Downloaded 13 times

![DataLake
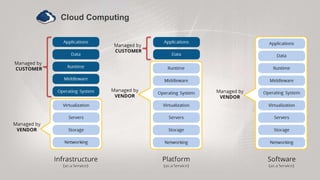
Method of Storing Data within a System or Repository
DataLakeCharacteristics
- Structured= Relational Databases [Rows & Columns]
- Semi-Structured= CSV, Logs, XML, JSON
- Unstructured = Emails, Documents, Binaries, Audio, Video, PDFs
- Open-Source = Apache Hadoop [HDFS]
- Microsoft Azure = Azure Data Lake Store [ADLS]
- AmazonAWS = Amazon S3
Usedfor
- Reporting
- Visualization
- Analytics
- Machine Learning
SingleStore of Data in Enterprise Ranging from Raw Data [Copy of SourceSystem]
CentralizedData Store for Enterprises](https://image.slidesharecdn.com/nugoskip-level-14092018-180914222346/85/Digital-Transformation-with-Microsoft-Azure-10-320.jpg)


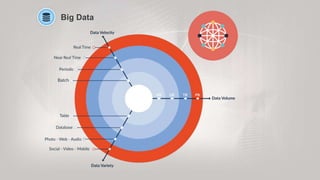
![Drill Inspired by Google'sDremel [Big Query]
https://research.google.com/pubs/pub36632.html
https://cloud.google.com/bigquery/
Schema-Free SQL Query Engine for Hadoop, NoSQL & Storage
Query Engine [ANSI-SQL] for Big Data [Raw] Exploration
For Analysts, Business Users, DataScientists & DataDevelopers
1. Self-Service Exploration
2. Data Agility
3. Interactive Query Response Time and Scale
Use Cases for ApacheDrill
1. Raw Data Exploration
2. Data Discovery](https://image.slidesharecdn.com/nugoskip-level-14092018-180914222346/85/Digital-Transformation-with-Microsoft-Azure-14-320.jpg)
![AzureData LakeAnalytics[ADLA]
On-DemandAnalytics Job Service
Start in Seconds, Scale Instantly and Pay per Job
Develop Massively Parallel Programs [MPP] with Simplicity
100 Hrs – R$ 332 | 500 Hrs – R$ 1.494 – by MonthlyCommitment Package
[HaaS] - Hadoop-as-a-Services
Store Destinations](https://image.slidesharecdn.com/nugoskip-level-14092018-180914222346/85/Digital-Transformation-with-Microsoft-Azure-15-320.jpg)



This document summarizes digital transformation with Microsoft Azure, including cloud computing, big data, and data lakes. It discusses data lake characteristics such as structured, semi-structured, and unstructured data. Data lakes are used for reporting, visualization, analytics, and machine learning. They provide a single store for raw and processed data ranging from raw copies of source systems to structured data for analytics. The document also briefly mentions Azure Data Lake Analytics, DataBricks, and concludes by thanking the reader.


























































![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)

