




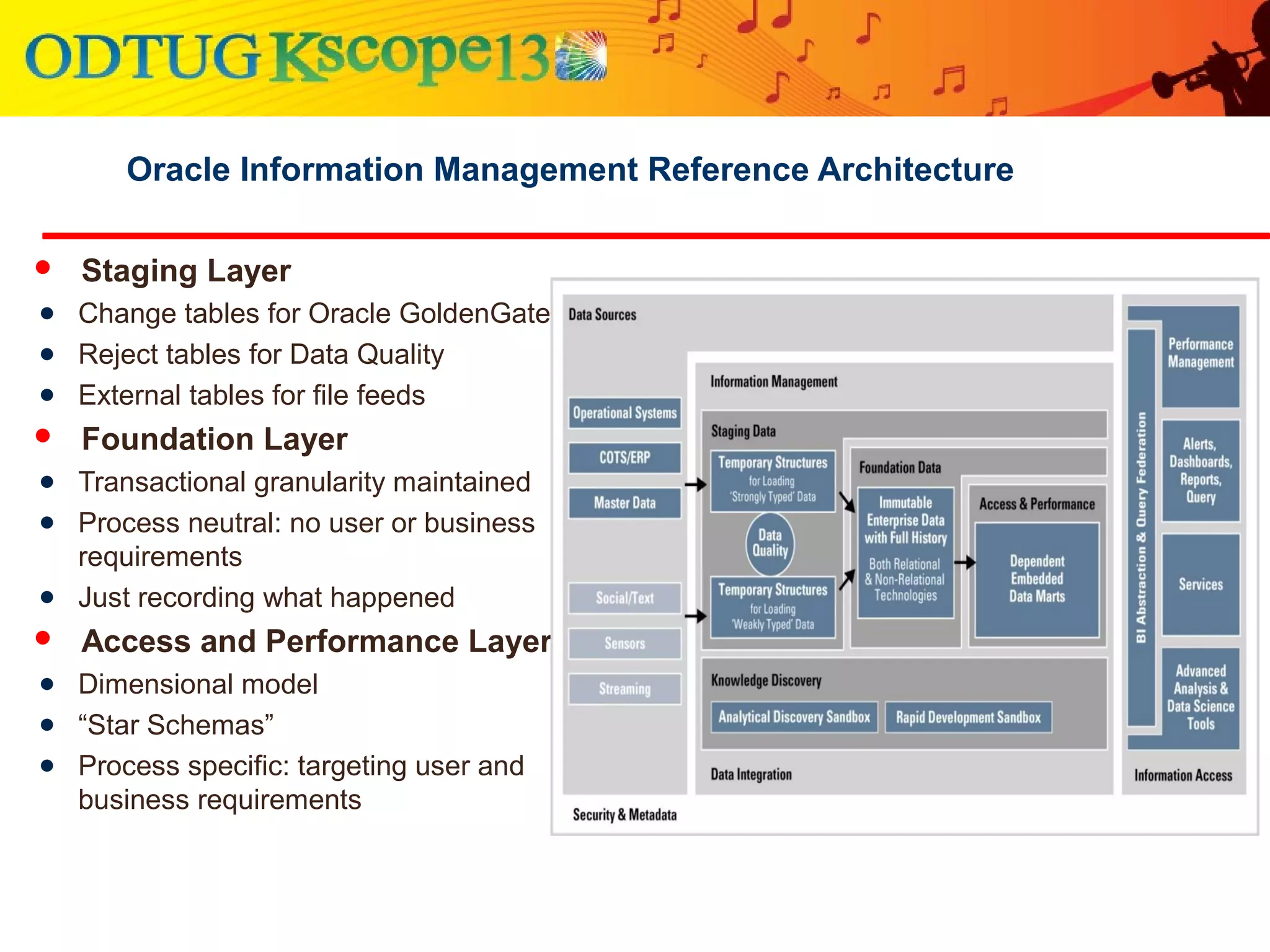


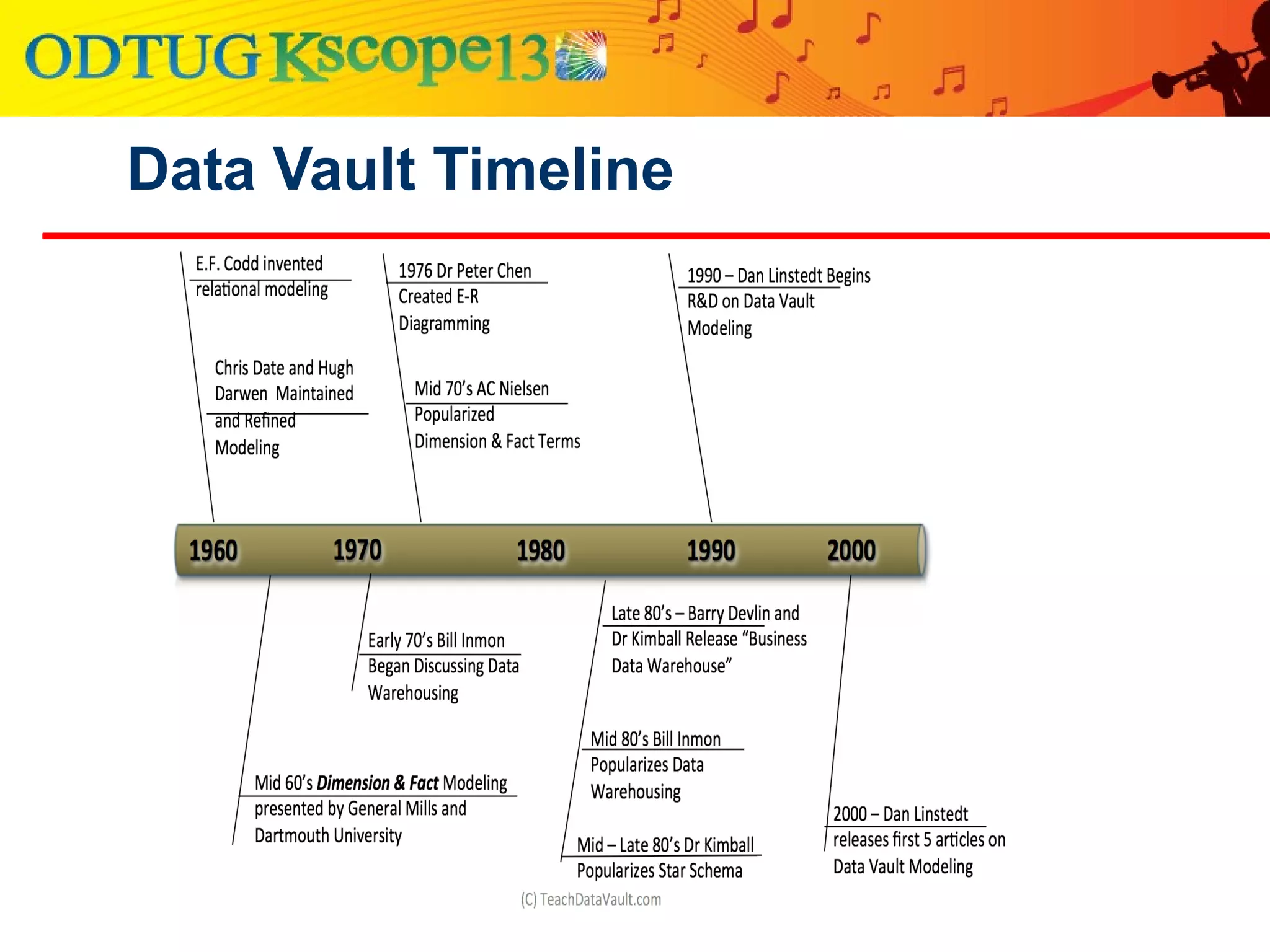
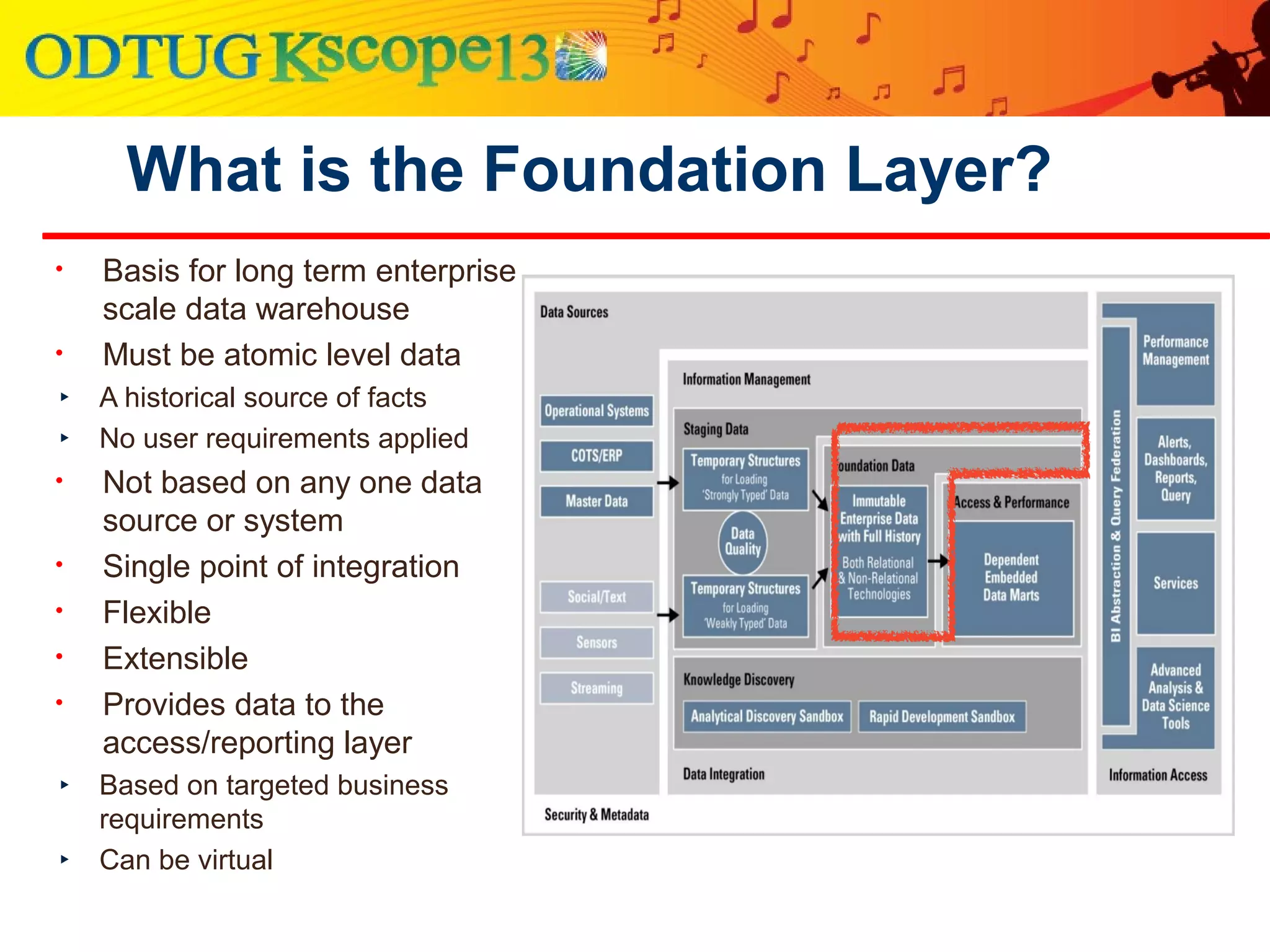






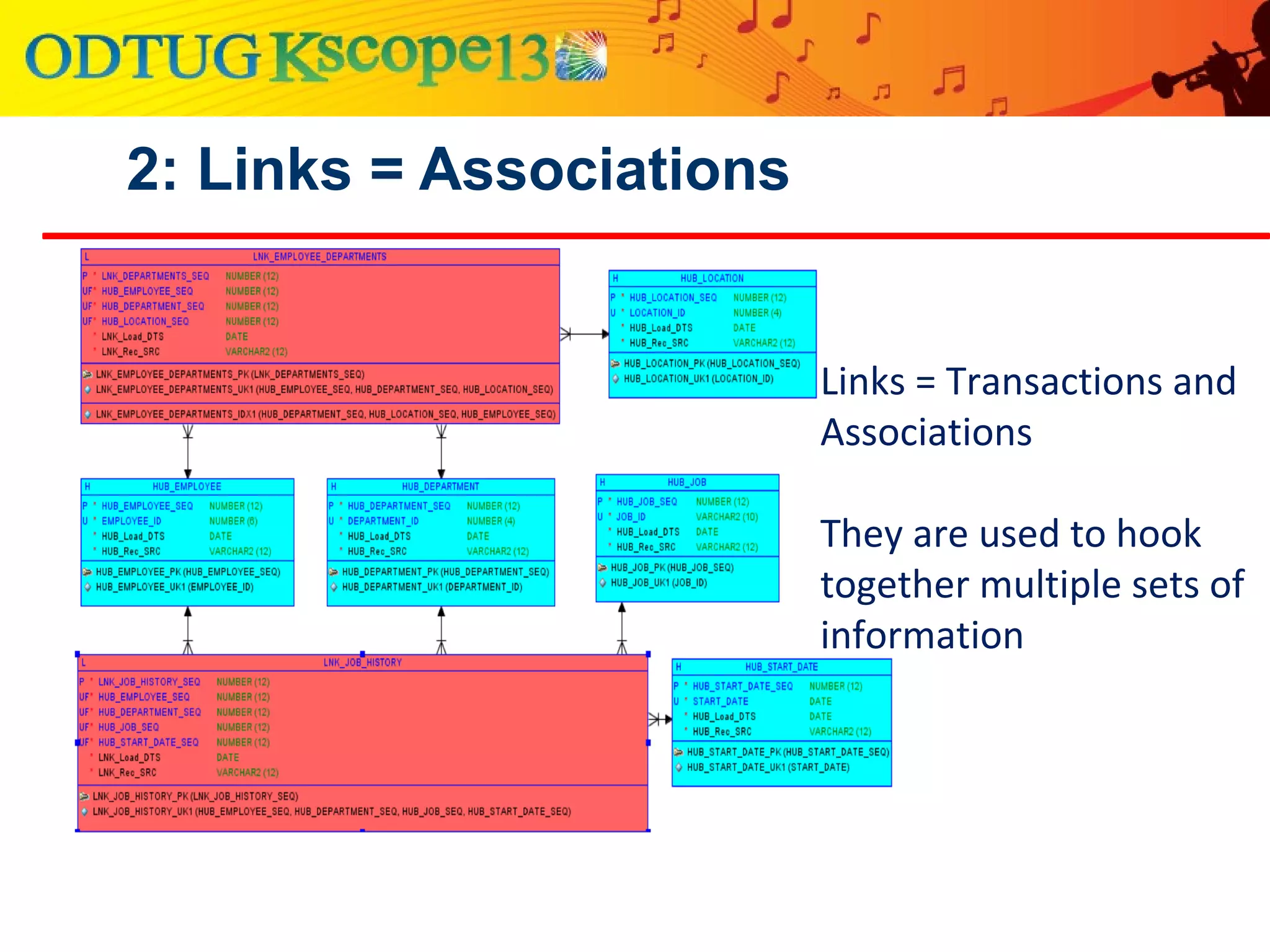

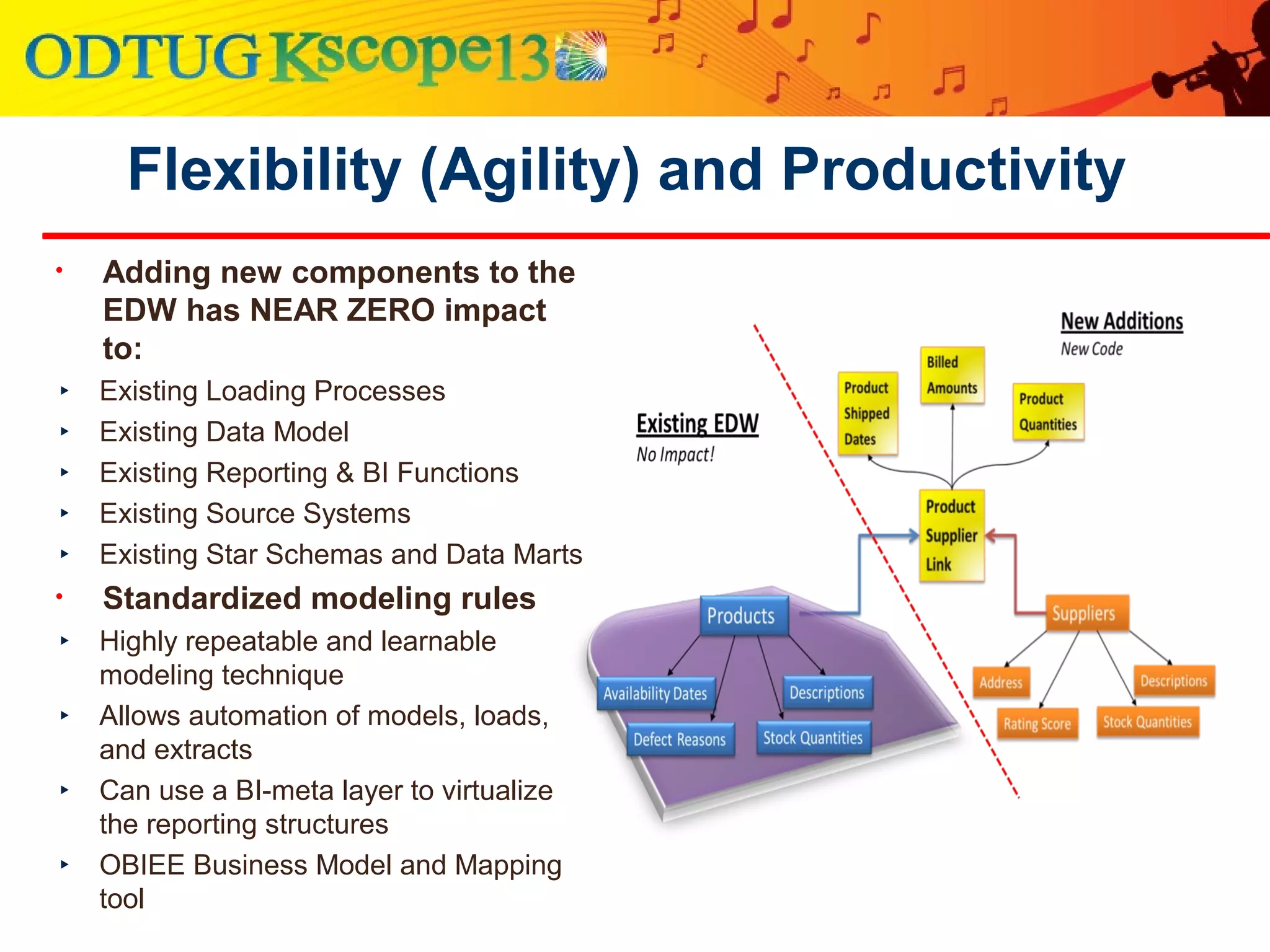

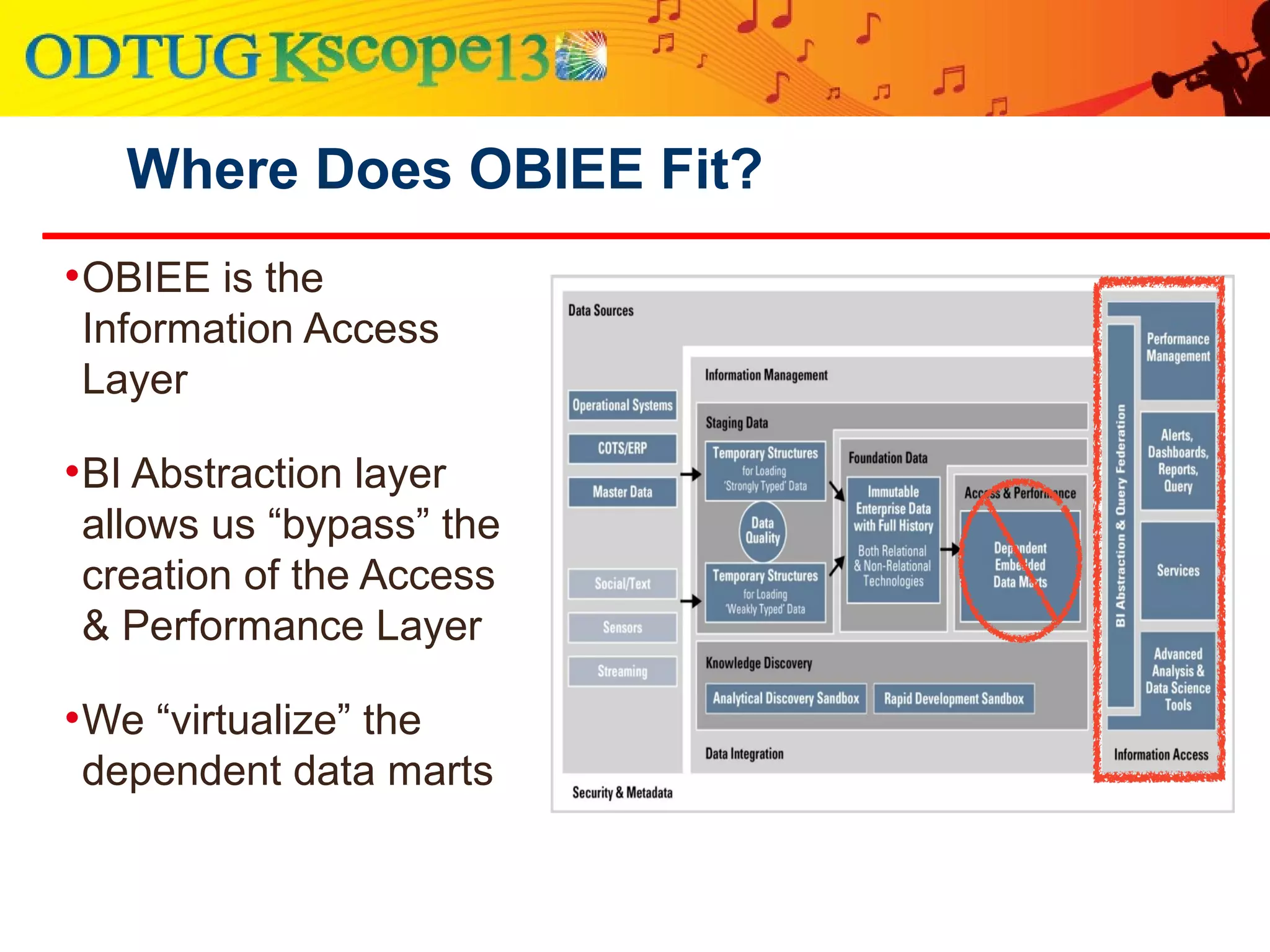
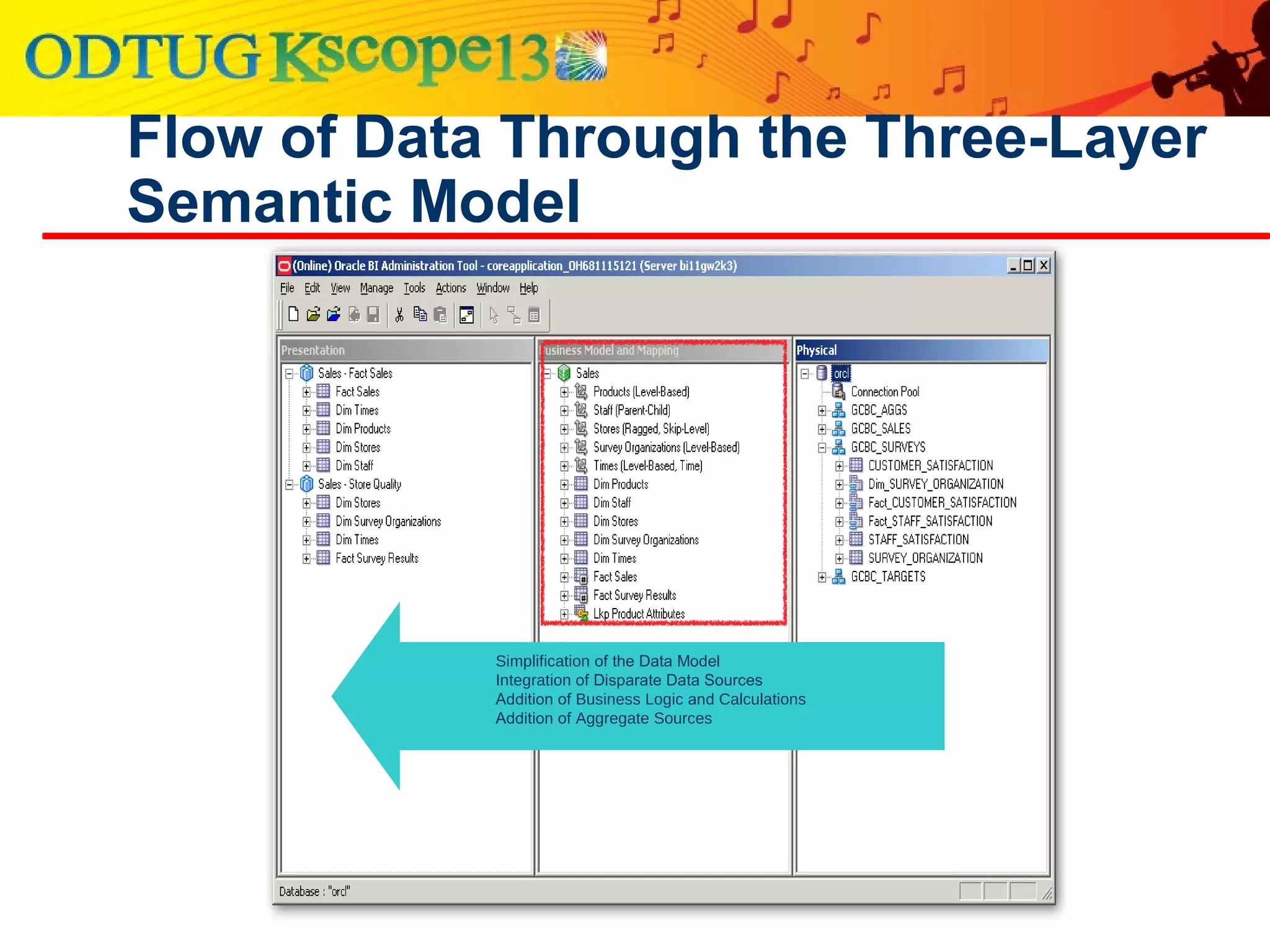
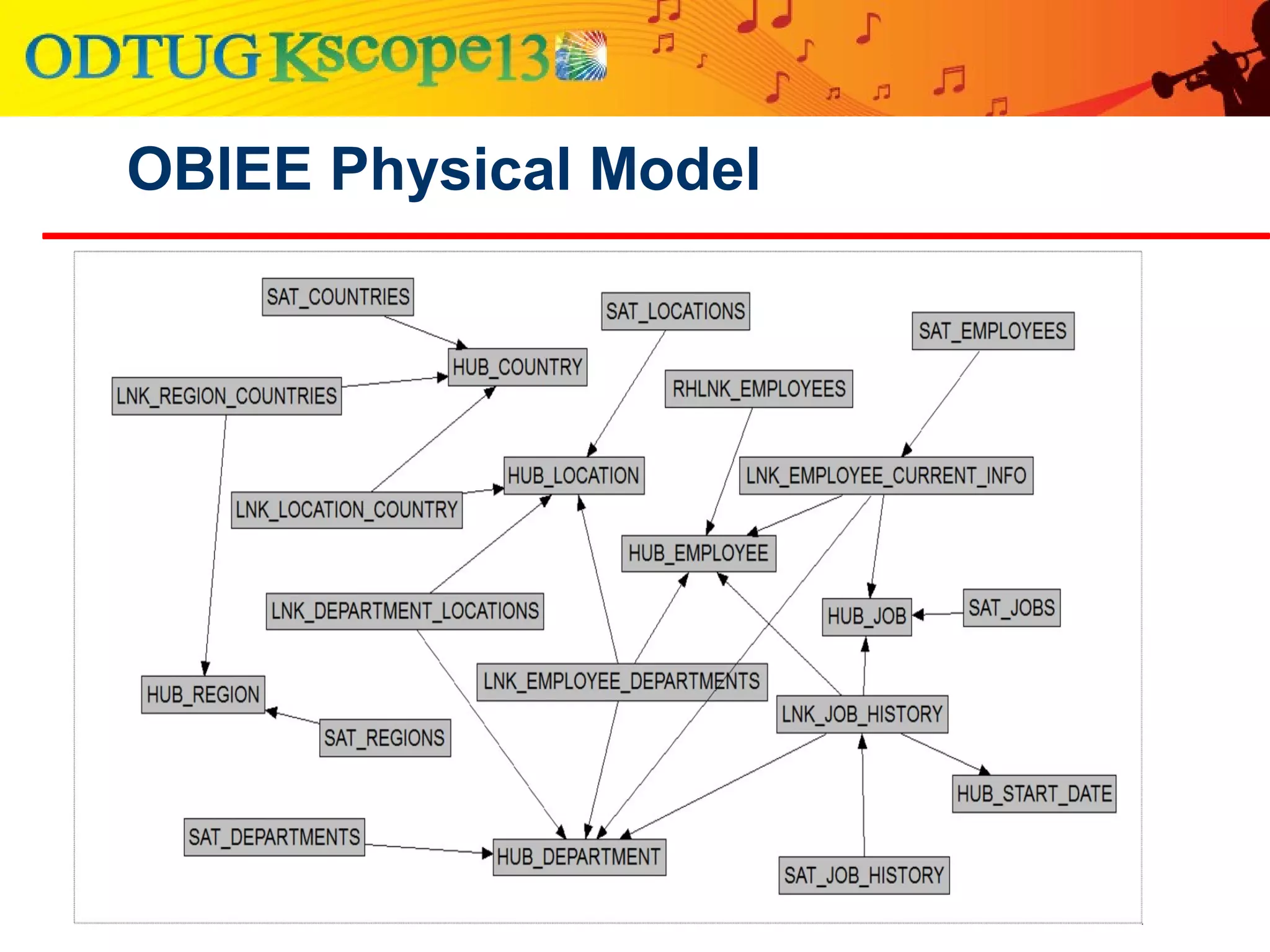
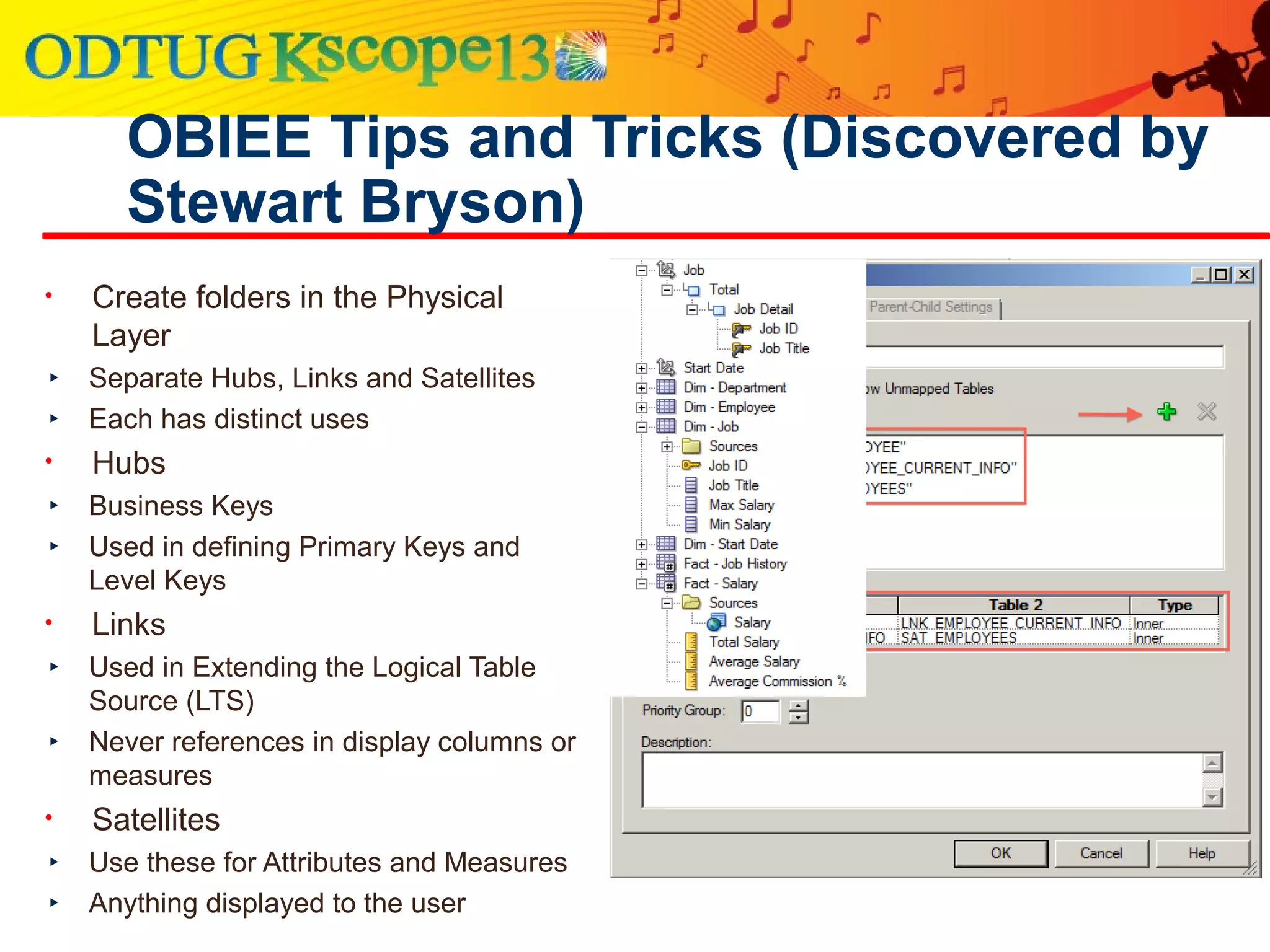
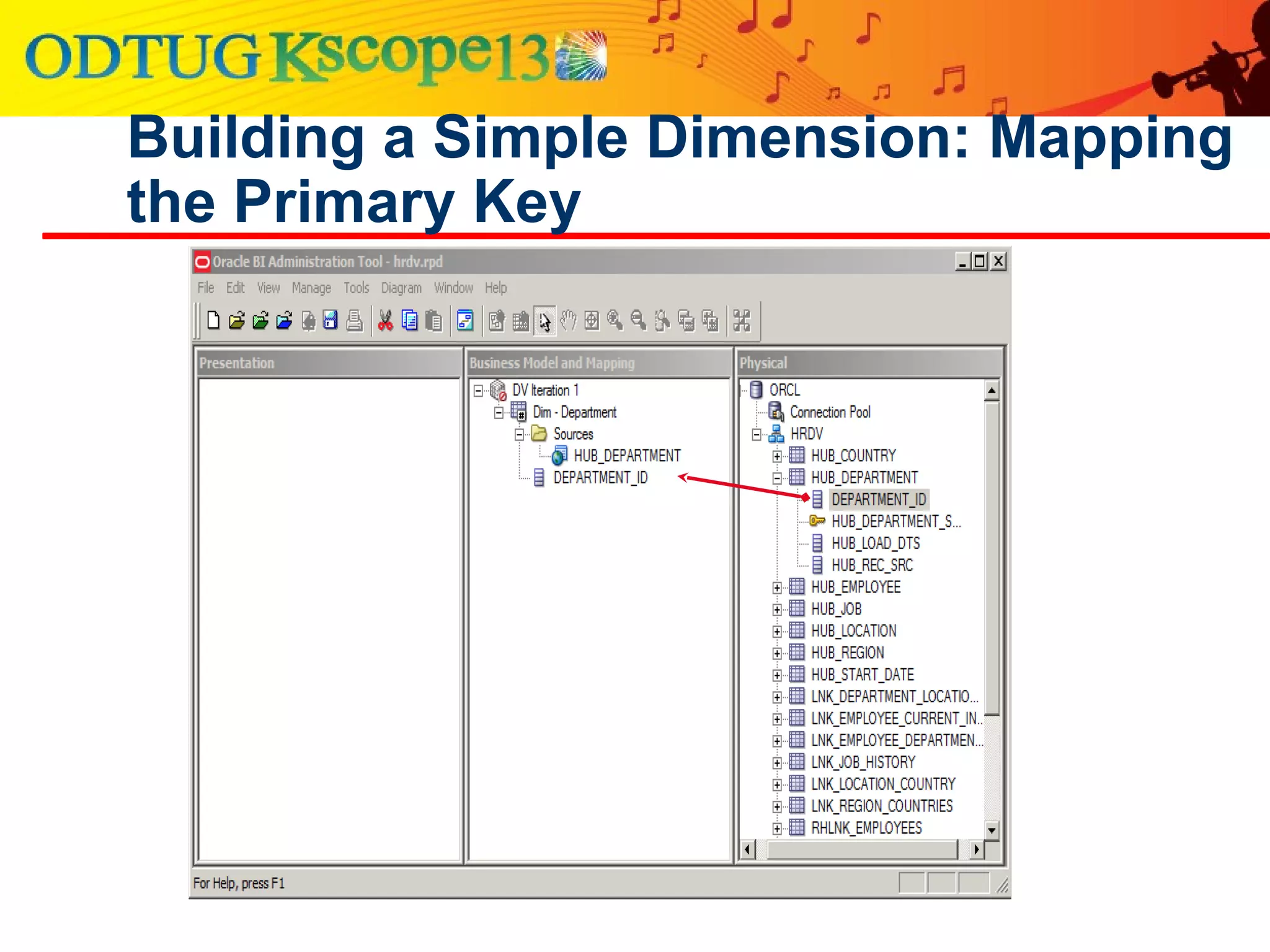
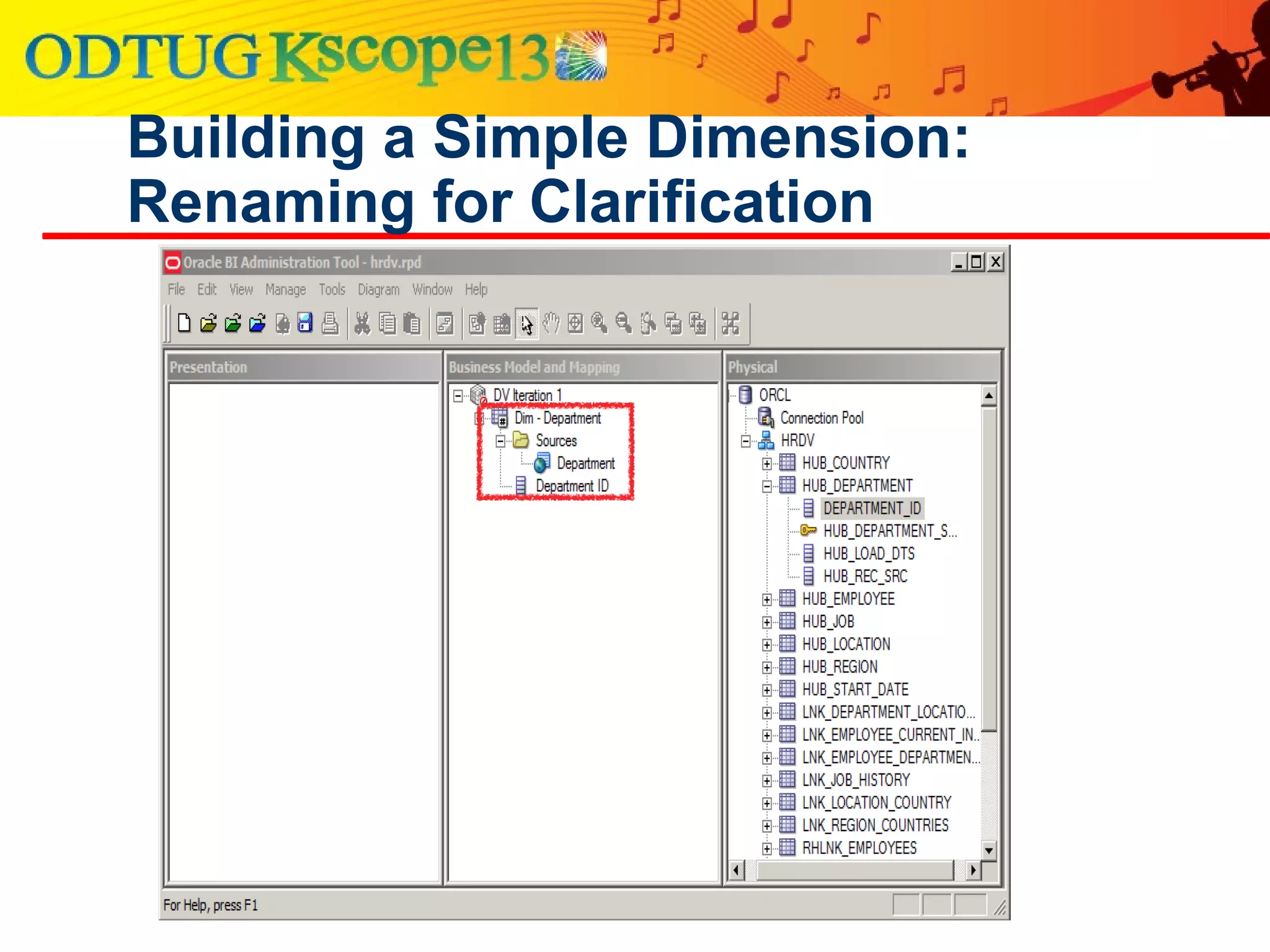
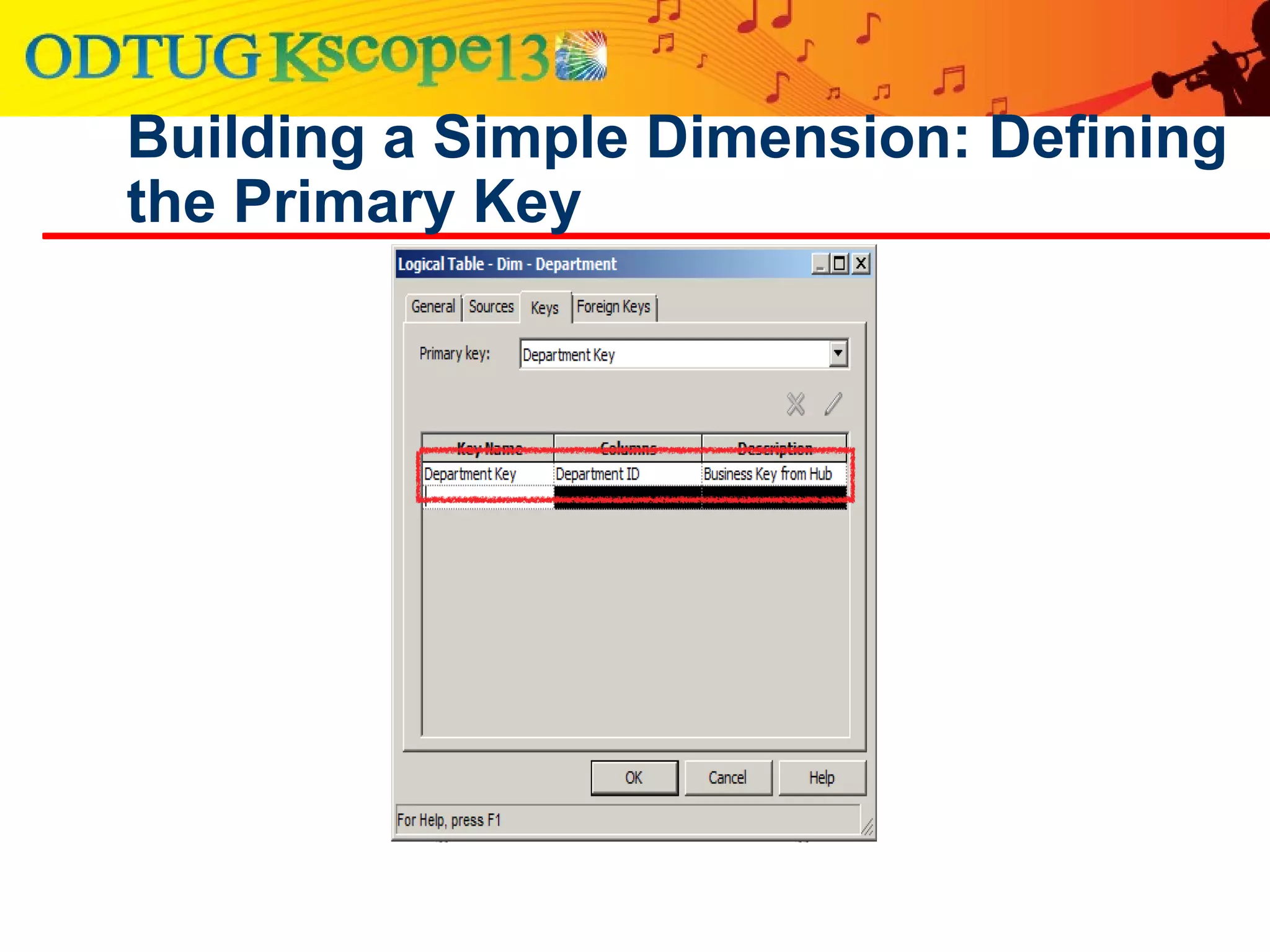
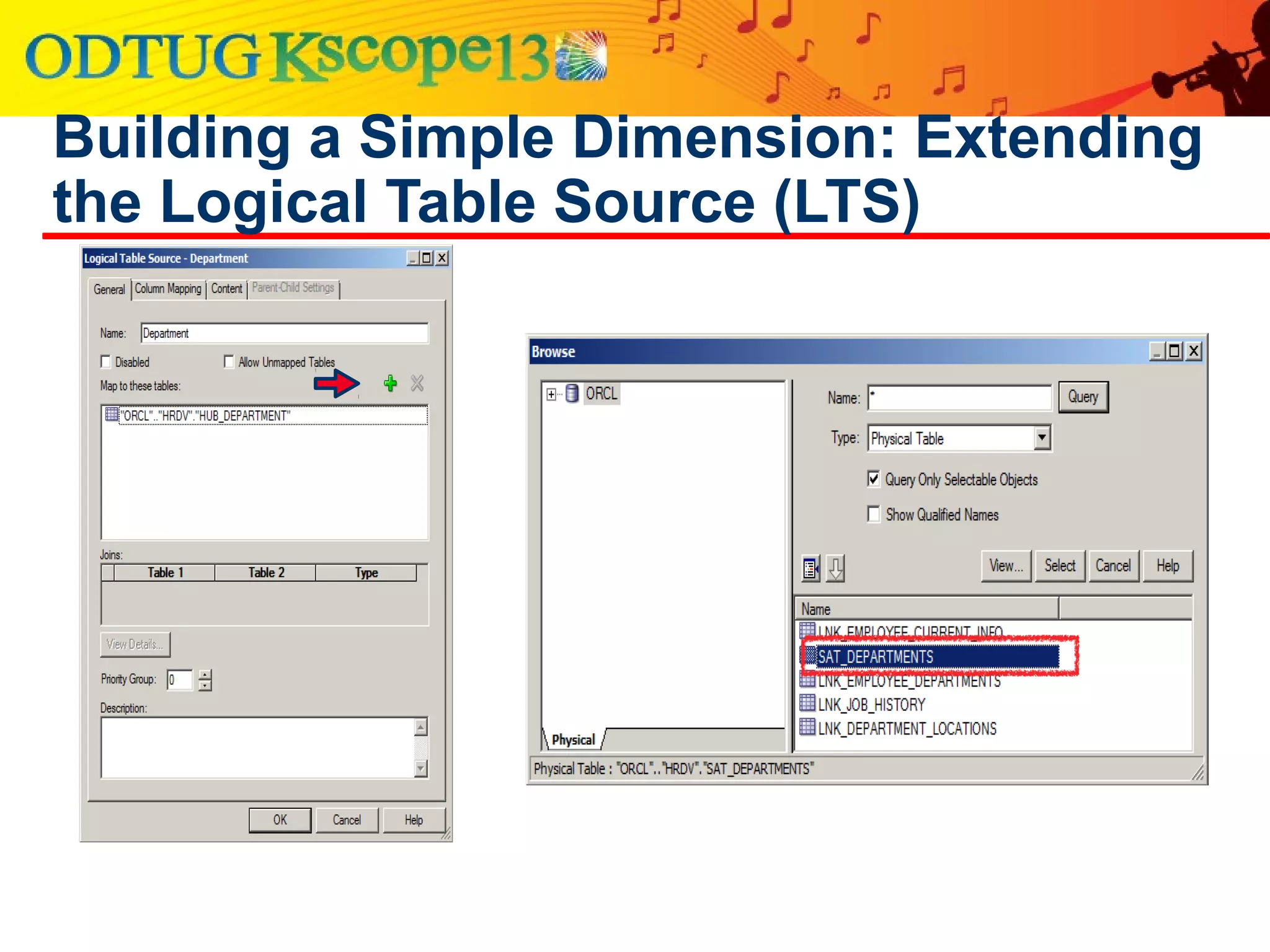
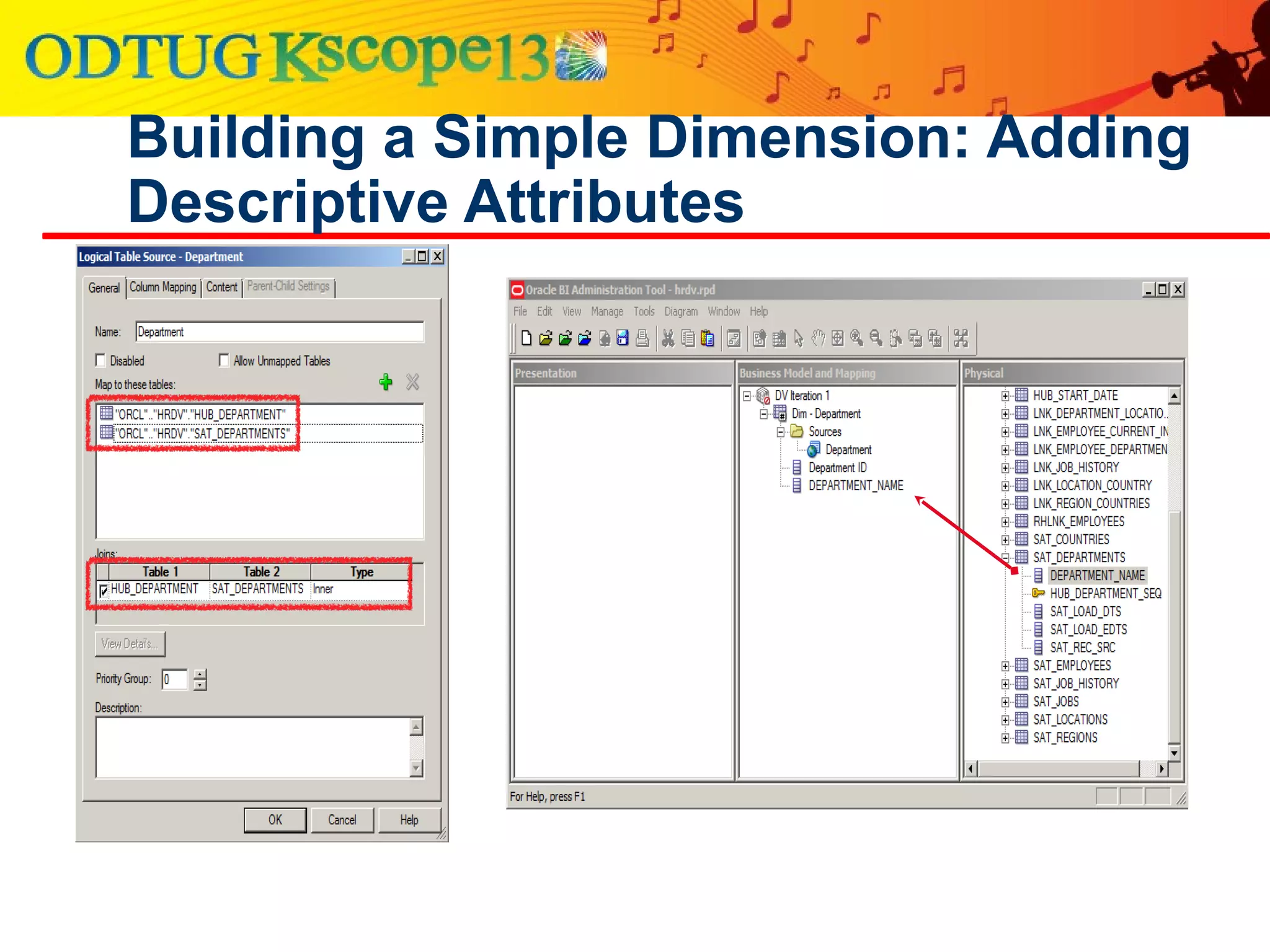
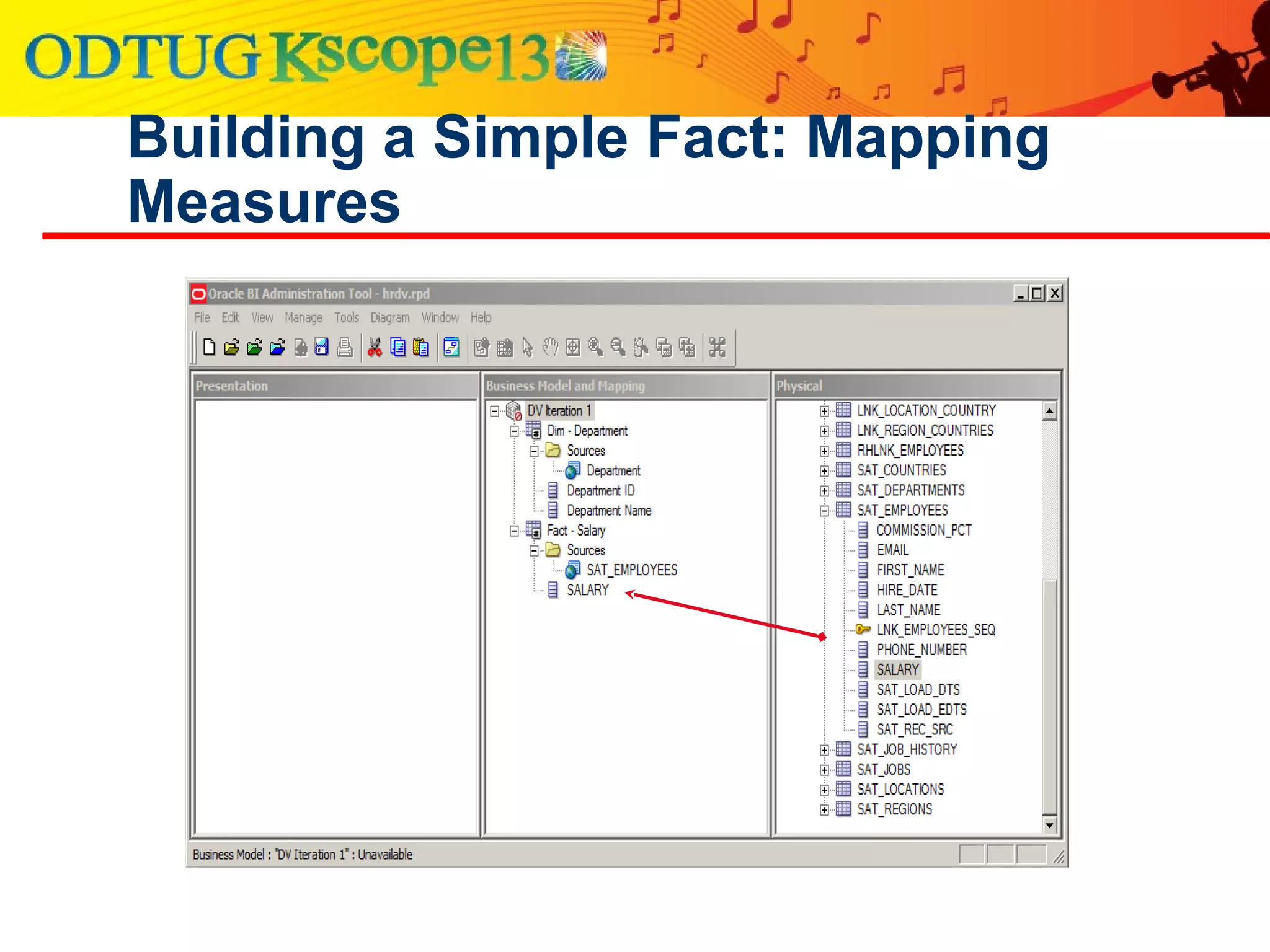
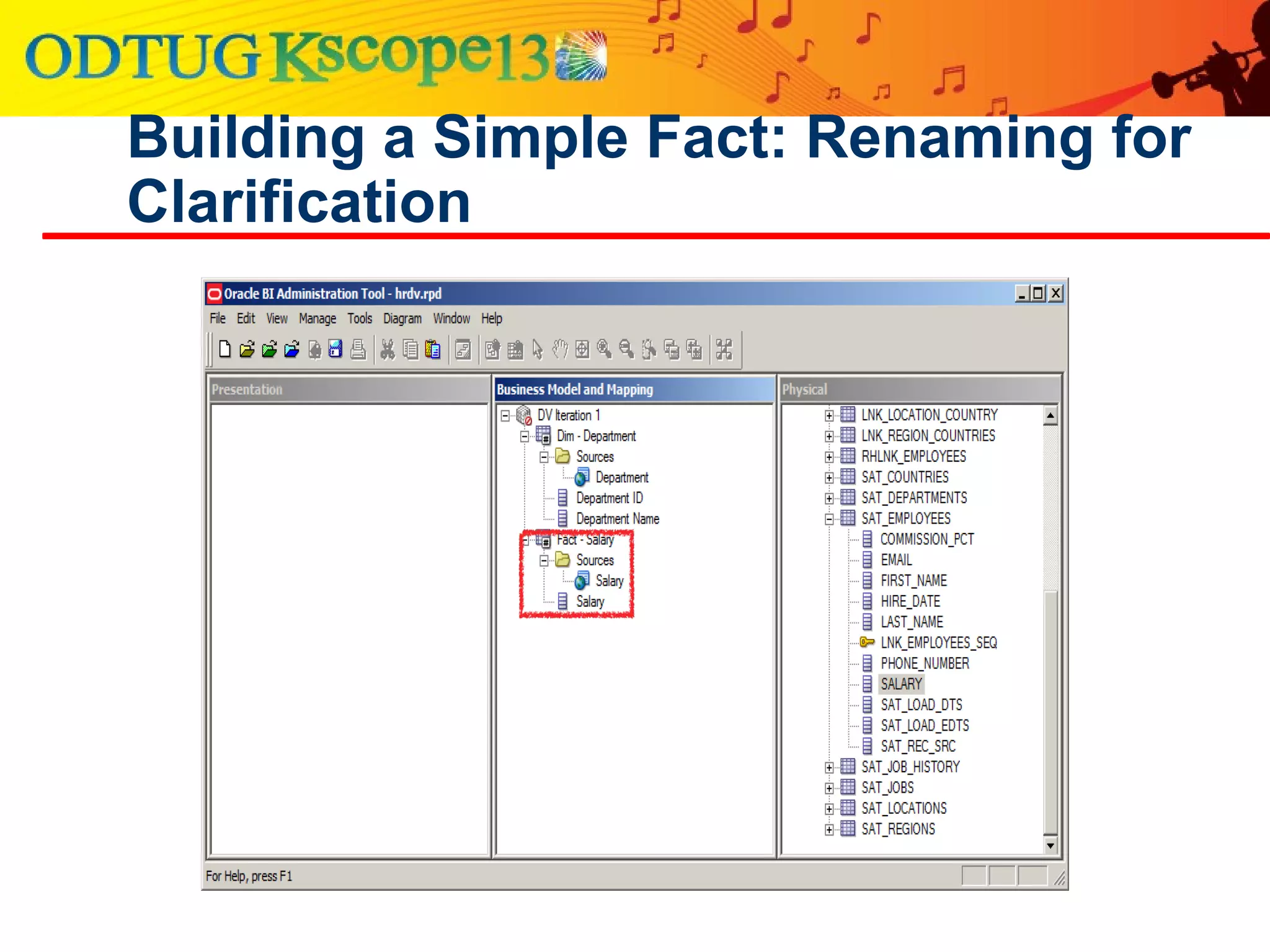
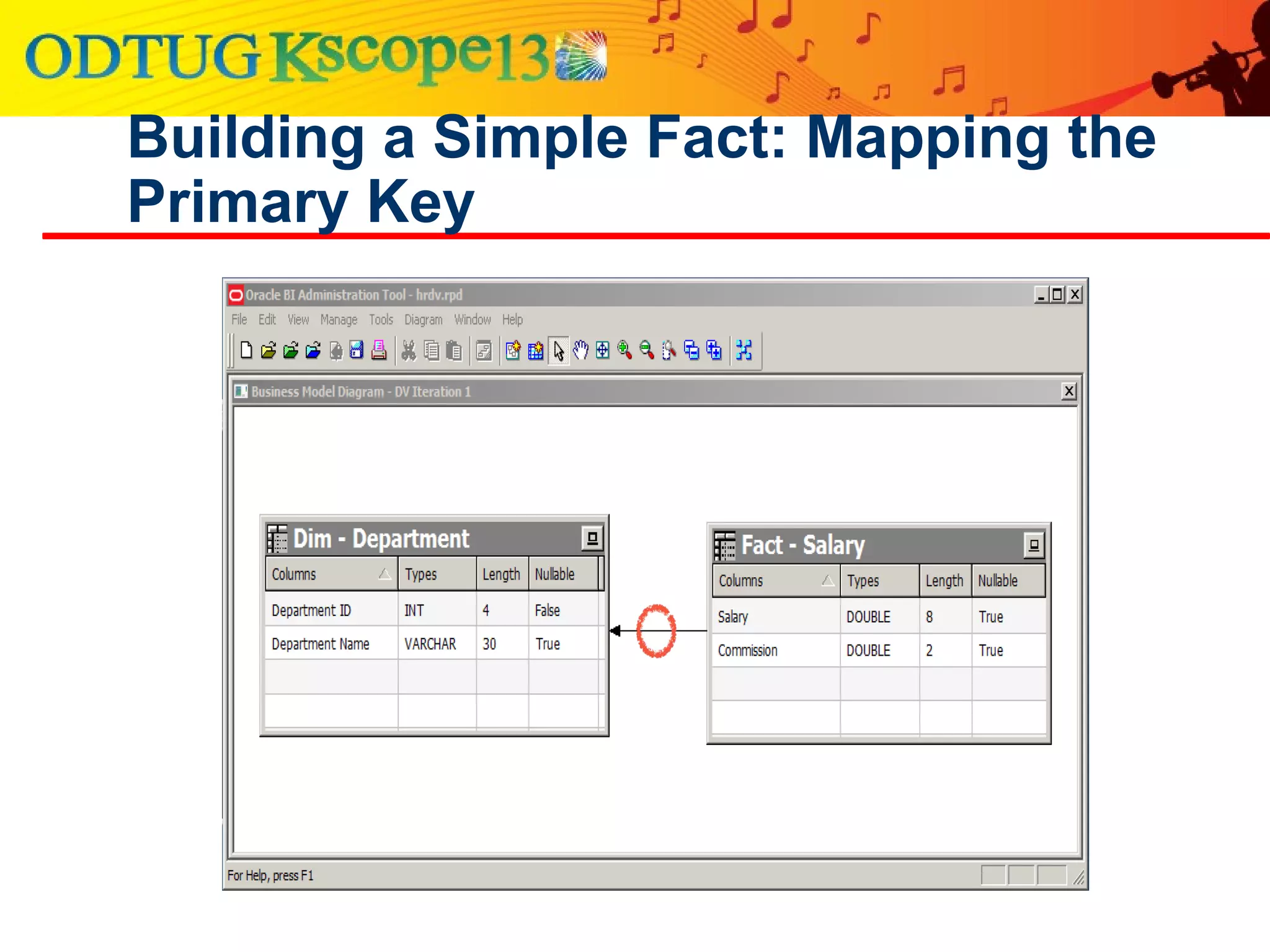
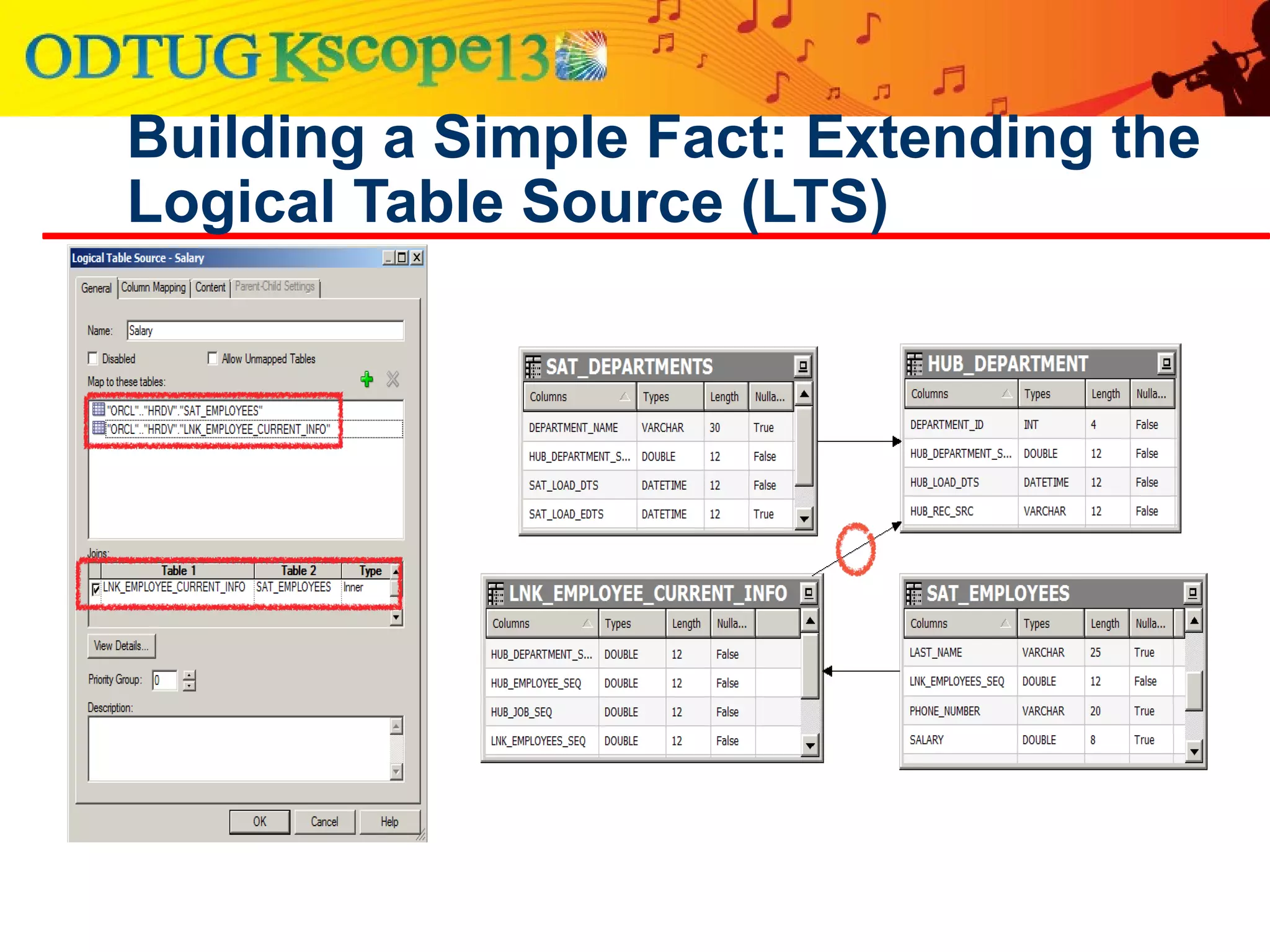
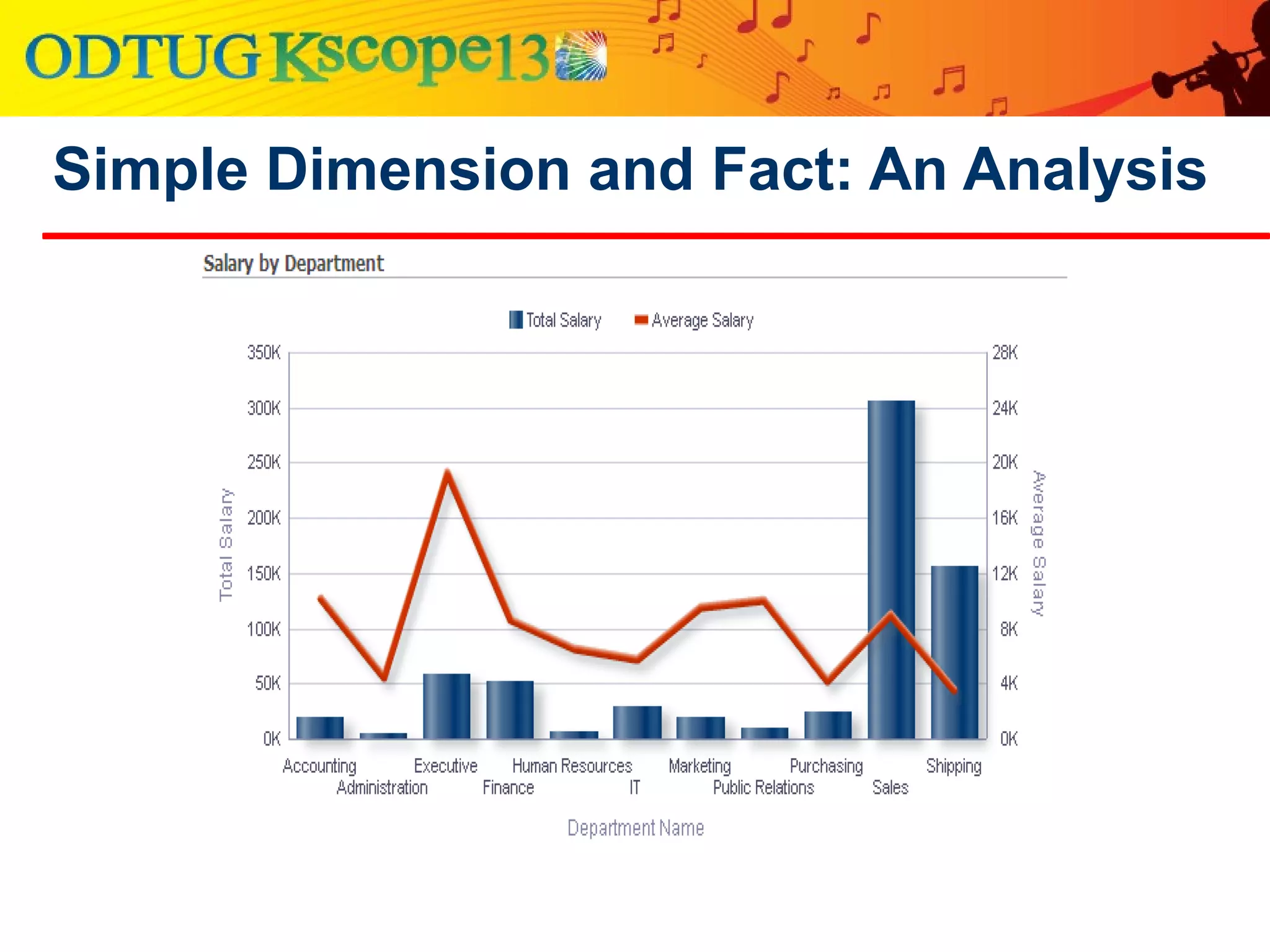
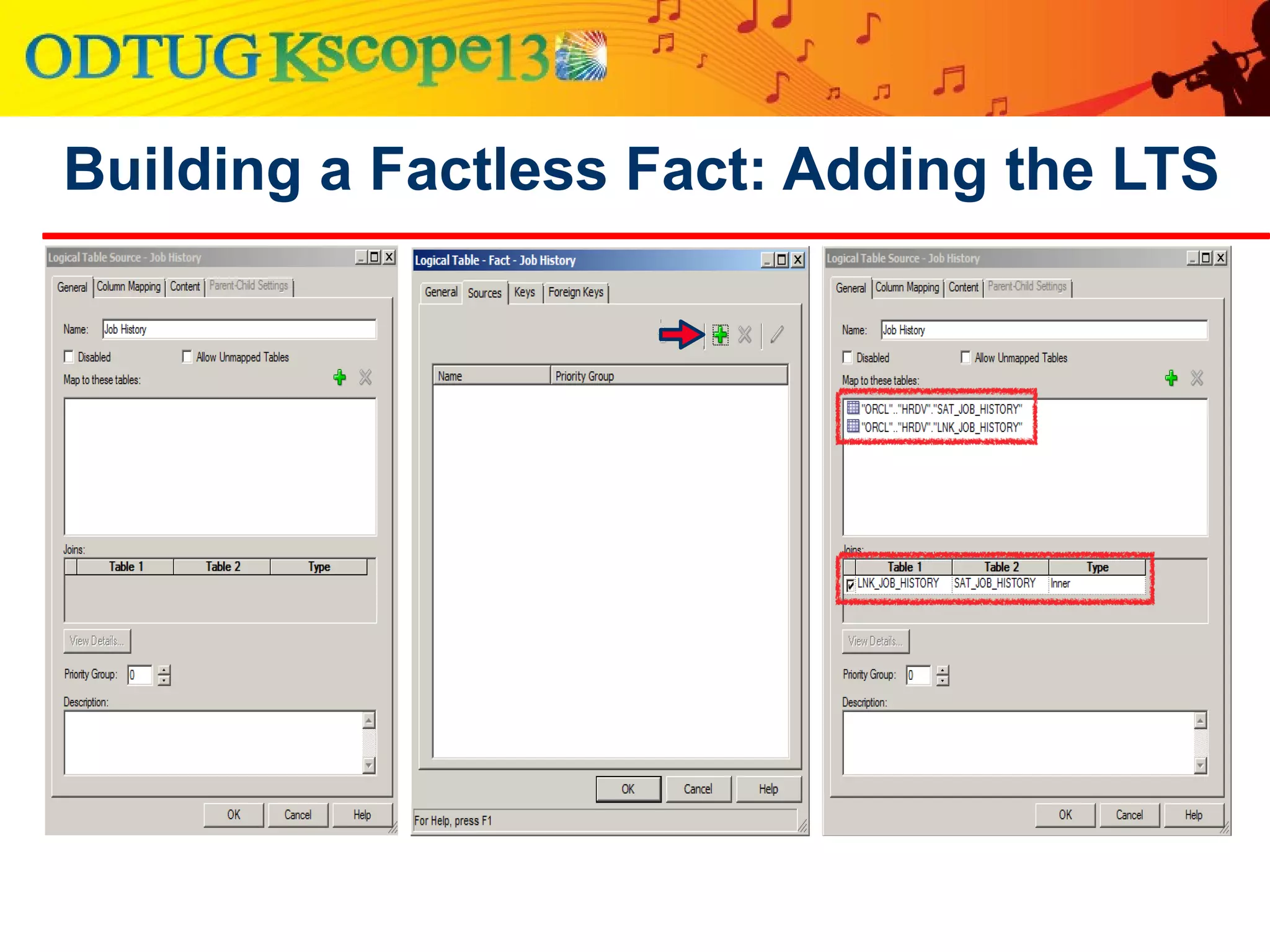

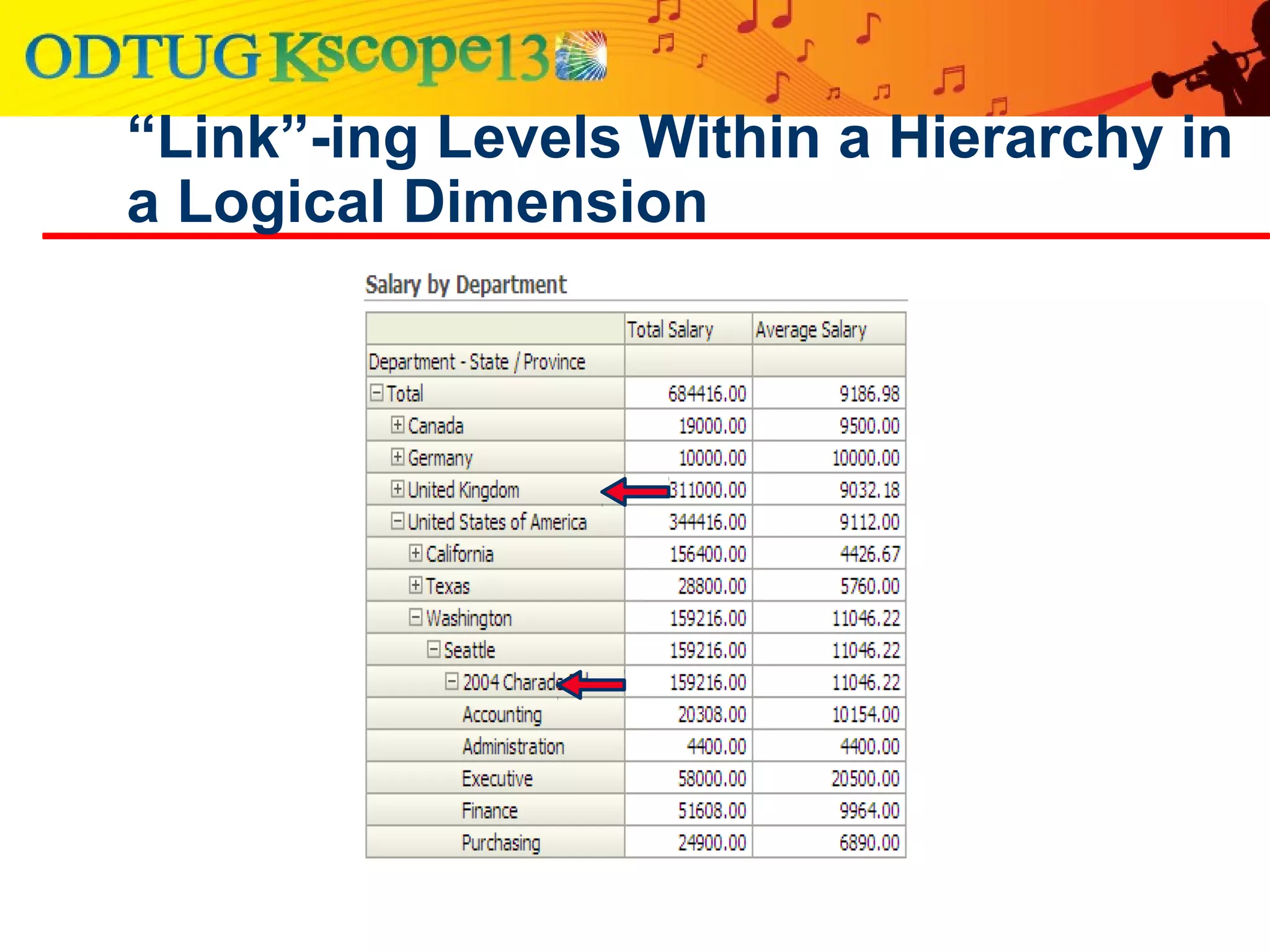
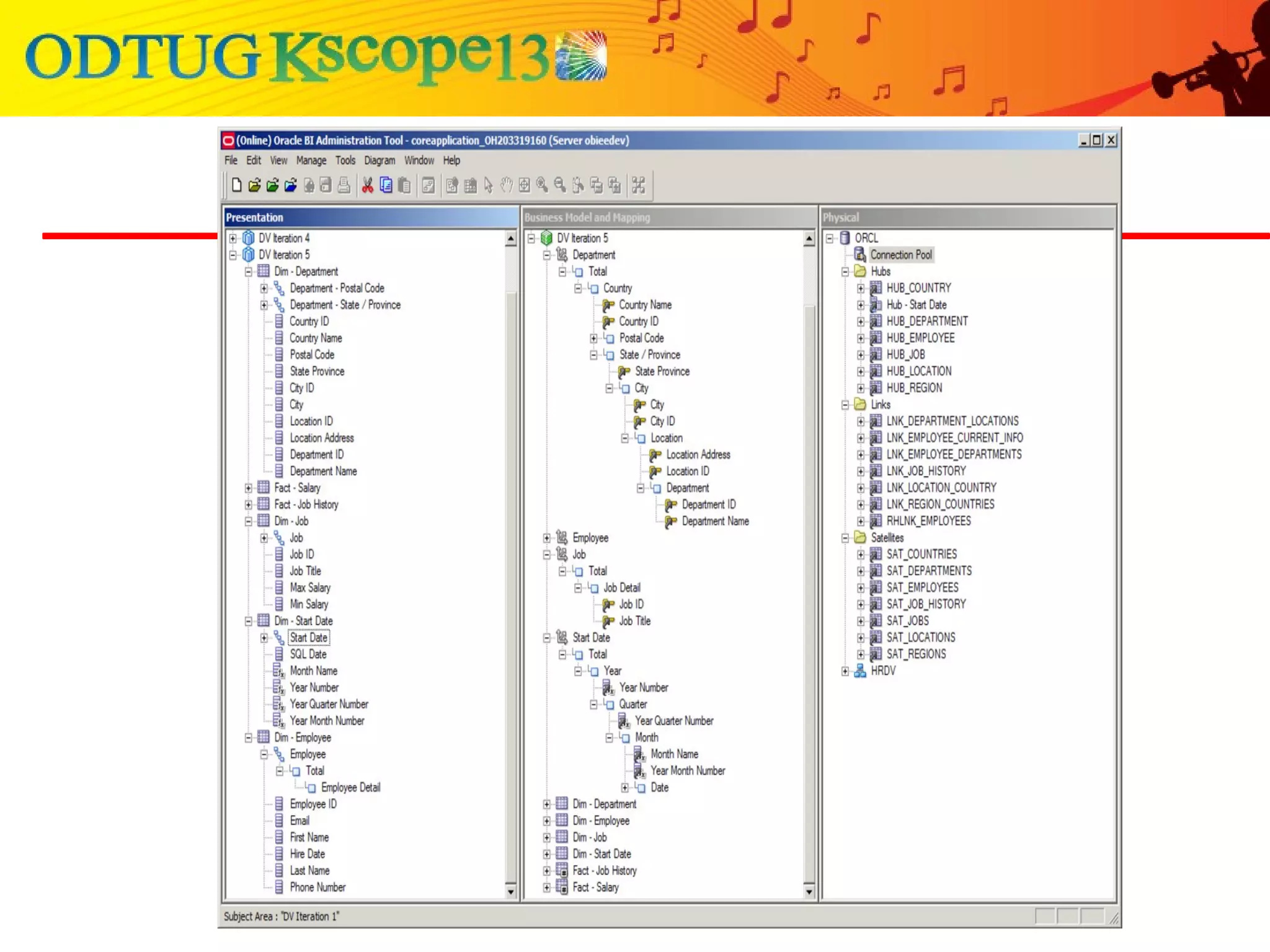







This document discusses using Oracle Business Intelligence Enterprise Edition (OBIEE) and the Data Vault data modeling technique to virtualize a business intelligence environment in an agile way. Data Vault provides a flexible and adaptable modeling approach that allows for rapid changes. OBIEE allows for the virtualization of dimensional models built on a Data Vault foundation, enabling quick iteration and delivery of reports and dashboards to users. Together, Data Vault and OBIEE provide an agile approach to business intelligence.










































































