Downloaded 26 times





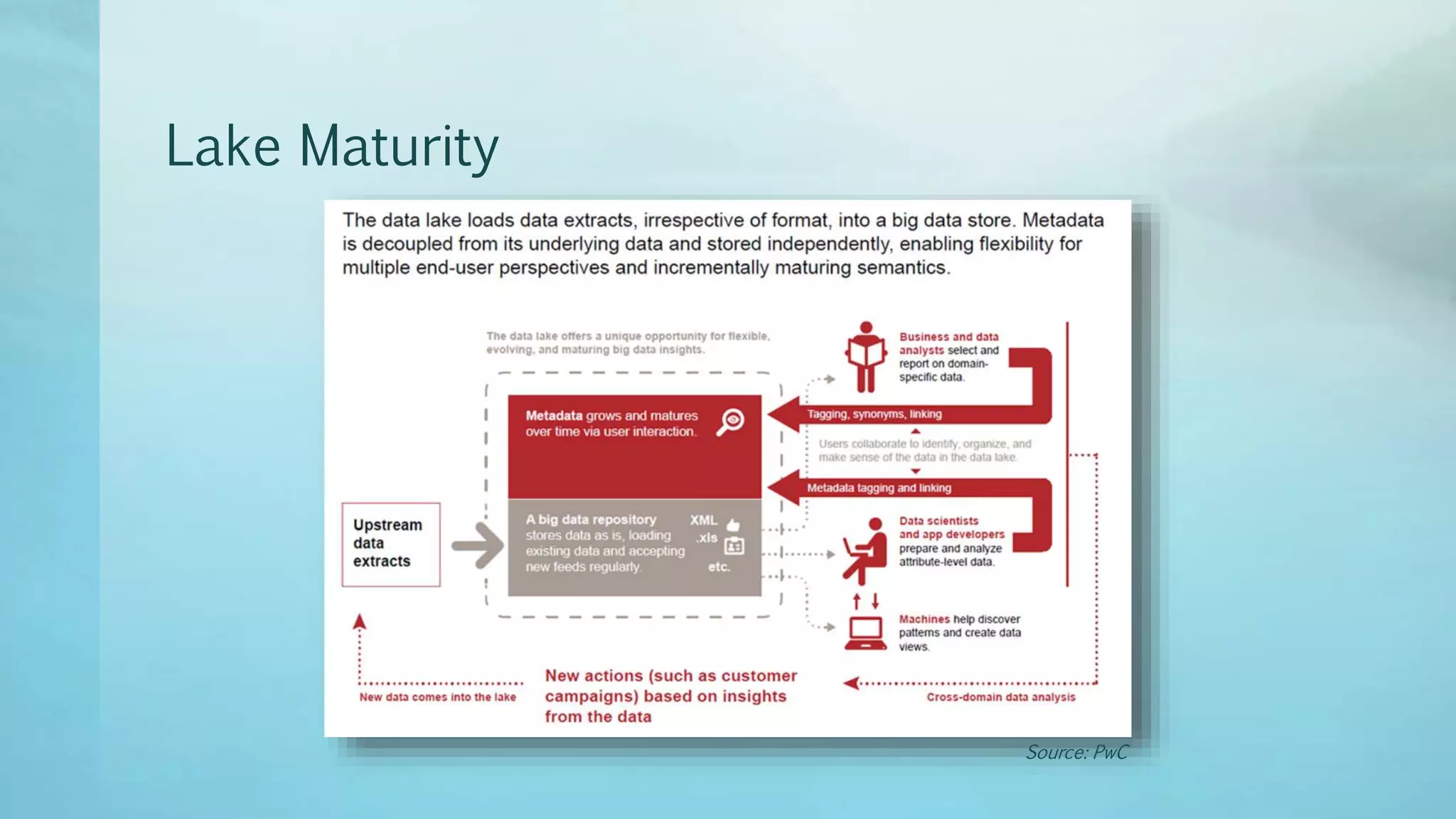






Data lakes provide a flexible way to store large amounts of raw data from various sources without having to structure the data upfront. This allows for exploration of the data and helps break down data silos. Some benefits of data lakes include flexible data modeling, low costs, and acting as a staging area for ETL. However, data lakes also face challenges around data governance, metadata, security, and information lifecycle management. As data lakes mature, organizations typically progress through four stages - from standalone applications to building new applications on a Hadoop platform centered around the flexible data lake.













































































