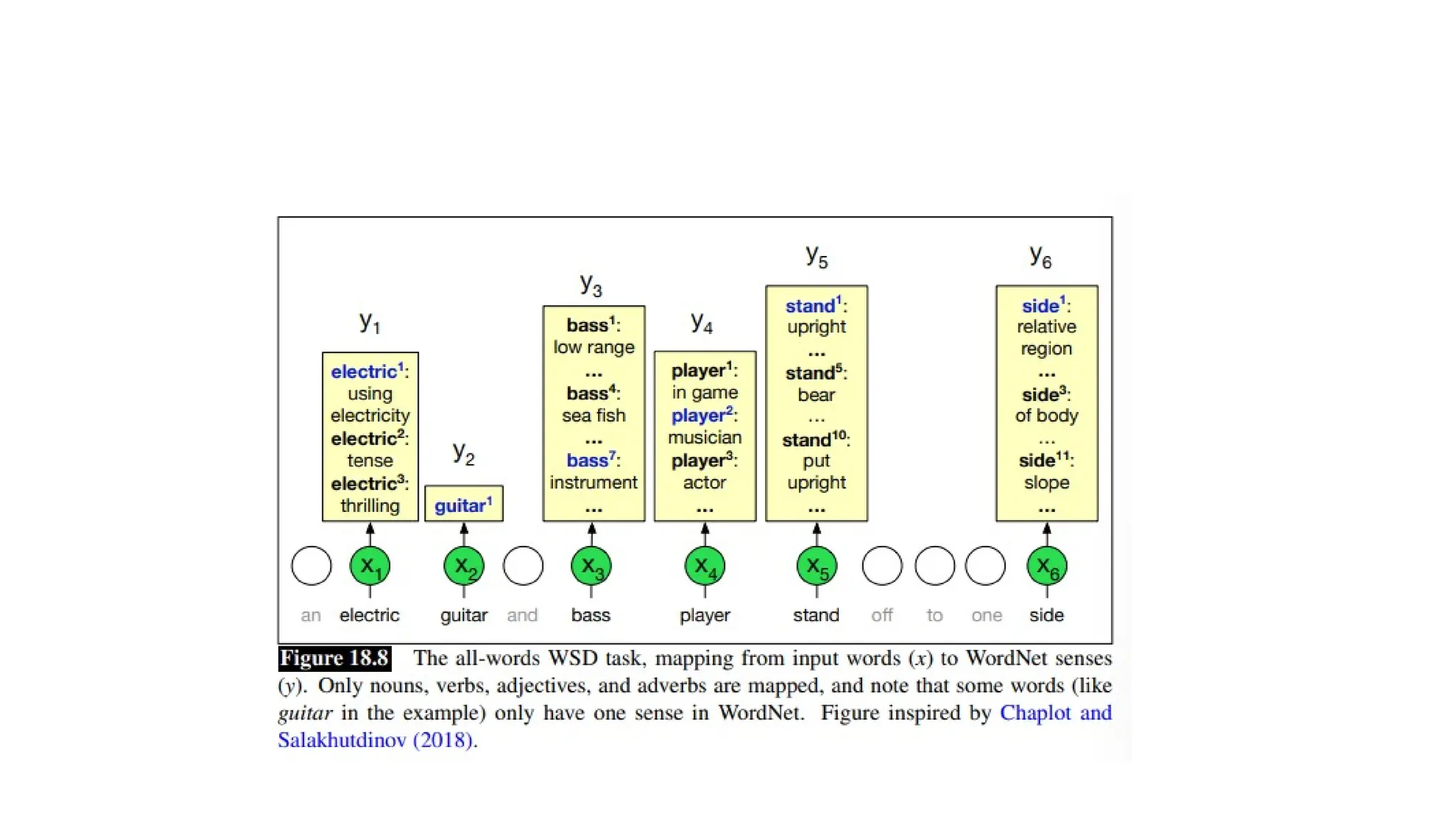
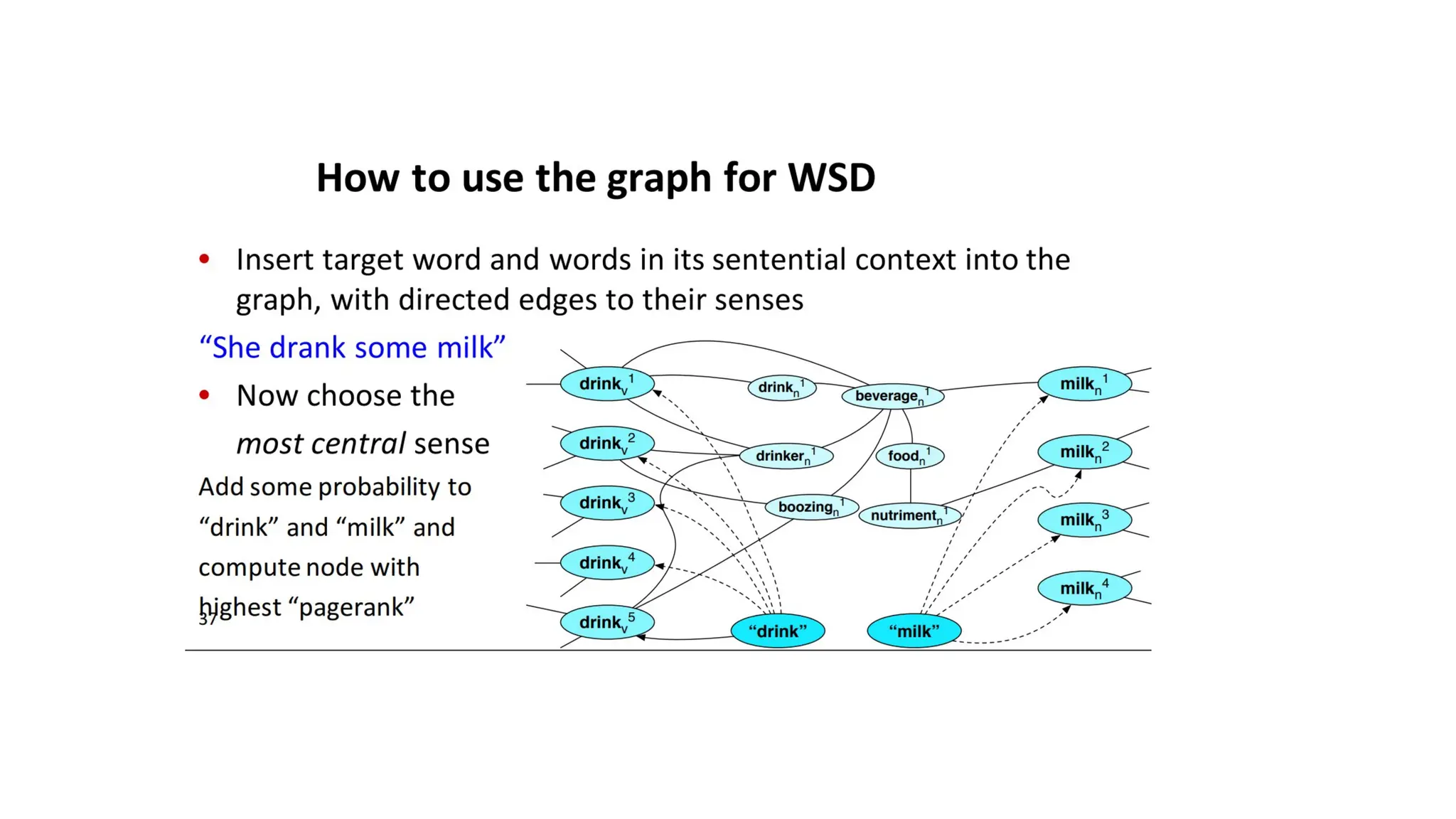
Word sense disambiguation
•The task of selecting the correct sense for a word is called word sense
disambiguation, or WSD.
• WSD algorithms take as input a word in context and a fixed inventory
word sense disambiguation WSD of potential word senses and
outputs the correct word sense in context.
28.
Word sense disambiguation– Task and
dataset
• all-words task: the system is given an entire texts and a lexicon with an
inventory of senses for each entry and we have to disambiguate every
word in the text (or sometimes just every content word).
29.
Word sense disambiguation– Task and
dataset
• Supervised all-word disambiguation tasks are generally trained from a
semantic concordance, a corpus in which each open-class word in each
sentence is labeled semantic concordance with its word sense from a
specific dictionary or thesaurus, most often WordNet
41.
WSD BASELINE
• MostFrequent Sense:
• each word from the senses in a labeled corpus
• For WordNet, this corresponds to the first sense, since senses in
WordNet are generally ordered from most frequent to least frequent
based on their counts in the SemCor sense-tagged corpus.
• The most frequent sense baseline can be quite accurate, and is
therefore often used as a default, to supply a word sense when a
supervised algorithm has insufficient training data.
42.
WSD BASELINE
• Onesense per discourse:
• a word appearing multiple times in a text or discourse often appears
with the same sense.
• Hold better for homonymy.
43.
WSD ALGORITHM –CONTEXTUAL
EMBEDDING
• At training time we pass each sentence in the SemCore labeled
dataset through any contextual embedding resulting in a contextual
embedding for each labeled token in SemCore.
• sense embedding vs
• token of sense ci
44.
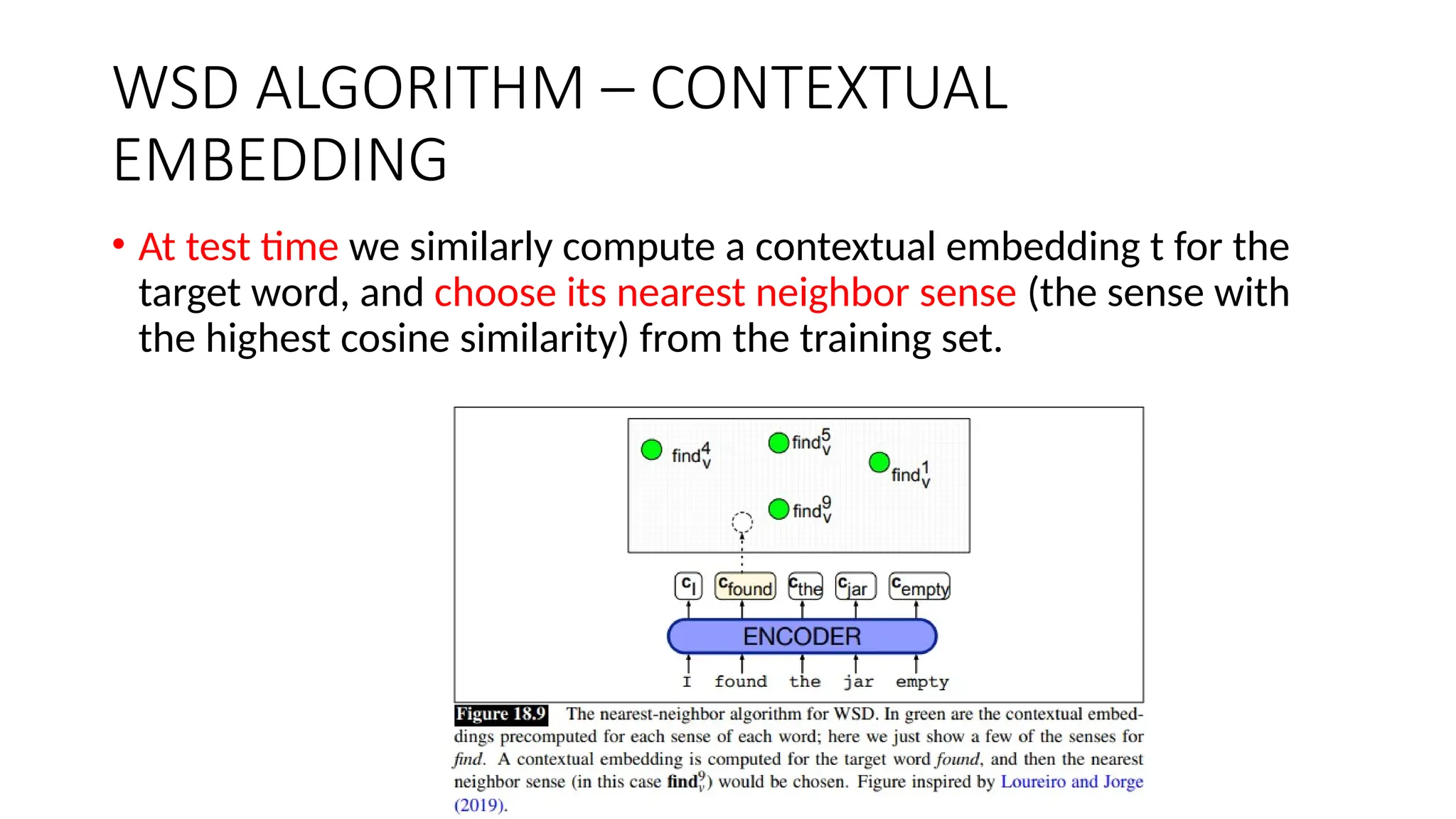
WSD ALGORITHM –CONTEXTUAL
EMBEDDING
• At test time we similarly compute a contextual embedding t for the
target word, and choose its nearest neighbor sense (the sense with
the highest cosine similarity) from the training set.
Dan Jurafsky
Classification Methods:
SupervisedMachine Learning
• Input:
• a word w in a text window d (which we’ll call a “document”)
• a fixed set of classes C = {c1, c2,…, cJ}
• A training set of m hand-labeled
‐ text windows again called
“documents” (d1,c1),....,(dm,cm)
• Output:
• a learned classifier γ:d c
22
50.
Dan Jurafsky
Classification Methods:
SupervisedMachine Learning
• Any kind of classifier
• Naive Bayes
• Logistic regression
• Neural Networks
• Support-vector
‐ machines
• k-Nearest
‐ Neighbors
• …
The Simplified Leskalgorithm
• Labeled corpora is expensive and difficult
• An alternative class of WSD algorithms, knowledge-based algorithms, rely
on knowledge-based wordnet or other such resources and don’t require
labeled data.
• While supervised algorithms generally work better, knowledge-based
methods can be used in languages or domains where thesauruses or
dictionaries but not sense labeled corpora are available.
• The lesk algorithm is the oldest and most powerful knowledge-based wsd
method, and is a useful baseline.
• Lesk is really a family of algorithms that choose the sense whose
dictionary gloss or definition shares the most words with the target
word’s neighborhood.
68.
WSD-Word-in-Context Evaluation
• Wecan think of WSD as a kind of contextualized similarity task, since
our goal is to be able to distinguish the meaning of a word like bass in
one context (playing music) from another context (fishing).
• Here the system is given two sentences, each with the same target
word but in a different sentential context
• The system must decide whether the target words are used in the
same sense in the two sentences or in a different sense.
70.
• In Word-in-context,first cluster the word senses into coarser clusters,
so that the two sentential contexts for the target word are marked as T
if the two senses are in the same cluster.
71.
• In Word-in-context,first cluster the word senses into coarser clusters,
so that the two sentential contexts for the target word are marked as T
if the two senses are in the same cluster.
?
?
72.
• In Word-in-context,first cluster the word senses into coarser clusters,
so that the two sentential contexts for the target word are marked as T
if the two senses are in the same cluster.
73.
WSD- Wikipedia asa source of training data
• One important direction is to use Wikipedia as a source of sense-
labeled data.
• When a concept is mentioned in a Wikipedia article, the article text
may contain an explicit link to the concept’s Wikipedia page, which is
named by a unique identifier.
• This link can be used as a sense annotation.
• These sentences can then be added to the training data for a
supervised system
WORD SIMILARITY
• Vectorssemantics is the standard way to represent word meaning in
NLP
• vector semantics is to represent a word as a point in a
multidimensional semantic space that is derived (in ways we’ll see)
from the distributions of embeddings word neighbors.
76.
WORD SIMILARITY
• Forexample, suppose you didn’t know the meaning of the word ongchoi (a
recent borrowing from Cantonese) but you see it in the following contexts:
(6.1) Ongchoi is delicious sauteed with garlic.
• (6.2) Ongchoi is superb over rice.
• (6.3) Ongchoi leaves with salty sauces...
77.
WORD SIMILARITY
• Forexample, suppose you didn’t know the meaning of the word ongchoi (a
recent borrowing from Cantonese) but you see it in the following contexts:
(6.1) Ongchoi is delicious sauteed with garlic.
• (6.2) Ongchoi is superb over rice.
• (6.3) Ongchoi leaves with salty sauces...
• And suppose that you had seen many of these context words in other
contexts:
• (6.4) ...spinach sauteed with garlic over rice...
• (6.5) ...chard stems and leaves are delicious...
• (6.6) ...collard greens and other salty leafy greens
78.
WORD SIMILARITY
• Forexample, suppose you didn’t know the meaning of the word ongchoi (a
recent borrowing from Cantonese) but you see it in the following contexts:
(6.1) Ongchoi is delicious sauteed with garlic.
• (6.2) Ongchoi is superb over rice.
• (6.3) Ongchoi leaves with salty sauces...
• And suppose that you had seen many of these context words in other
contexts:
• (6.4) ...spinach sauteed with garlic over rice...
• (6.5) ...chard stems and leaves are delicious...
• (6.6) ...collard greens and other salty leafy greens
ongchoi is a leafy green similar to these other leafy greens
80.
Vectors and documents
•a term-document matrix: each row represents a word in the vocabulary and
each term-document matrix column represents a document from some
collection of documents
WORDS
DOCUMENTS
81.
• A vectorspace is a collection of vectors, characterized by their dimension
dimension.
• The ordering of the numbers in a vector space indicates different meaningful
dimensions on which documents vary.
83.
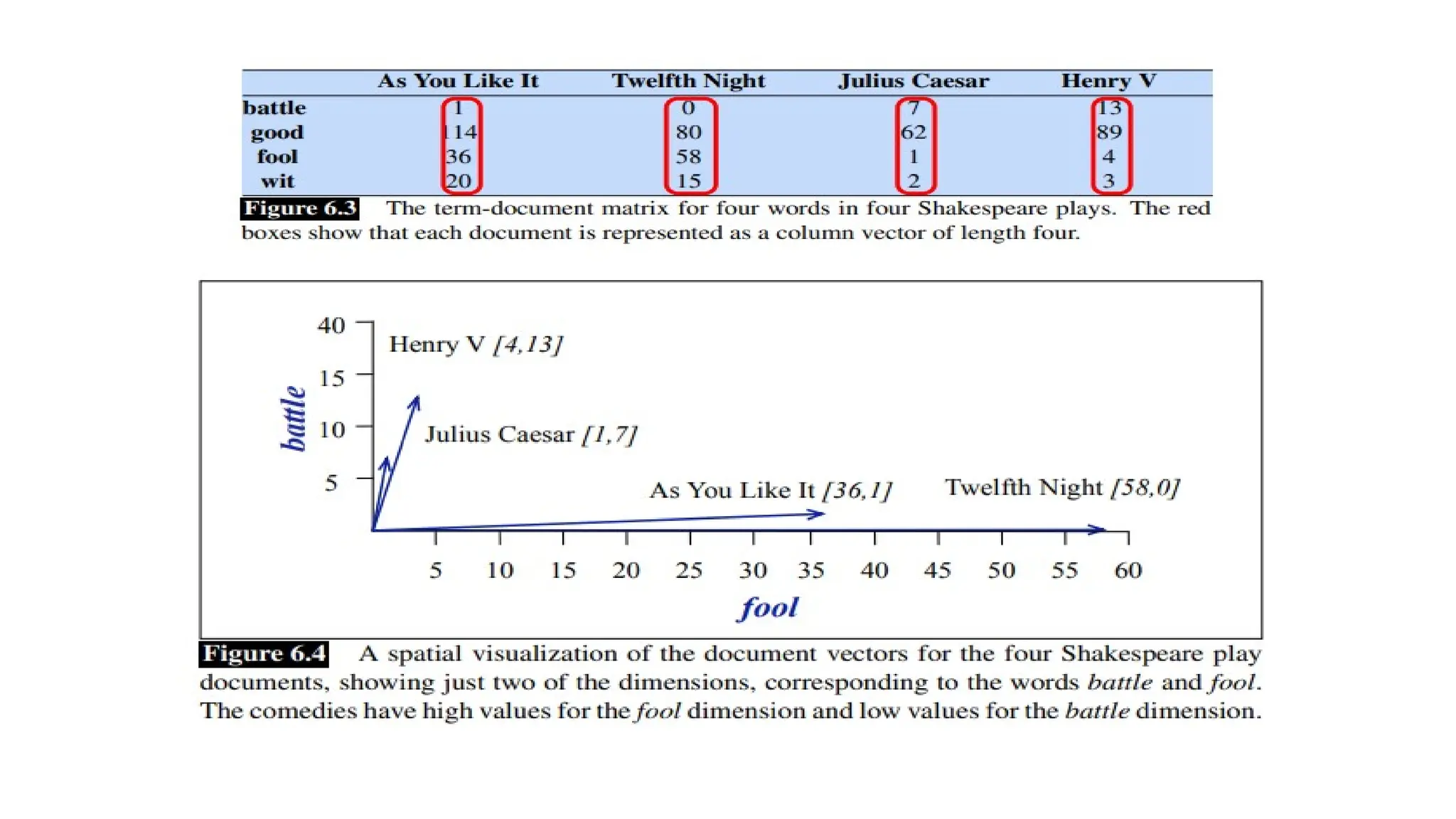
• Term-document matriceswere originally defined as a means of finding similar
documents for the task of document information retrieval.
• Two documents that are similar will tend to have similar words, and if two
documents have similar words their column vectors will tend to be similar.
• The vectors for the comedies As You Like It [1,114,36,20] and Twelfth Night
[0,80,58,15] look a lot more like each other (more fools and wit than battles)
than they look like Julius Caesar [7,62,1,2] or Henry V [13,89,4,3].
84.
Words as vectors:document dimensions
wit, [20,15,2,3]; battle, [1,0,7,13]; and good = ?; fool= ?
85.
Words as vectors:document dimensions
wit, [20,15,2,3]; battle, [1,0,7,13]; and good [114,80,62,89]; fool, [36,58,1,4]
86.
Words as vectors:word dimensions
Word-word matrix or the term-context matrix: The columns are labeled by words
rather than documents
87.
Retrieval in vectorspace model
• Query q is represented in the same way or slightly
differently.
• Relevance of di to q: Compare the similarity of query q
and document di.
• Cosine similarity (the cosine of the angle between the
two vectors)
• Cosine is also commonly used in text clustering
89
88.
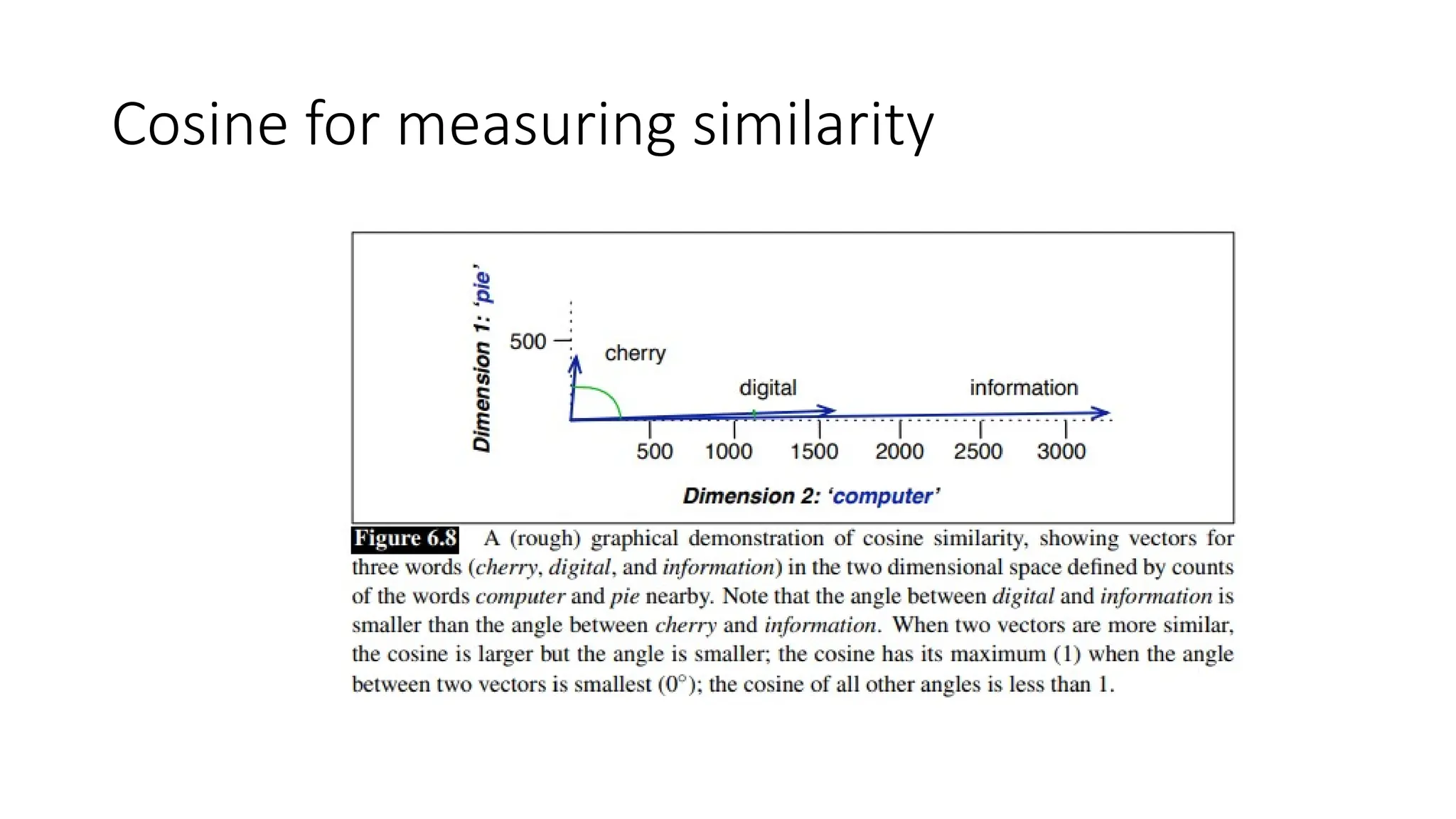
Cosine for measuringsimilarity
• To measure the similarity between two target words v and w, we need a metric
that takes two vectors (of the same dimensionality, either both with words as
dimensions
• By far the most common similarity metric is the cosine of the angle between the
vectors
An Example
• Adocument space is defined by three terms:
• hardware, software, users
• the vocabulary
• A set of documents are defined as:
• A1=(1, 0, 0), A2=(0, 1, 0), A3=(0, 0, 1)
• A4=(1, 1, 0), A5=(1, 0, 1), A6=(0, 1, 1)
• A7=(1, 1, 1) A8=(1, 0, 1). A9=(0, 1, 1)
• If the Query is “hardware and software”
• what documents should be retrieved?
95
#13 A holonym is a word that refers to a complete thing, while another word represents a part of that thing.
In natural language processing (NLP), holonymy can help improve the understanding and interpretation of human language. For example, if you search for "air_bag" but can't remember the name, you can search for "car" instead and the results may include "air_bag".
a term that denotes part of something but is used to refer to the whole of it, e.g. faces when used to mean people in I see several familiar faces present.
#15 Pertainyms are usually defined by phrases like "of or pertaining to" and do not have antonyms.








































































![• Term-document matrices were originally defined as a means of finding similar
documents for the task of document information retrieval.
• Two documents that are similar will tend to have similar words, and if two
documents have similar words their column vectors will tend to be similar.
• The vectors for the comedies As You Like It [1,114,36,20] and Twelfth Night
[0,80,58,15] look a lot more like each other (more fools and wit than battles)
than they look like Julius Caesar [7,62,1,2] or Henry V [13,89,4,3].](https://image.slidesharecdn.com/module4-1-250727114739-99513b6b/75/Module-4-1-of-chennai-s-slides-wo-hanve-dot-do-thhopps-otps-83-2048.jpg)
![Words as vectors: document dimensions
wit, [20,15,2,3]; battle, [1,0,7,13]; and good = ?; fool= ?](https://image.slidesharecdn.com/module4-1-250727114739-99513b6b/75/Module-4-1-of-chennai-s-slides-wo-hanve-dot-do-thhopps-otps-84-2048.jpg)
![Words as vectors: document dimensions
wit, [20,15,2,3]; battle, [1,0,7,13]; and good [114,80,62,89]; fool, [36,58,1,4]](https://image.slidesharecdn.com/module4-1-250727114739-99513b6b/75/Module-4-1-of-chennai-s-slides-wo-hanve-dot-do-thhopps-otps-85-2048.jpg)