Download to read offline





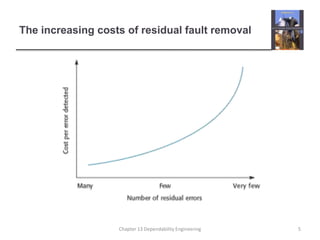










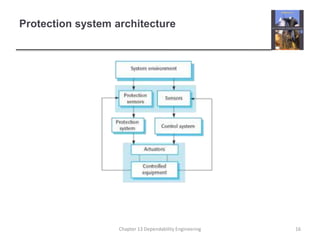


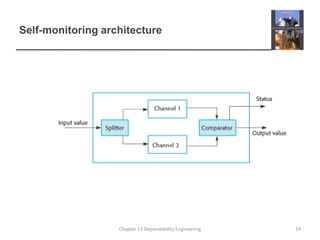

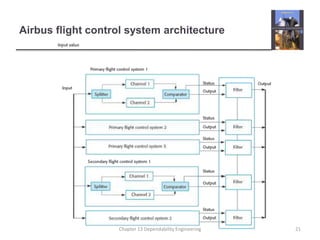





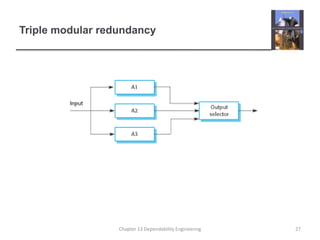
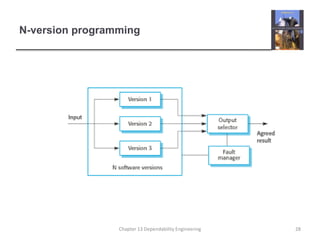











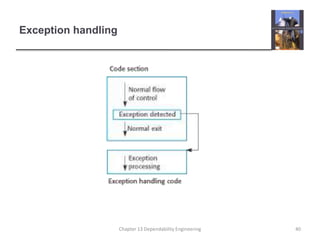











This document discusses techniques for engineering dependable software systems. It covers redundancy and diversity approaches to achieve fault tolerance. Dependable systems are achieved through fault avoidance, detection, and tolerance. Critical systems often use regulated processes and dependable architectures like protection systems, self-monitoring architectures, and N-version programming which involve redundant and diverse components to continue operating despite failures. The document gives examples of how these techniques are applied in systems like aircraft flight control to maximize availability.



























![Separation of concerns is a design concept [Dij82] that suggests that any com...](https://cdn.slidesharecdn.com/ss_thumbnails/272547621-250624182023-7f9053e3-thumbnail.jpg?width=640&height=640&fit=bounds)
























































