Personal Project
2018년 03월09일
전석원, 김지헌, 김형섭
Final Portfolio
Deep Dive into Deep Learning
: Exploration of CNN & RNN
2.
2
Deep Dive intoDeep Learning : Exploration of CNN & RNN
목차
■ Summary
■ CNN – Animal Classification (Cat vs. Dog)
■ CNN – Leaf Classification (Healthy vs. Diseased)
■ RNN – Stock Price Prediction
3.
3
Deep Dive intoDeep Learning : Exploration of CNN & RNN
CNN/RNN 이론과 실습의 균형 있는 학습을 위해 CAT/DOG 이미지
분류, 주가 예측을 하고, CNN 응용으로 이파리 이미지를 분류함
Summary
CNN Application RNN PracticeCNN Basic Practice II
Leaf ClassificationAnimal Classification Stock Price Prediction
정확도 : 98.8%정확도 : 97.8%
• Conv. Layer with Max Pool 4개
• Batch Norm applied
• Dropout : 0.5
• LR : 0.001
• Optimizer : Adam
• Batch Size : 100
• Conv. Layer with Max Pool 4개
• Batch Norm applied
• Dropout : 0.5
• LR : 0.001
• Optimizer : Adam
• Batch Size : 100
• LSTM with softsign
• Minmax scaling
• Dropout : 0.5
• LR : 0.001
• Optimizer : Adam
• Batch Size : 100
CNN Basic Practice I
4.
4
Deep Dive intoDeep Learning : Exploration of CNN & RNN
목차
■ Summary
■ CNN – Animal Classification (Cat vs. Dog)
■ CNN – Leaf Classification (Healthy vs. Diseased)
■ RNN – Stock Price Prediction
5.
5
Deep Dive intoDeep Learning : Exploration of CNN & RNN
기.본.에 충실하자!
기.본.을 갈고 닦자!
기.본.이 차이를 만든다!
CNN의 필.수. 입.문.이라고 할 수 있는
“개/고양이 분류”를 해볼까?
6.
6
Deep Dive intoDeep Learning : Exploration of CNN & RNN
넌 누구냐…?
개? 고양이?
개냥이!!!
7.
7
Deep Dive intoDeep Learning : Exploration of CNN & RNN
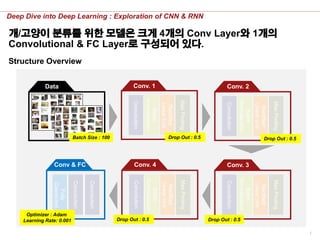
개/고양이 분류를 위한 모델은 크게 4개의 Conv Layer와 1개의
Convolutional & FC Layer로 구성되어 있다.
Structure Overview
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
Convolution
Convolution
Fully
Connected
Data Conv. 1 Conv. 2
Conv. 3Conv. 4Conv & FC
Drop Out : 0.5 Drop Out : 0.5
Drop Out : 0.5Drop Out : 0.5
Optimizer : Adam
Learning Rate: 0.001
Batch Size : 100
8.
8
Deep Dive intoDeep Learning : Exploration of CNN & RNN
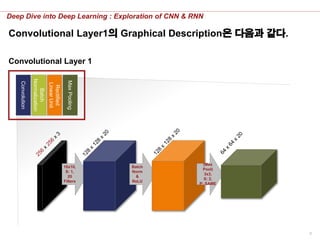
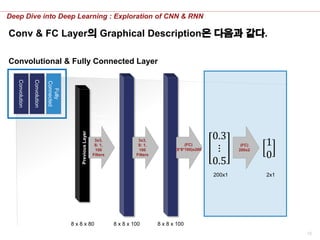
Convolutional Layer1의 Graphical Description은 다음과 같다.
10x10,
S: 1,
20
Filters
Convolutional Layer 1
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
Batch
Norm
&
ReLU
(Max
Pool)
3x3,
S: 2,
P: SAME
9.
9
Deep Dive intoDeep Learning : Exploration of CNN & RNN
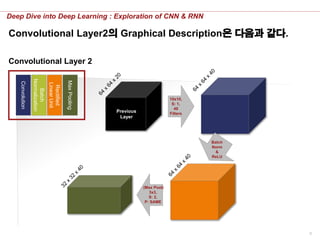
10x10,
S: 1,
40
Filters
Convolutional Layer 2
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
Batch
Norm
&
ReLU
(Max Pool)
3x3,
S: 2,
P: SAME
Previous
Layer
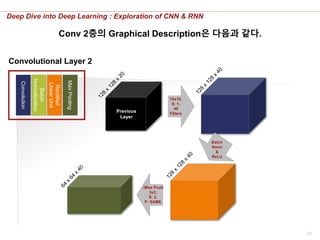
Convolutional Layer2의 Graphical Description은 다음과 같다.
10.
10
Deep Dive intoDeep Learning : Exploration of CNN & RNN
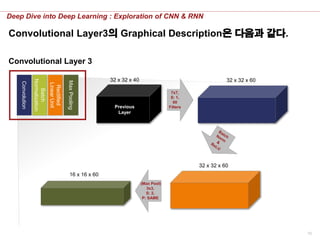
7x7,
S: 1,
60
Filters
Convolutional Layer 3
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
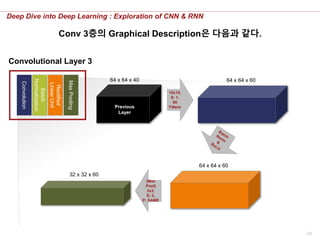
32 x 32 x 60
(Max Pool)
3x3,
S: 2,
P: SAME
32 x 32 x 40
Previous
Layer
32 x 32 x 60
16 x 16 x 60
Convolutional Layer3의 Graphical Description은 다음과 같다.
11.
11
Deep Dive intoDeep Learning : Exploration of CNN & RNN
Convolutional Layer 4
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
16 x 16 x 60
16 x 16 x 80
5x5,
S: 1,
80
Filters
Previous
Layer
16 x 16 x 80
Batch
Norm
&
ReLU
8 x 8 x 80
(Max
Pool)
3x3,
S: 2,
P: SAME
Convolutional Layer4의 Graphical Description은 다음과 같다.
12.
12
Deep Dive intoDeep Learning : Exploration of CNN & RNN
Convolutional & Fully Connected Layer
Fully
Connected
Convolution
Convolution
Previous
Layer
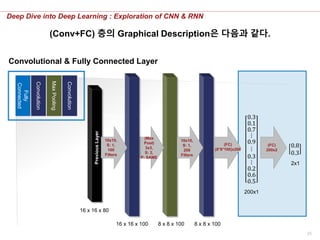
0.3
⋮
0.5
(FC)
(8*8*100)x
200
8 x 8 x 80
PreviousLayer
8 x 8 x 100
3x3,
S: 1,
100
Filters
8 x 8 x 100
(FC)
(8*8*100)x200
3x3,
S: 1,
100
Filters
1
0
(FC)
(8*8*100)x
200
(FC)
200x2
200x1 2x1
Conv & FC Layer의 Graphical Description은 다음과 같다.
13.
13
Deep Dive intoDeep Learning : Exploration of CNN & RNN
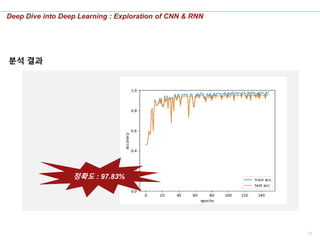
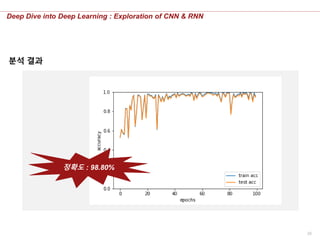
분석 결과
정확도 : 97.83%
14.
14
Deep Dive intoDeep Learning : Exploration of CNN & RNN
목차
■ Summary
■ CNN – Animal Classification (Cat vs. Dog)
■ CNN – Leaf Classification (Healthy vs. Diseased)
■ RNN – Stock Price Prediction
15.
15
Deep Dive intoDeep Learning : Exploration of CNN & RNN
CIFAR10과 개냥이 분류를 해보니 이제
CNN에 좀 익숙해진 것 같습니다.
(뿌듯뿌듯^^)
이제는 지금껏 갈고 닦은
기술을 활용해 볼 단계!
16.
16
Deep Dive intoDeep Learning : Exploration of CNN & RNN
뭘 할까? (고민고민)
…
…
IDEA
IDEA
IDEA
IDEA
IDEA
17.
17
Deep Dive intoDeep Learning : Exploration of CNN & RNN
(1) 제한된 시간 내에 할 수 있는,
(2) 나의 이력에 도움이 되는,
(3) 재미있는 주제가 뭐가 있을까…?!
요즘 제조업에서 공장자동화를 넘어
Smart Factory 사업을
추진한다는데…!
18.
18
Deep Dive intoDeep Learning : Exploration of CNN & RNN
Smart Factory의 CNN 활용은?!
제품 불량품 검출!
가자!!!
가자!!
가자!
:
데이터가 없다…!
19.
19
Deep Dive intoDeep Learning : Exploration of CNN & RNN
공장 제품 데이터가 없으면, 그
대안으로 “아픈 이파리 vs. 건강한
이파리” 를 분류해 보는 것도 좋을
꺼야! 비슷하잖아?
ITWILL
딥러닝 전임강사
스마트팩토리 분야
딥러닝 전문 연구원
맞습니다! 그렇습니다!!
좋아! 그럼 아픈 이파리를 모조리
검출해 봅시다!
혹 이 글을 읽으시는 딥러닝 전문가 분들께.
우리나라의 딥러닝 교육을 위해 교육용 데이터 좀 공개해 주세요! 언제까지 미국 데이터 써야 하나요…ㅠㅠ 교육이 힘입니다!
20.
20
Deep Dive intoDeep Learning : Exploration of CNN & RNN
Structure Overview
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
Data Conv. 1 Conv. 2
Conv. 3Conv. 4Conv & FC
Drop Out : 0.5 Drop Out : 0.5
Drop Out : 0.5Drop Out : 0.5
Batch Size : 100
Fully
Connected
Convolution
MaxPooling
Convolution
Optimizer : Adam
Learning Rate: 0.001
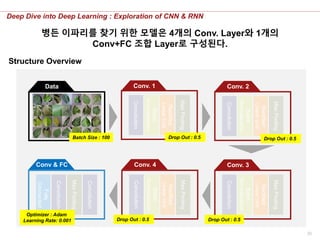
병든 이파리를 찾기 위한 모델은 4개의 Conv. Layer와 1개의
Conv+FC 조합 Layer로 구성된다.
21.
21
Deep Dive intoDeep Learning : Exploration of CNN & RNN
10x10,
S: 1,
20
Filters
Convolutional Layer 1
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
Batch
Norm
&
ReLU
(Max
Pool)
3x3,
S: 2,
P: SAME
Original Image Re-coloring
Background
Pre-Processing Data
효과적이고 효율적인
분석을 위해 모든
이미지의 배경색을
검정색으로 통일함
Conv 1층의 Graphical Description은 다음과 같다.
22.
22
Deep Dive intoDeep Learning : Exploration of CNN & RNN
10x10,
S: 1,
40
Filters
Convolutional Layer 2
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
Batch
Norm
&
ReLU
(Max Pool)
3x3,
S: 2,
P: SAME
Previous
Layer
Conv 2층의 Graphical Description은 다음과 같다.
23.
23
Deep Dive intoDeep Learning : Exploration of CNN & RNN
10x10,
S: 1,
60
Filters
Convolutional Layer 3
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
64 x 64 x 60
(Max
Pool)
3x3,
S: 2,
P: SAME
64 x 64 x 40
Previous
Layer
64 x 64 x 60
32 x 32 x 60
Conv 3층의 Graphical Description은 다음과 같다.
24.
24
Deep Dive intoDeep Learning : Exploration of CNN & RNN
Convolutional Layer 4
Convolution
Batch
Normalization
Rectified
LinearUnit
MaxPooling
32 x 32 x 60
32 x 32 x 80
10x10,
S: 1,
80
Filters
Previous
Layer
32 x 32 x 80
Batch
Norm
&
ReLU
16 x 16 x 80
(Max Pool)
3x3,
S: 2,
P: SAME
Conv 4층의 Graphical Description은 다음과 같다.
25.
25
Deep Dive intoDeep Learning : Exploration of CNN & RNN
Convolutional & Fully Connected Layer
Previous
Layer
16 x 16 x 80
PreviousLayer
16 x 16 x 100 8 x 8 x 100
(FC)
(8*8*100)x200
10x10,
S: 1,
100
Filters
(FC)
200x2
200x1
2x1
Fully
Connected
Convolution
MaxPooling
Convolution
10x10,
S: 1,
200
Filters
(Max
Pool)
3x3,
S: 2,
P: SAME
8 x 8 x 100
0.3
0.1
0.7
⋮
0.9
⋮
0.3
⋮
0.2
0.6
0.5
0.8
0.3
(Conv+FC) 층의 Graphical Description은 다음과 같다.
26.
26
Deep Dive intoDeep Learning : Exploration of CNN & RNN
분석 결과
정확도 : 98.80%
27.
27
Deep Dive intoDeep Learning : Exploration of CNN & RNN
목차
■ Summary
■ CNN – Animal Classification (Cat vs. Dog)
■ CNN – Leaf Classification (Healthy vs. Diseased)
■ RNN – Stock Price Prediction
28.
28
Deep Dive intoDeep Learning : Exploration of CNN & RNN
이번에는 딥러닝의 꽃 이라는
RNN을 한 번 해보자!
그런데 RNN이 뭐지?
29.
29
Deep Dive intoDeep Learning : Exploration of CNN & RNN
Recurrent
Neural
Net 순환 신경망
(출처 : 네이버 어학사전)
30.
30
Deep Dive intoDeep Learning : Exploration of CNN & RNN
이 세상엔 이미지처럼 고정되어 있는 것보다
시간순서를 갖는 데이터가 훨~씬 많다
바로 이런 순서를 갖는 데이터를
처리하는 신경망이 RNN!
31.
31
Deep Dive intoDeep Learning : Exploration of CNN & RNN
이전에 입력 받은 데이터의
정보를 버리지 않고,
그 다음의 입력할
데이터에 다시 더해서 연산에
사용한다.
그래서
“순환!!”
다시 말하면,
32.
32
Deep Dive intoDeep Learning : Exploration of CNN & RNN
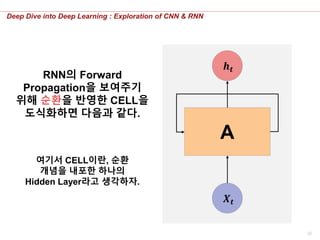
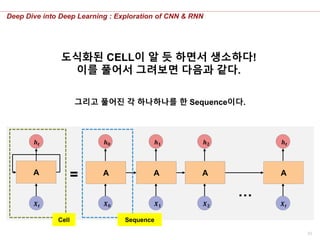
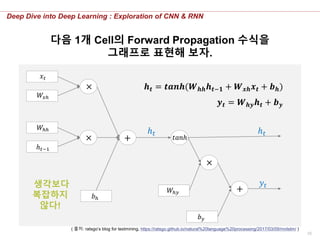
RNN의 Forward
Propagation을 보여주기
위해 순환을 반영한 CELL을
도식화하면 다음과 같다.
A
𝑿 𝒕
𝒉 𝒕
여기서 CELL이란, 순환
개념을 내포한 하나의
Hidden Layer라고 생각하자.
33.
33
Deep Dive intoDeep Learning : Exploration of CNN & RNN
도식화된 CELL이 알 듯 하면서 생소하다!
이를 풀어서 그려보면 다음과 같다.
A
𝑿 𝒕
𝒉 𝒕
𝑿 𝟎
𝒉 𝟎
A
𝑿 𝟏
𝒉 𝟏
A
𝑿 𝟐
𝒉 𝟐
A
𝑿 𝒕
𝒉 𝒕
A
…
=
그리고 풀어진 각 하나하나를 한 Sequence이다.
Cell Sequence
34.
34
Deep Dive intoDeep Learning : Exploration of CNN & RNN
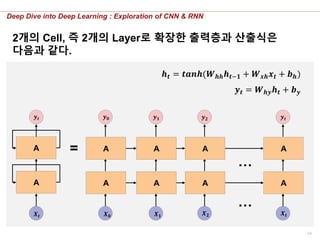
2개의 Cell, 즉 2개의 Layer로 확장한 출력층과 산출식은
다음과 같다.
A
𝑿 𝒕 𝑿 𝟎
A
𝑿 𝟏
A
𝑿 𝟐
A
𝑿 𝒕
A
…
=A A A A A
𝒚 𝒕 𝒚 𝟎 𝒚 𝟏 𝒚 𝟐 𝒚 𝒕
…
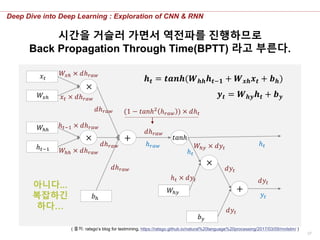
𝒉 𝒕 = 𝒕𝒂𝒏𝒉(𝑾 𝒉𝒉 𝒉 𝒕−𝟏 + 𝑾 𝒙𝒉 𝒙 𝒕 + 𝒃 𝒉)
𝒚 𝒕 = 𝑾 𝒉𝒚 𝒉 𝒕 + 𝒃 𝒚
39
Deep Dive intoDeep Learning : Exploration of CNN & RNN
𝒙 𝒕−𝟏
𝑾 𝒙𝒉
𝑾 𝒉𝒉
𝒉 𝒕−𝟐
×
×
+
𝑏ℎ
𝑡𝑎𝑛ℎ
𝑊ℎ𝑦
×
𝑏 𝑦
+
ℎ 𝑡−1
𝑟𝑎𝑤
𝑦𝑡−1
𝒉 𝒕−𝟏
𝑑𝑦𝑡−1
𝑑𝑦𝑡−1
𝑑𝑦𝑡−1
ℎ 𝑡−1 × 𝑑𝑦𝑡−1
ℎ 𝑡−1
𝑊ℎ𝑦 × 𝑑𝑦𝑡−1
(1 − 𝑡𝑎𝑛ℎ2
ℎ 𝑡−1
𝑟𝑎𝑤
) × 𝒅𝒉 𝒕−𝟏
𝑑ℎ 𝑡−1
𝑟𝑎𝑤
𝑑ℎ 𝑡−1
𝑟𝑎𝑤
𝑑ℎ 𝑡−1
𝑟𝑎𝑤
𝑑ℎ 𝑡−1
𝑟𝑎𝑤
𝑥 𝑡−1 × 𝑑ℎ 𝑡−1
𝑟𝑎𝑤
𝑾 𝒙𝒉 × 𝒅𝒉 𝒕−𝟏
𝒓𝒂𝒘
ℎ 𝑡−2 × 𝑑ℎ 𝑡−1
𝑟𝑎𝑤
𝑾 𝒉𝒉 × 𝒅𝒉 𝒕−𝟏
𝒓𝒂𝒘
( 출처: ratsgo’s blog for textmining, https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/ )
(𝑡시점으로 부터의
역 전파 결과)
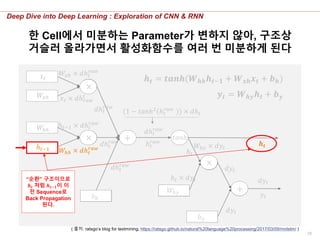
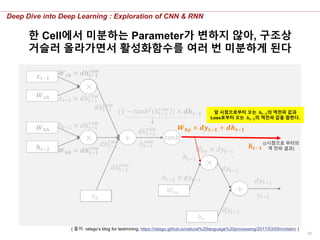
한 Cell에서 미분하는 Parameter가 변하지 않아, 구조상
거슬러 올라가면서 활성화함수를 여러 번 미분하게 된다
𝑾 𝒉𝒚 × 𝒅𝒚𝒕−𝟏 + 𝒅𝒉 𝒕−𝟏
앞 시점으로부터 오는 𝒉𝒕−𝟏의 역전파 값과
Loss로부터 오는 𝒉𝒕−𝟏의 역전파 값을 합한다.
40.
40
Deep Dive intoDeep Learning : Exploration of CNN & RNN
A
𝑿 𝒕
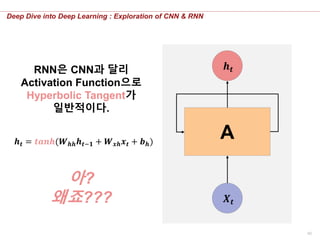
𝒉 𝒕RNN은 CNN과 달리
Activation Function으로
Hyperbolic Tangent가
일반적이다.
𝒉 𝒕 = 𝒕𝒂𝒏𝒉(𝑾 𝒉𝒉 𝒉𝒕−𝟏 + 𝑾 𝒙𝒉 𝒙 𝒕 + 𝒃 𝒉)
아?
왜죠???
41.
41
Deep Dive intoDeep Learning : Exploration of CNN & RNN
0
1
2
3
4
5
6
-6 -4 -2 0 2 4 6
Rectified Linear Unit
𝒇 𝒛 = ቊ
𝟎, 𝒛 ≤ 𝟎
𝒛, 𝒛 > 𝟎
-1.5
-1
-0.5
0
0.5
1
1.5
-6 -4 -2 0 2 4 6
Hyperbolic Tangent
𝒕𝒂𝒏𝒉(𝒙) =
𝒆 𝒙
− 𝒆−𝒙
𝒆 𝒙 + 𝒆−𝒙
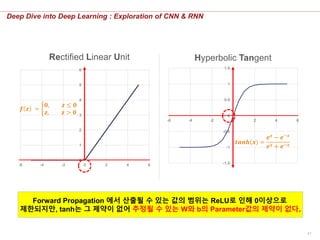
Forward Propagation 에서 산출될 수 있는 값의 범위는 ReLU로 인해 0이상으로
제한되지만, tanh는 그 제약이 없어 추정될 수 있는 W와 b의 Parameter값의 제약이 없다.
42.
42
Deep Dive intoDeep Learning : Exploration of CNN & RNN
지금까지 설명한 구조를 Vanilla RNN 이라 한다.
Sequence가 긴 구조에서 Vanilla RNN은 Gradient가 점점
감소/발산하는 Vanishing/Exploding Gradient Problem이
발생한다. 즉, 오래된 과거의 정보를 학습하지 못한다.
이러한 문제를 완화시키기 위해 나온 모델이
Long Short Term Memory(LSTM) 이다.
43.
43
Deep Dive intoDeep Learning : Exploration of CNN & RNN
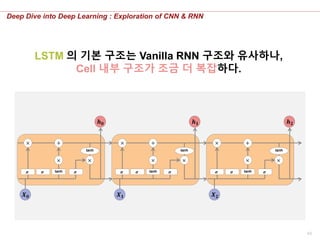
LSTM 의 기본 구조는 Vanilla RNN 구조와 유사하나,
Cell 내부 구조가 조금 더 복잡하다.
𝝈 𝝈 𝝈tanh
tanh
𝝈 𝝈 𝝈tanh
tanh
𝝈 𝝈 𝝈tanh
tanh
𝑿 𝟎 𝑿 𝟏 𝑿 𝟐
𝒉 𝟎 𝒉 𝟏 𝒉 𝟐
45
Deep Dive intoDeep Learning : Exploration of CNN & RNN
자, 이제 RNN에 대한 기본적인 이론은
다루었고, 간단한 실습을 통해 실질적인
Working Knowledge를 쌓아보자!
46.
46
Deep Dive intoDeep Learning : Exploration of CNN & RNN
RNN으로 할 수 있는 대표적인 연구 분야는,
1.자연어처리(번역, 챗봇, 시쓰기…)
2.시계열 예측(주가)
3.음성인식
등등… 많다!
47.
47
Deep Dive intoDeep Learning : Exploration of CNN & RNN
이 중에서 데이터를 (상대적으로) 구하기 쉽고 전 처리
과정이 (상대적으로) 적게 요구되는 주가 예측 기본
데이터를 활용하여 간단한 실습을 해보자!
48.
48
Deep Dive intoDeep Learning : Exploration of CNN & RNN
“순차”라고 했는데…
그러면 데이터를 입력하기 위해서 어떤 과정이
필요할까?
• Sequence 길이
(연속적 사건의 수)
어떤 한 시점을
예측하는데 과거 몇 개의
시점의 사건이 영향을
끼쳤는가?
• 독립변수와 종속변수의
순차적 입력
과거 Sequence 길이
만큼 한 시점 씩 이동
해가면서 입력
1. Normalization 2. Sequence 3. Rolling Window
MinMax 정규화
0 <
𝑋 − 𝑀𝑖𝑛(𝑋)
𝑀𝑎𝑥 𝑋 − 𝑀𝑖𝑛(𝑋)
< 1
49.
49
Deep Dive intoDeep Learning : Exploration of CNN & RNN
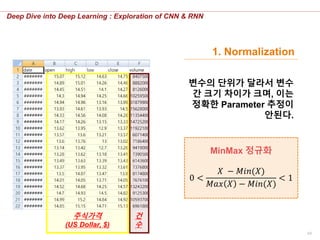
변수의 단위가 달라서 변수
간 크기 차이가 크며, 이는
정확한 Parameter 추정이
안된다.
MinMax 정규화
0 <
𝑋 − 𝑀𝑖𝑛(𝑋)
𝑀𝑎𝑥 𝑋 − 𝑀𝑖𝑛(𝑋)
< 1
1. Normalization
주식가격
(US Dollar, $)
건
수
50.
50
Deep Dive intoDeep Learning : Exploration of CNN & RNN
2. Sequence
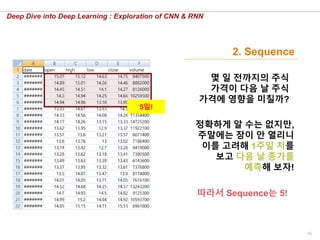
몇 일 전까지의 주식
가격이 다음 날 주식
가격에 영향을 미칠까?
따라서 Sequence는 5!
5일!
정확하게 알 수는 없지만,
주말에는 장이 안 열리니
이를 고려해 1주일 치를
보고 다음 날 종가를
예측해 보자!
51.
51
Deep Dive intoDeep Learning : Exploration of CNN & RNN
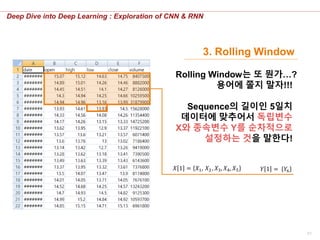
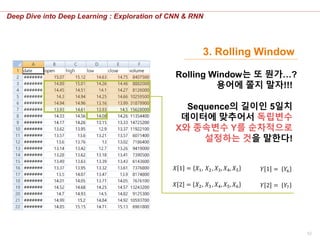
3. Rolling Window
Rolling Window는 또 뭔가…?
용어에 쫄지 말자!!!
Sequence의 길이인 5일치
데이터에 맞추어서 독립변수
X와 종속변수 Y를 순차적으로
설정하는 것을 말한다!
𝑋 1 = 𝑋1, 𝑋2 , 𝑋3, 𝑋4, 𝑋5 𝑌 1 = 𝑌6
52.
52
Deep Dive intoDeep Learning : Exploration of CNN & RNN
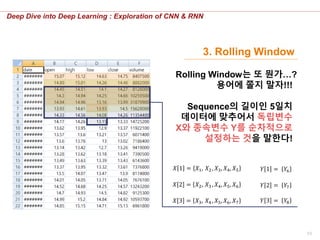
3. Rolling Window
Rolling Window는 또 뭔가…?
용어에 쫄지 말자!!!
Sequence의 길이인 5일치
데이터에 맞추어서 독립변수
X와 종속변수 Y를 순차적으로
설정하는 것을 말한다!
𝑋 1 = 𝑋1, 𝑋2 , 𝑋3, 𝑋4, 𝑋5
𝑋 2 = 𝑋2, 𝑋3 , 𝑋4, 𝑋5, 𝑋6 𝑌 2 = 𝑌7
𝑌 1 = 𝑌6
54
Deep Dive intoDeep Learning : Exploration of CNN & RNN
지금까지 설명한
데이터 전 처리 코드를
살펴보자!
55.
55
Deep Dive intoDeep Learning : Exploration of CNN & RNN
• Sequence 길이
(연속적 사건의 수)
어떤 한 시점을
예측하는데 과거 몇 개의
시점의 사건이 영향을
끼쳤는가?
• 독립변수와 종속변수의
순차적 입력
과거 Sequence 길이
만큼 한 시점 씩 이동
해가면서 입력
1. Normalization 2. Sequence 3. Rolling Window
MinMax 정규화
0 <
𝑋 − 𝑀𝑖𝑛(𝑋)
𝑀𝑎𝑥 𝑋 − 𝑀𝑖𝑛(𝑋)
< 1
56.
56
Deep Dive intoDeep Learning : Exploration of CNN & RNN
• Sequence 길이
(연속적 사건의 수)
어떤 한 시점을
예측하는데 과거 몇 개의
시점의 사건이 영향을
끼쳤는가?
• 독립변수와 종속변수의
순차적 입력
과거 Sequence 길이
만큼 한 시점 씩 이동
해가면서 입력
1. Normalization 2. Sequence 3. Rolling Window
MinMax 정규화
0 <
𝑋 − 𝑀𝑖𝑛(𝑋)
𝑀𝑎𝑥 𝑋 − 𝑀𝑖𝑛(𝑋)
< 1
따라서 Sequence는 5!
1주일 동안의 Working Days가
다음 시점의 종가에 영향을
미친다고 가정
57.
57
Deep Dive intoDeep Learning : Exploration of CNN & RNN
• Sequence 길이
(연속적 사건의 수)
어떤 한 시점을
예측하는데 과거 몇 개의
시점의 사건이 영향을
끼쳤는가?
• 독립변수와 종속변수의
순차적 입력
과거 Sequence 길이
만큼 한 시점 씩 이동
해가면서 입력
1. Normalization 2. Sequence 3. Rolling Window
MinMax 정규화
0 <
𝑋 − 𝑀𝑖𝑛(𝑋)
𝑀𝑎𝑥 𝑋 − 𝑀𝑖𝑛(𝑋)
< 1
58.
58
Deep Dive intoDeep Learning : Exploration of CNN & RNN
Data Setting이 끝나면 Tensorflow를 활용하여
1개 층의 LSTM 모델 그래프를 구축해 보자.
먼저 Hidden Layer인 Cell을 만드는데, 위와 같이
코드 한 줄로 끝난다. 복잡한 이론이 무색하게
굉.장.히. 심.플.하다.
59.
59
Deep Dive intoDeep Learning : Exploration of CNN & RNN
그런데 이 dynamic_rnn이라는 것은 뭘까?
1개의 Cell을 구축한 후, y값들을 산출하도록 rnn
Tensorflow 코드에 넣는다.
60.
60
Deep Dive intoDeep Learning : Exploration of CNN & RNN
만약 영어를 한국어로 번역하는 RNN모델을 구축한다고 하면,
입력되는 단어의 길이 및 개수가 다르기 때문에 일정한 길이의
sequence로 Input이 들어오지 않는다.
예를 들어,
Show me the money. (sequence 4)
He is handsome. (sequence 3)
을 번역한다고 하면, 서로 다른 Sequence를 처리해야 하기 때문에
입력 값의 길이와 출력 값의 길이가 유동적이어야 한다.
그리고 이를 가능하게 하는 것이 dynamic RNN이다!
61.
61
Deep Dive intoDeep Learning : Exploration of CNN & RNN
이해를 돕기 위해 RNN 그래프로
살펴보면…
62.
62
Deep Dive intoDeep Learning : Exploration of CNN & RNN
A
𝑿 𝒕
𝒉 𝒕
𝑿 𝟎
𝒉 𝟎
A
𝑿 𝟏
𝒉 𝟏
A
𝑿 𝟐
𝒉 𝟐
A
𝑿 𝒕
𝒉 𝒕
A
…
=
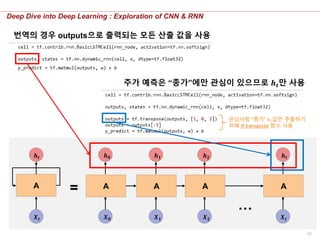
번역의 경우 outputs으로 출력되는 모든 산출 값을 사용
주가 예측은 “종가”에만 관심이 있으므로 𝒉 𝒕만 사용
관심사항 “종가” ℎ 𝑡값만 추출하기
위해 tf.transpose 함수 사용
64
Deep Dive intoDeep Learning : Exploration of CNN & RNN
End of Document
Thank You for Listening
65.
65
Deep Dive intoDeep Learning : Exploration of CNN & RNN
참고문헌
http://aikorea.org/blog/rnn-tutorial-3/
https://laonple.blog.me/
https://ratsgo.github.io/
https://m.blog.naver.com/PostView.nhn?blogId=infoefficien&logNo=221210061511&tar
getKeyword=&targetRecommendationCode=1https://github.com/hunkim/DeepLearning
ZeroToAll
링크
Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016). Layer normalization. arXiv preprint
arXiv:1607.06450.
Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic
segmentation. In Proceedings of the IEEE conference on computer vision and pattern
recognition (pp. 3431-3440).
Courville, A. (2016). Recurrent Batch Normalization. arXiv preprint arXiv:1603.09025.
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale
image recognition. arXiv preprint arXiv:1409.1556.
논문






















































![[기초개념] Recurrent Neural Network (RNN) 소개](https://cdn.slidesharecdn.com/ss_thumbnails/agistpurnndkim190430-190430140949-thumbnail.jpg?width=640&height=640&fit=bounds)


![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)








![[226]대용량 텍스트마이닝 기술 하정우](https://cdn.slidesharecdn.com/ss_thumbnails/226-161025031656-thumbnail.jpg?width=640&height=640&fit=bounds)








![[신경망기초] 심층신경망개요](https://cdn.slidesharecdn.com/ss_thumbnails/nn10-180318142325-thumbnail.jpg?width=640&height=640&fit=bounds)






![[GDG DevFest Gwangju 2018] 나도쓰고싶다 딥러닝: 통신/ IoT/ 웨어러블/ 에너지/ 의료헬스케어 적용하기](https://cdn.slidesharecdn.com/ss_thumbnails/gdgdevfestgwangju2018dkim-181212140243-thumbnail.jpg?width=640&height=640&fit=bounds)


