Download to read offline


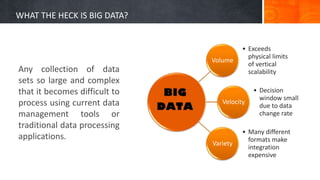
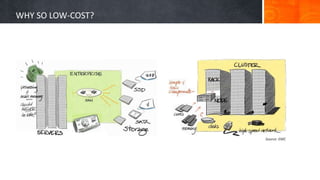
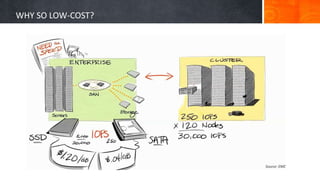


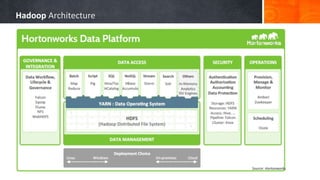


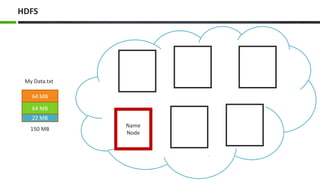

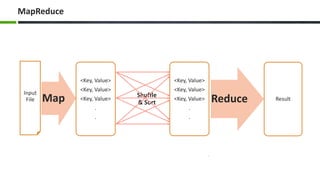

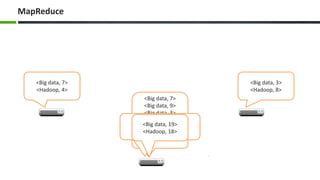




The document introduces big data, defining it as large and complex data sets that challenge traditional processing tools, highlighting its volume, velocity, and variety. It discusses Hadoop as a solution for managing big data through its architecture, including components like HDFS and MapReduce. The document concludes with an invitation for questions and feedback, emphasizing engagement in data management topics.












































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)

![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)