이번 챕터의 목적
이번챕터에서는 optimization에 대해 알아봅니다.
Optimization 에서는 Cost function인 𝐽 𝜃 를 많이 줄일 수 있는
파라미터 𝜃를 찾는 것이 목적입니다.?
3.
8.1 How LearningDiffers from Pure Optimization
8.1.1 ~ 8.1.3에서는 전통적인 optimization algorithms과 머신러닝에서의 optimization이
어떻게 다른 가를 얘기합니다
8.1.1
데이터의 진짜 분포를 안다.
(O) : optimization algorithms
(X) : machine learning problem
(일부 training set 가지고)
8.1.2
머신러닝에서는 surrogate(대리의) loss function 과 early stopping을 사용
- surrogate loss function : loss function에 sigmoid나 log-likelihood(−log(𝑦))를 사용
- early stopping : 7장에 소개되었다시피 훈련을 도중에 멈추는 것
4.
8.1.3 Batch andMinibatch Algorithms
왜 일부의 샘플만 사용하는가?
1. 속도는 느린데 성능의 그에 비례해서 좋아지지 않음
n개의 표본으로 추정한
표준오차 𝜎
𝑛
에 대해서
10,000 example
- 100배의 계산을 더 해야함!
- 표준오차는 10배 더 줄어들 뿐!
(100배 줄지 않고)
2. training set의 중복
머신러닝에서는 일부 example만 가지고 훈련을 한다. 그 이유와 방법을 알아보자
100 example
5.
8.1.3 Batch andMinibatch Algorithms
batch(or deterministic) gradient methods
minibatch(or minibatch stochastic, stochastic) methods
전체 training examples를 동시에 사용하는 방법
일부 training examples만 사용하는 방법
6.
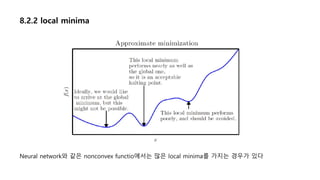
8.2 Challenges inNeural Network Optimization
- Ill- condition
- Local minima
- Plateaus, saddle points and other flat regions
- Cliff and exploding gradients
- Long-term dependencies
- Inexact gradients
- Poor correspondence between local and global structure
7.
8.2.1 Ill-conditioning
식 4.9는비용함수를 2차 테일러 급수로 근사한 것을 나타내고
8.10은 위의 식의 비용함수의 증가분을 나타낸다.
즉, 훈련을 하는데 왼쪽 항 이 오른쪽 항 보다 더 큰 경우 비용함수가 증가한다.
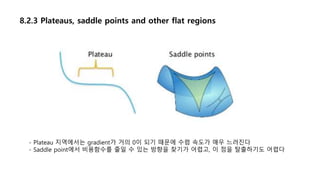
8.2.3 Plateaus, saddlepoints and other flat regions
- Plateau 지역에서는 gradient가 거의 0이 되기 때문에 수렴 속도가 매우 느려진다
- Saddle point에서 비용함수를 줄일 수 있는 방향을 찾기가 어렵고, 이 점을 탈출하기도 어렵다
10.
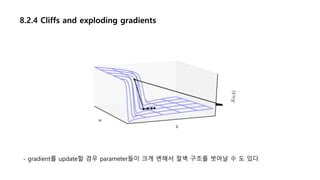
8.2.4 Cliffs andexploding gradients
- gradient를 update할 경우 parameter들이 크게 변해서 절벽 구조를 벗어날 수 도 있다
11.
8.2.5 Long-term dependencies
-계산 그래프가 깊어질 수록(network의 층이 깊은 경우) matrix를 계속해서 곱하는 형태가
나오게 된다. 이 경우 gradient가 사라지거나 폭발하는 문제가 발생할 수 있다.
8.2.6 inexact gradients
- 전체 데이터가 아닌 일부 sample을 이용하는 것이기 때문에, noisy와 biased estimate 로 부터
부정확한 gradient를 얻을 수도 있다.
12.
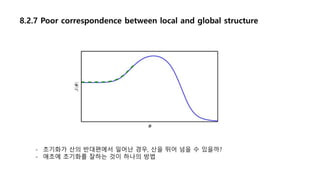
8.2.7 Poor correspondencebetween local and global structure
- 초기화가 산의 반대편에서 일어난 경우, 산을 뛰어 넘을 수 있을까?
- 애초에 초기화를 잘하는 것이 하나의 방법
13.
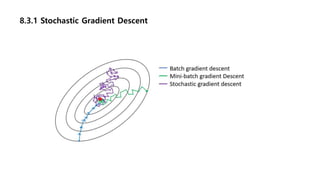
8.3.1 Stochastic GradientDescent
- 실제는 𝜖 (learning rate)를 점차 줄여 줘야함. 샘플링 했기 때문에 최소점에 도달하지 못하기 때문
- 𝜖 설정에 대한 명확한 기준은 없음. Trial and error를 통해 결정하시길
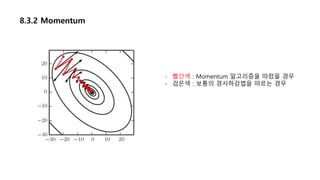
8.3.2 Momentum
- Stochasticgradient descent 는 종종 느릴 경우가 있다
- 학습을 가속하기 위한 방법
- 누적된 과거 gradient가 지향하는 방향을 현재 gradient에 보정하는 방식
𝑣 𝑡+1 = 𝛼𝑣 𝑡 − 𝜖𝑔 𝜃𝑡
𝜃𝑡+1 = 𝜃𝑡 + 𝑣 𝑡+1
𝜃를 업데이트 할 때 𝑣를 이용한다
𝑣는 기존의 gradient 누적 값이라고 생각하면 된다
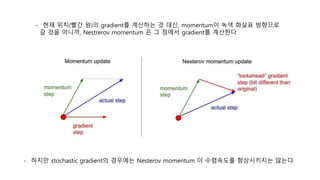
8.3.3 Nesterov Momentum
𝑣𝑡+1 = 𝛼𝑣 𝑡 − 𝜖𝑔 𝜃𝑡 + 𝛼𝑣 𝑡
𝜃𝑡+1 = 𝜃𝑡 + 𝑣 𝑡+1
- 일반 Momentum 방식보다 수렴속도를 향상 시키기 위한 방식
18.
- 하지만 stochasticgradient의 경우에는 Nesterov momentum 이 수렴속도를 향상시키지는 않는다
- 현재 위치(빨간 원)의 gradient를 계산하는 것 대신, momentum이 녹색 화살표 방향으로
갈 것을 아니까, Nestrerov momentum 은 그 점에서 gradient를 계산한다
19.
8.4 Parameter InitializationStrategies
- Nonconvex cost function : initial point가 훈련에 큰 영향을 준다
- 아직 연구가 많이 되지 않아, 최고의 방법이라고 할 것은 딱히 없음.
다만,
- Break Symmetry : 초기 𝑤는 서로 달라야함(같은 경우 같은 것들을 계속 같은 방식으로 갱신)
- Gaussian or unif𝑜𝑟𝑚 𝑈 −
6
𝑚+𝑛
,
6
𝑚+𝑛
(𝑚: 𝑖𝑛𝑝𝑢𝑡𝑠, 𝑛: 𝑜𝑢𝑡𝑝𝑢𝑡𝑠)
20.
8.5 학습 속도를적절히 변경하는 알고리즘
(Algorithms with Adaptive Learning Rates)
초매개변수(hyper-parameter) 중 설정하기 아주 어려운 “학습률(learning rate)”
학습률은 모델의 성능에 중요한 영향을 미침
비용함수는 매개변수 공간(parameter space)에서 일부 방향으로만 민감하게 반응
(그 외의 방향으로는 둔감하게 반응)
운동량 알고리즘(momentum algorithm)으로 이런 문제점을 해결할 수 있지만,
또 다른 초매개변수를 도입해야 한다는 대가를 치러야 함
21.
8.5 학습 속도를적절히 변경하는 알고리즘
(Algorithms with Adaptive Learning Rates)
초매개변수를 추가하지 않아도 되는 방법이…
민감도의 방향들이 공간의 축에 어느정도 정렬되어 있다고 가정한다면,
매개변수마다 개별적인 학습률을 사용하여 자동으로 학습되게 할 수 있음
ex) 델타-바-델타(delta-bar-delta) 알고리즘
손실함수의 주어진 모델 매개변수에 대한 편미분 부호가 안 바뀌면 >> 학습률 증가
편미분 부호가 바뀌면 >> 학습률 감소
22.
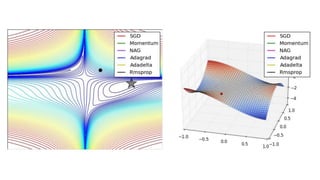
8.5.1 AdaGrad
AdaGrad(2011)는 AdaptiveGradient(적응적 기울기)를 줄여서 만든 이름
모든 모델 매개변수의 학습률을 지난 모든 단계의 기울기들을 누적한 값에
(구체적으로는 기울기 제곱들의 합의 제곱근) 반비례해서 개별적으로 적용
손실함수의 편미분이 큰 매개변수의 학습률은 빠르게 감소 (많이 변했으면 학습률 작게)
손실함수의 편미분이 작은 매개변수의 학습률은 느리게 감소 (적게 변했으면 학습률 크게)
>> 매개변수 공간에서 전반적으로 완만한 경사를 따라 학습이 진행되는 효과
볼록함수 최적화(Convex Optimization)에 적합함
AdaGrad 학습을 계속 진행하면 학습률이 너무 줄어드는 단점이 있음
8.5.2 RMSProp
RMSProp(2012)는 RootMean Square Propagation(제곱평균제곱근 전파)를 줄여서 만든 이름
딥러닝의 대가 제프리 힌튼이 제안한 방법
AdaGrad의 단점을 해결 (비볼록(non-convex) 상황에서도 잘 작동)
기울기 누적 대신 “지수 가중 이동 평균(exponentially weighted moving average)”을 사용
>> 아주 오래 전의 기울기들은 학습률 변화에 반영되지 않음
RMSProp은 심층 신경망(deep neural network)을 위한 효과적이고 실용적인 최적화 알고리즘
현재 딥러닝 실무자들이 일상적으로 사용하는 주된 최적화 방법 중 하나
8.5.3 Adam
Adam(2014)은 AdaptiveMoments(적응적 적률)을 줄여서 만든 이름
Adam은 RMSProp과 Momentum(운동량) 방식의 조합이되 몇 가지 사항이 다른 알고리즘
Momentum 방식과 유사하게 지금까지 계산해온 기울기의 지수평균을 저장하며,
RMSProp과 유사하게 기울기의 제곱값의 지수평균을 저장
8.5.4 적합한 최적화알고리즘 선택하기
어떤 알고리즘을 사용해야 하는가?
안타깝게도, 아직 아무런 공감대도 형성되지 않은 상태
학습률 적응을 이용한 부류의 알고리즘들(RMSProp, AdaDelta 등)이 안정적인 성과
어느 하나의 알고리즘이 두드러지게 뛰어나지는 않았음
현재로서는, 알고리즘 선택 문제는 사용자가 주어진 알고리즘에 얼마나 익숙한가
(초매개변수의 조율 편의성 면에서)에 크게 의존
35.
8.6 근사 2차방법 (Approximate Second-Order Methods)
2차 방법들은 1차 방법들과 달리 최적화 개선을 위해 이차미분(이계도함수)을 활용
가장 널리 쓰이는 2차 방법이 뉴턴법
뉴턴법(Newton’s Method): 테일러 급수 전개를 이용
켤레 기울기법(Conjugate Gradients): 두 켤레방향들을 번갈아 취해서 하강 >> 효율적인 계산
BFGS(Broyden-Fletcher-Goldfarb-Shanno): 켤레 기울기법처럼 계산 부담 없이
뉴턴법의 일부 장점을 취하려는 시도의 하나
실용적으로 사용되지 않기 때문에 자세한 내용은 생략
36.
8.7 최적화 전략과메타 알고리즘
(Optimization Strategies and Meta-Algorithms)
최적화 기법 중에는 그 자체가 구체적인 알고리즘은 아니고, 구체적인 알고리즘을 만들어내거나
기존 알고리즘에 끼워 넣을 수 있는 서브루틴을 만들어낼 수 있는 일반적인 틀이 많음
이번 절에서는 그런 일반적인 최적화 전략들을 살펴볼 예정
37.
8.7.1 배치 정규화(Batch Normalization)
배치 정규화(2015)는 최근 deep neural network 최적화 분야에서 가장 흥미로운 혁신 중 하나
사실 배치 정규화는 최적화 알고리즘이 전혀 아님
기본적으로 Gradient Vanishing / Gradient Exploding 이 일어나지 않도록 하는 아이디어
지금까지 이 문제를 Activation 함수의 변화(ReLU 등)와 같은 방법으로 해결
이러한 간접적인 방법보다 training 과정 자체를 안정화하여 학습속도를 가속하는 방법
이러한 불안정화가 일어나는 이유가 ‘Internal Covariance Shift’
Internal Covariance Shift라는 현상은 Network의 각 층이나 Activation 마다 input의
distribution이 달라지는 현상을 의미
38.
8.7.1 배치 정규화(Batch Normalization)
이를 해결하기 위해 각 층의 input의 distribution을 평균 0, 표준편차 1인 input으로 정규화
whitening은 기본적으로 들어오는 input의 feature들을 uncorrelated 하게 만들어주고, 각각의
variance를 1로 만들어주는 작업
하지만, whitening을 하면 covariance matrix의 계산과 inverse의 계산이 필요하기 때문에
계산량이 많고, 일부 parameter 들의 영향이 무시됨
39.
8.7.1 배치 정규화(Batch Normalization)
이와 같은 whitening의 단점을 보완하고, internal covariance shift는 줄이기 위해
1. 각각의 feature들이 이미 uncorrelated 되어있다고 가정하고, feature 각각에 대해서만 scalar
형태로 mean과 variance를 구하고 각각 정규화
2. 단순히 mean과 variance를 0, 1로 고정시키는 것은 오히려 Activation function의 nonlinearity
를 없앨 수 있다. 또한, feature가 uncorrelated 되어있다는 가정에 의해 네트워크가 표현할 수 있
는 것이 제한될 수 있다. 이 점들을 보완하기 위해, normalize된 값들에 scale factor(𝜸)와 shift
factor(𝜷)를 더해주고 이 변수들을 back-prop 과정에서 같이 학습
3. training data 전체에 대해 mean과 variance를 구하는 것이 아니라, mini-batch 단위로 접근하
여 계산 (현재 택한 mini-batch 안에서만 mean과 variance를 구해서, 이 값을 이용해서 정규화)
40.
8.7.1 배치 정규화(Batch Normalization)
mini-batch 단위로 데이터를 가져와서 학습을 시키는데, 각 feature 별로 평균과 표준편차를 구한
뒤 normalize 해주고, scale factor(𝜸)와 shift factor(𝜷)를 이용하여 새로운 값을 만들어줌
41.
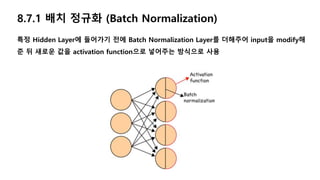
8.7.1 배치 정규화(Batch Normalization)
특정 Hidden Layer에 들어가기 전에 Batch Normalization Layer를 더해주어 input을 modify해
준 뒤 새로운 값을 activation function으로 넣어주는 방식으로 사용
42.
기존 Deep Network에서는learning rate를 너무 높게 잡을 경우 gradient가 explode/vanish
하거나, 나쁜 local minima에 빠지는 문제가 있었음. 이는 parameter들의 scale 때문인데,
Batch Normalization을 사용할 경우 propagation 할 때 parameter의 scale에 영향을 받지 않
게 된다. 따라서, learning rate를 크게 잡을 수 있게 되고 이는 빠른 학습을 가능하게 함.
Batch Normalization의 경우 자체적인 regularization 효과가 있음. 이는 기존에 사용하던
weight regularization term 등을 제외할 수 있게 하며, 나아가 Dropout을 제외할 수 있게 함.
(Dropout의 효과와 Batch Normalization의 효과가 같기 때문) Dropout의 경우 효과는 좋지만
학습 속도가 다소 느려진다는 단점이 있는데, 이를 제거함으로써 학습 속도도 향상됨
8.7.1 배치 정규화 (Batch Normalization)
43.
배치정규화의 장점
1. 학습속도가 개선된다 (학습률을 높게 설정할 수 있기 때문)
2. 가중치 초깃값 선택의 의존성이 적어진다 (학습을 할 때마다 출력값을 정규화하기 때문)
3. 과적합(overfitting) 위험을 줄일 수 있다 (드롭아웃 같은 기법 대체 가능)
4. Gradient Vanishing 문제 해결
8.7.1 배치 정규화 (Batch Normalization)
45.
8.7.2 좌표 하강법(Coordinate Descent)
주어진 최적화 문제를 더 작은 조각들로 분해해서 빠르게 풀 수 있음
모든 변수에 대해, 한 번에 한 좌표씩 최적화한다는 점에서
좌표 하강법(coordinate descent)이라고 부름
이를 좀 더 일반화한 기법으로, 일부 변수들에 대해 동시에 함수를 최소화하는
블록 좌표 하강법(block coordinate descent)이 있음
46.
8.7.3 폴랴크 평균법(Polyak Averaging)
폴랴크 평균법(1992)은 최적화 알고리즘이 매개변수 공간을 거쳐 간 자취(궤적)에 있는
여러 점의 평균을 구함
<기본 착안>
최적화 알고리즘이 계곡 바닥 근처에 있는 점에 전혀 도달하지 못하면서
계곡의 양쪽을 여러 번 왕복하기만 하는 상황이 벌어질 수도 있는데,
계곡 양쪽의 모든 점을 평균화하면 바닥과 가까워진다
비블록(non-convex) 문제에서는 먼 과거에 거쳐 간 매개변수 공간 점들을 포함시키는
것이 좋지 않아 이동 평균을 사용
47.
8.7.4 지도 사전훈련(Supervised Pretraining)
모델이 복잡하고 최적화하기 어렵거나 과제가 아주 어려울 때,
더 간단한 모델을 훈련해서 과제를 푼 다음 그 모델을 좀 더 복잡하게 만들거나
더 간단한 과제를 풀도록 모델을 훈련한 후 그 모델을 최종 과제에 적용 >> 사전훈련
탐욕 알고리즘은 하나의 문제를 여러 구성요소로 분해한 후 각 구성요소의 최적 버전을
개별적으로 구함
탐욕 알고리즘을 마친 후 결합 최적화 알고리즘의 한 미세조정 단계에서 원래의 문제에
대한 최적의 해를 찾는 방법도 있음
48.
8.7.5 최적화를 위한모델 설계
최적화 알고리즘을 개선하는 것이 최고의 최적화 개선 전략은 아님
알고리즘을 바꾸는 대신 처음부터 최적화가 쉽도록 모델을 설계해서 최적화 개선하는 경우도 많음
강력한 최적화 알고리즘을 사용하는 것보다 최적화하기 쉬운 모델을 선택하는 것이 더 중요
LSTM과 같은 혁신적인 모델들은 기존 모델(S자형 단위에 기초)에 비해 선형 함수 쪽으로 더 많이
이동한 형태 >> 최적화하기 바람직한 형태
49.
8.7.6 연속법과 커리큘럼학습
(Continuation Methods and Curriculum Learning)
최적화의 여러 어려움은 비용함수의 전역구조에서 비롯
단지 추정값을 개선히거나 국소 갱신 방향을 개선한다고 해서 그런 어려움이 개선되지 않음
연속법은 국소 최적화 과정이 그러한 바람직한 영역에서 대부분의 시간을 보내도록 초기점들을
선택함으로써 최적화를 쉽게 만드는 일단의 전략들을 통칭
연속법의 핵심은 같은 매개변수에 관한 일련의 목적함수들을 구축하는 것









































































![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)







![[밑러닝] Chap06 학습관련기술들](https://cdn.slidesharecdn.com/ss_thumbnails/chap06-171119110341-thumbnail.jpg?width=640&height=640&fit=bounds)


























