Downloaded 110 times





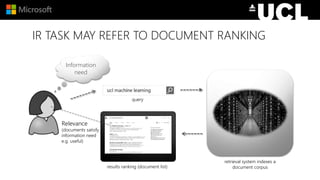

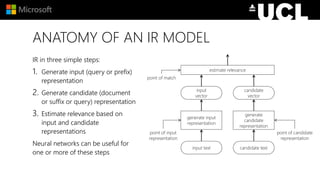







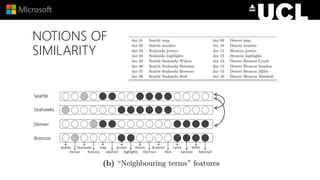




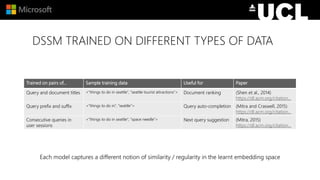





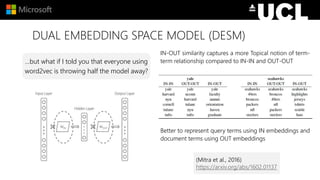


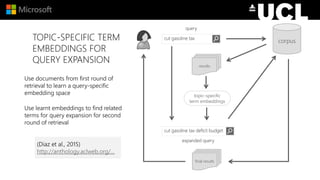




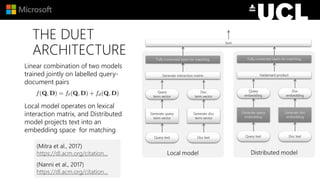
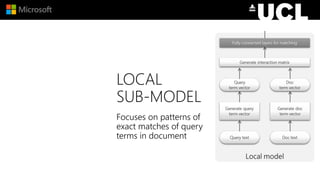

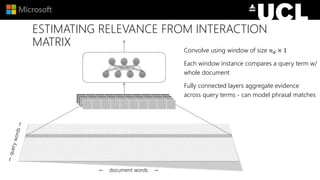
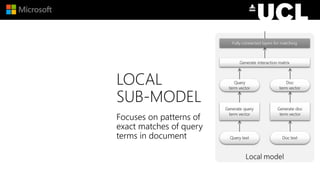
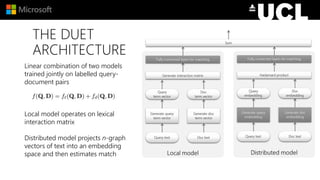
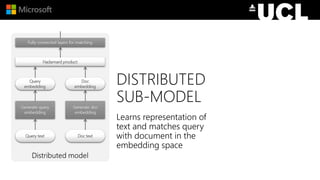
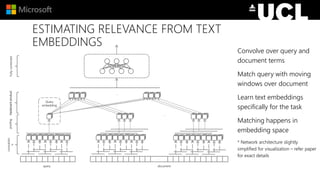
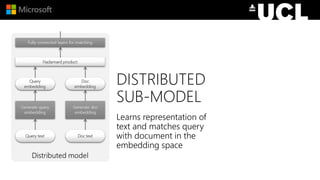
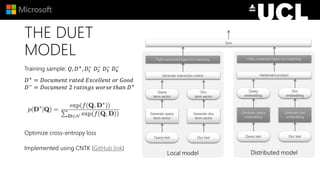
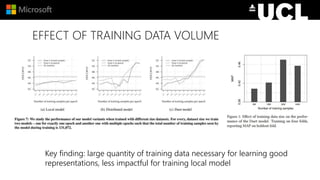

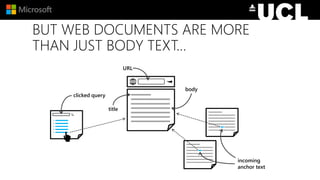

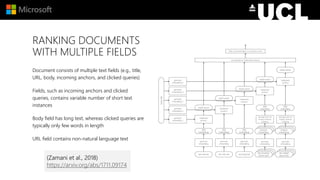
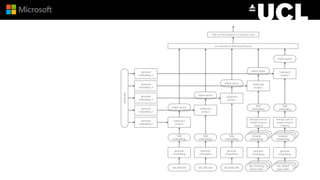
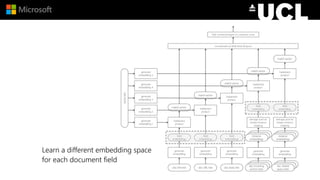
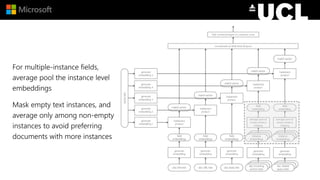
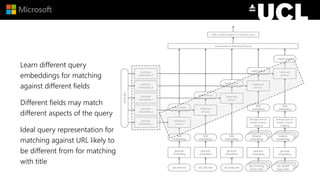
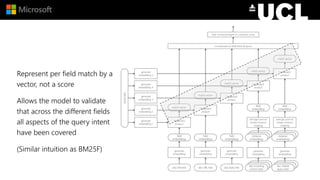
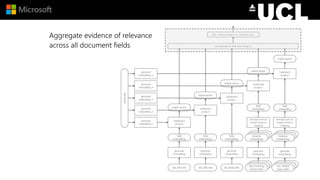
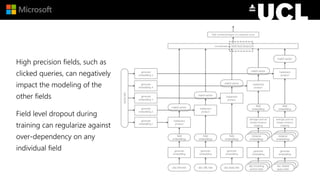





The document discusses advancements in neural models for information retrieval (IR), emphasizing the importance of neural networks in creating effective representation learning methods tailored for various IR tasks. It explains how neural networks can enhance document ranking, query auto-completion, and next query suggestions by learning from patterns of relevance and embedding representations. Furthermore, it covers the architecture of models like the duet model and their application in dealing with the challenges of short versus long text retrieval.






















































































