Download to read offline




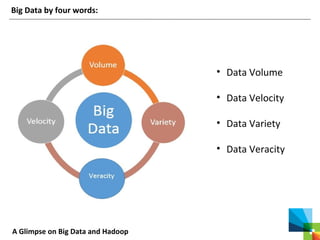

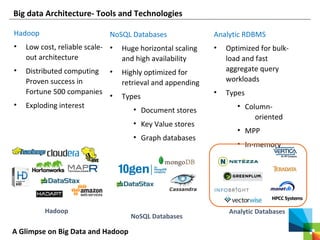


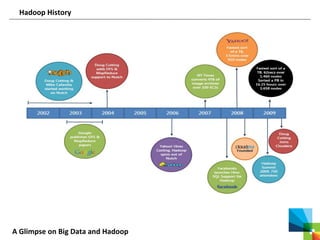



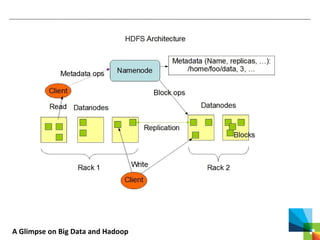

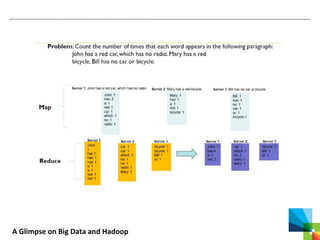


This document discusses big data and the Apache Hadoop framework. It defines big data as large, complex datasets that are difficult to process using traditional tools. Hadoop is an open-source framework for distributed storage and processing of big data across commodity hardware. It has two main components - the Hadoop Distributed File System (HDFS) for storage, and MapReduce for processing. HDFS stores data across clusters of machines with redundancy, while MapReduce splits tasks across processors and handles shuffling and sorting of data. Hadoop allows cost-effective processing of large, diverse datasets and has become a standard for big data.










































































