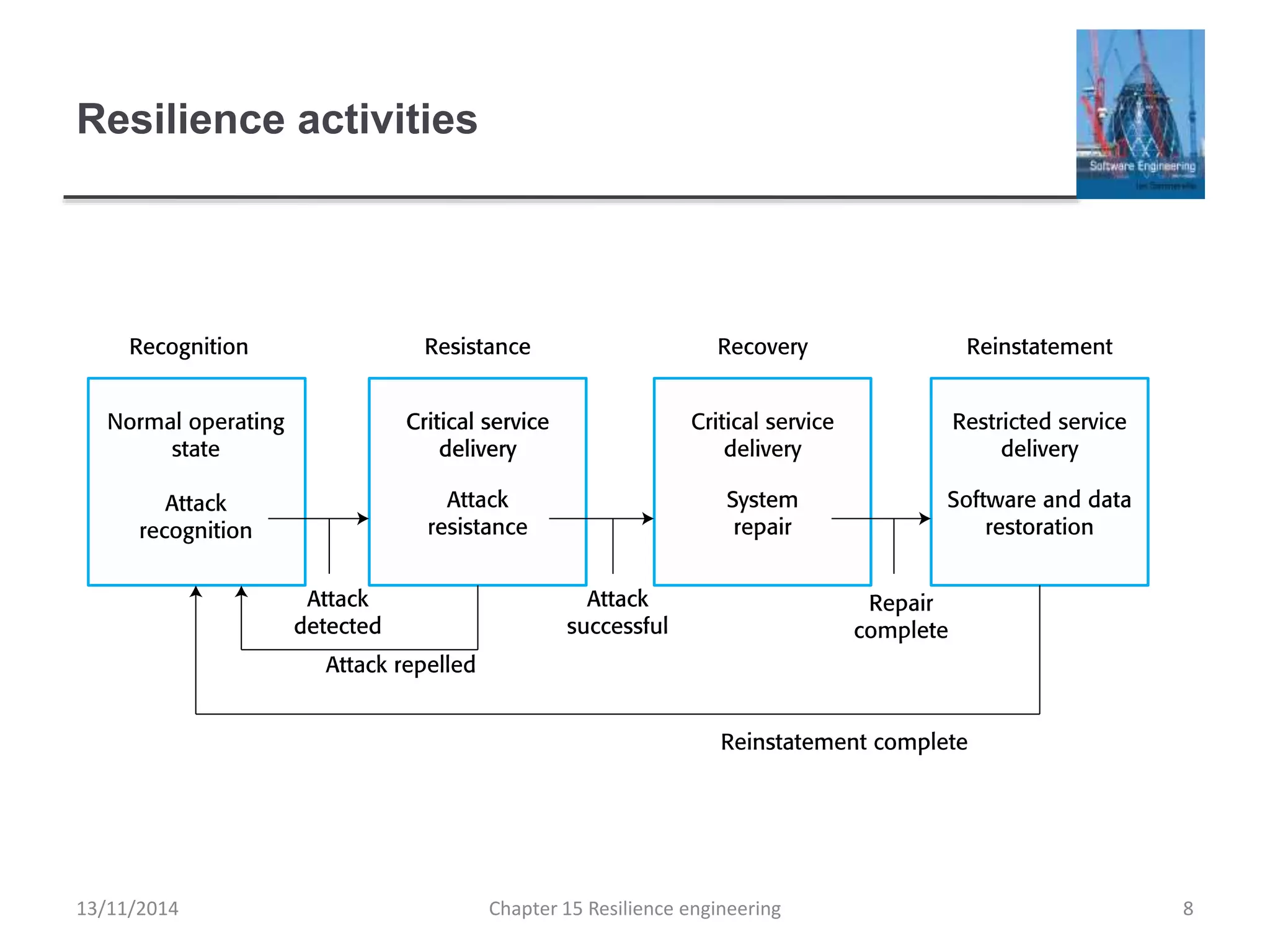
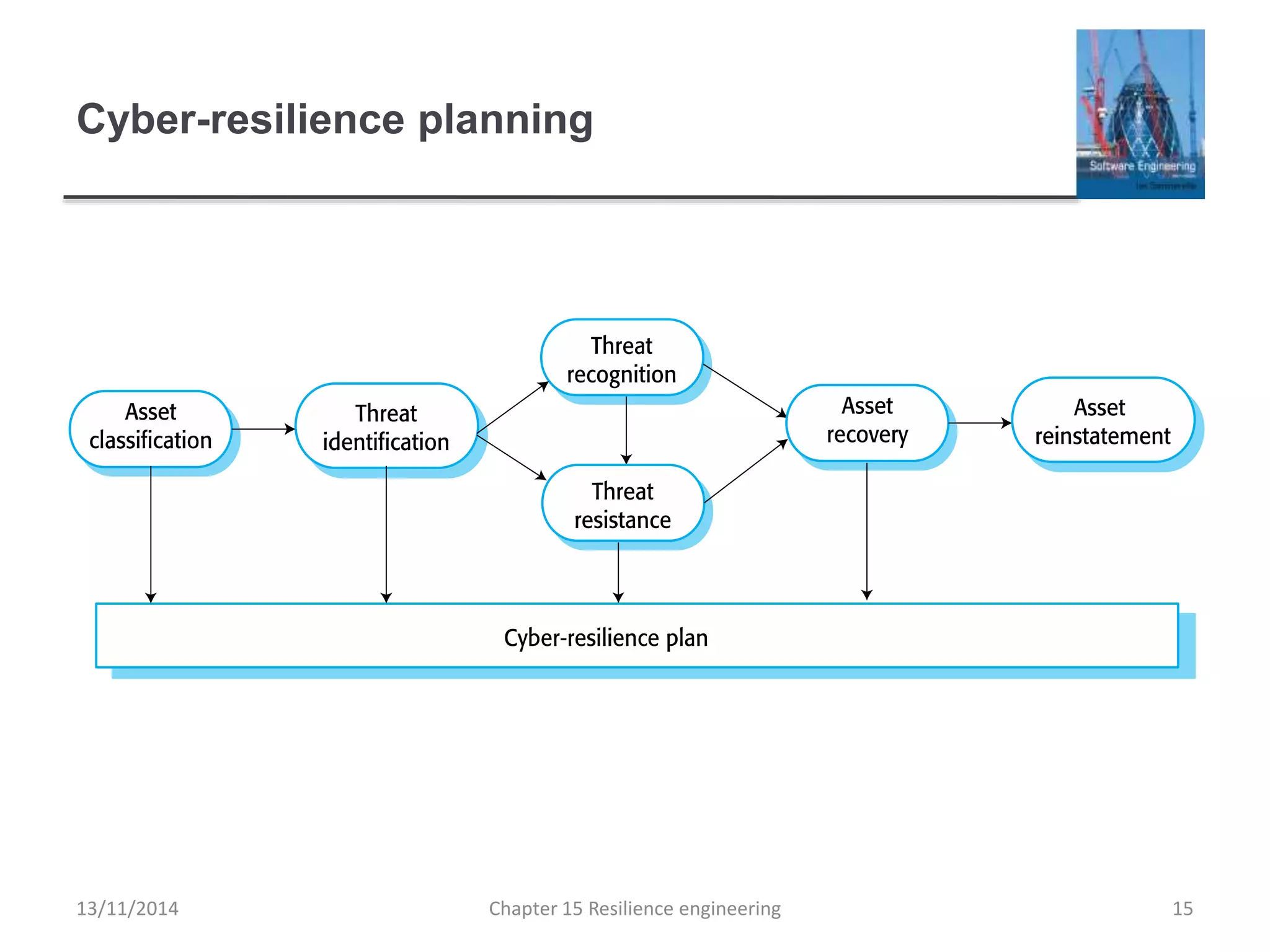
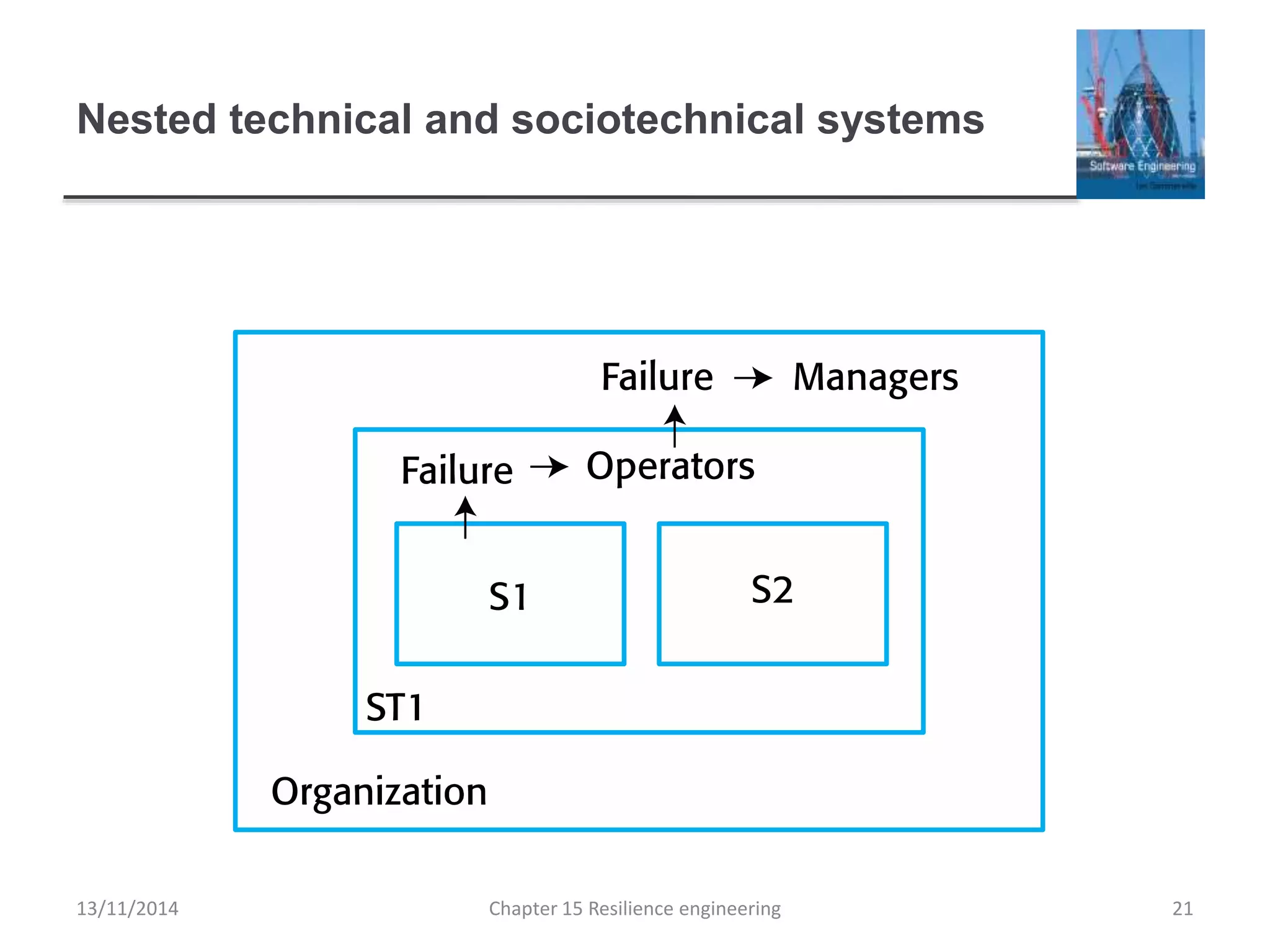
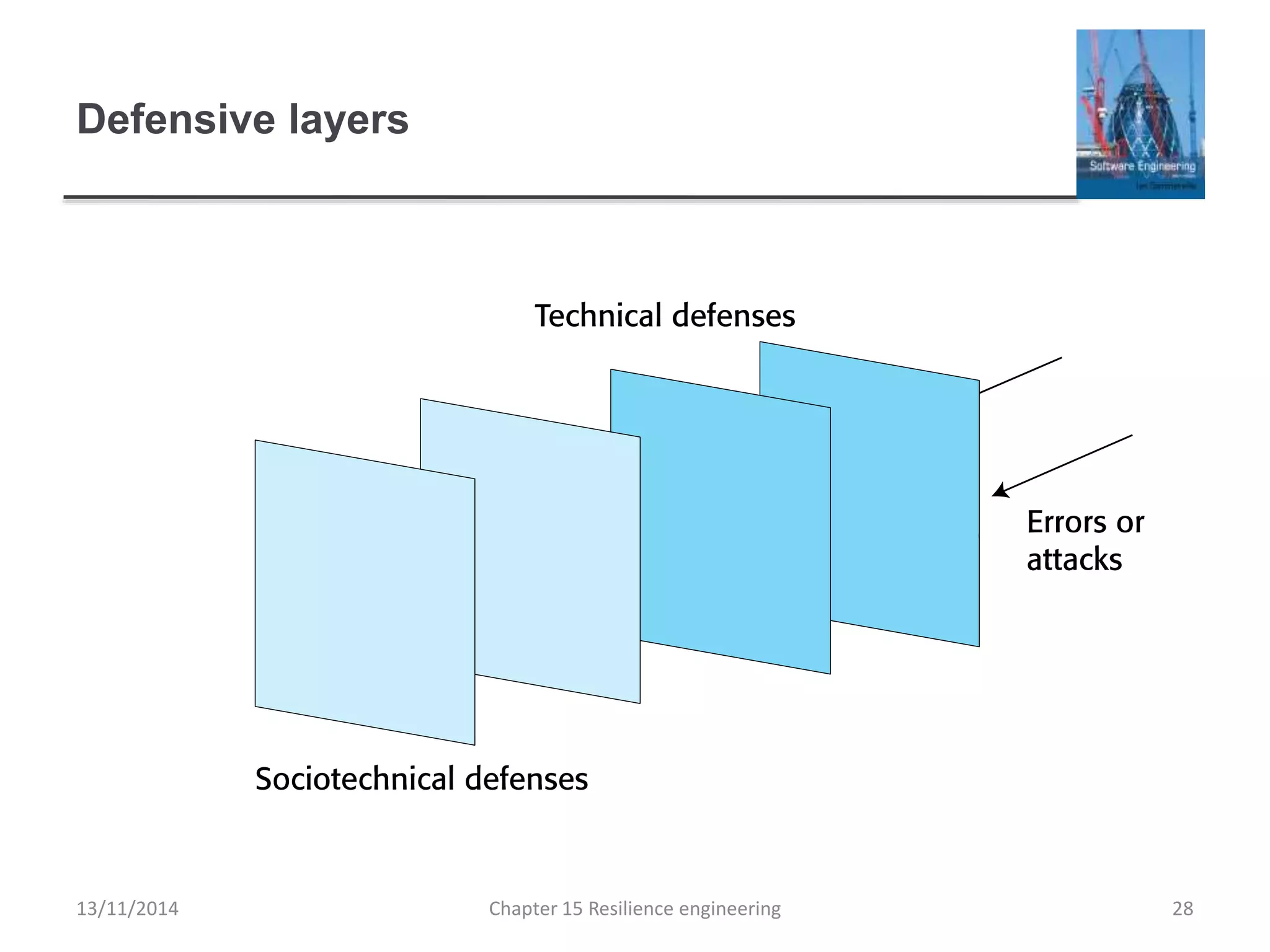
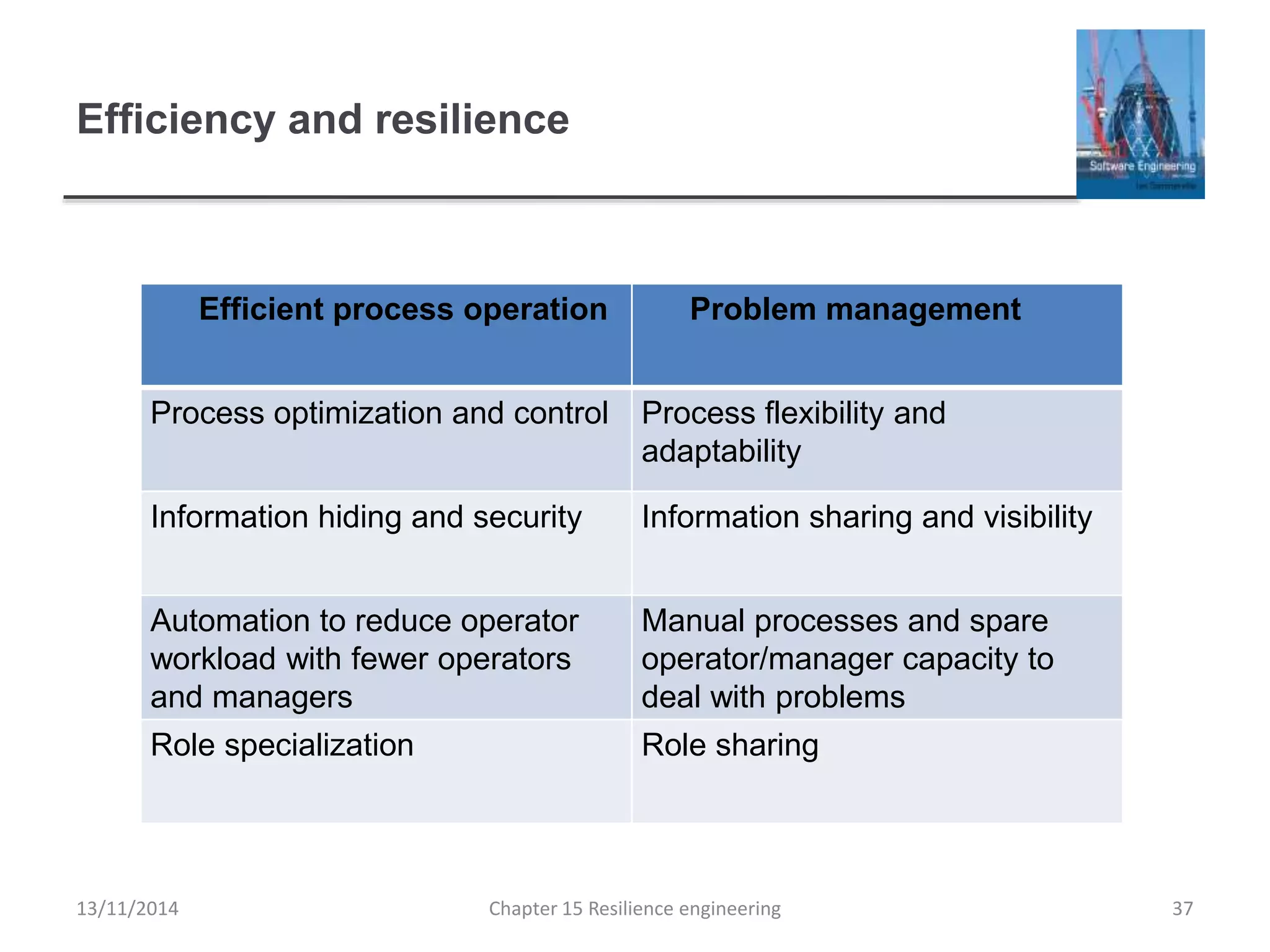
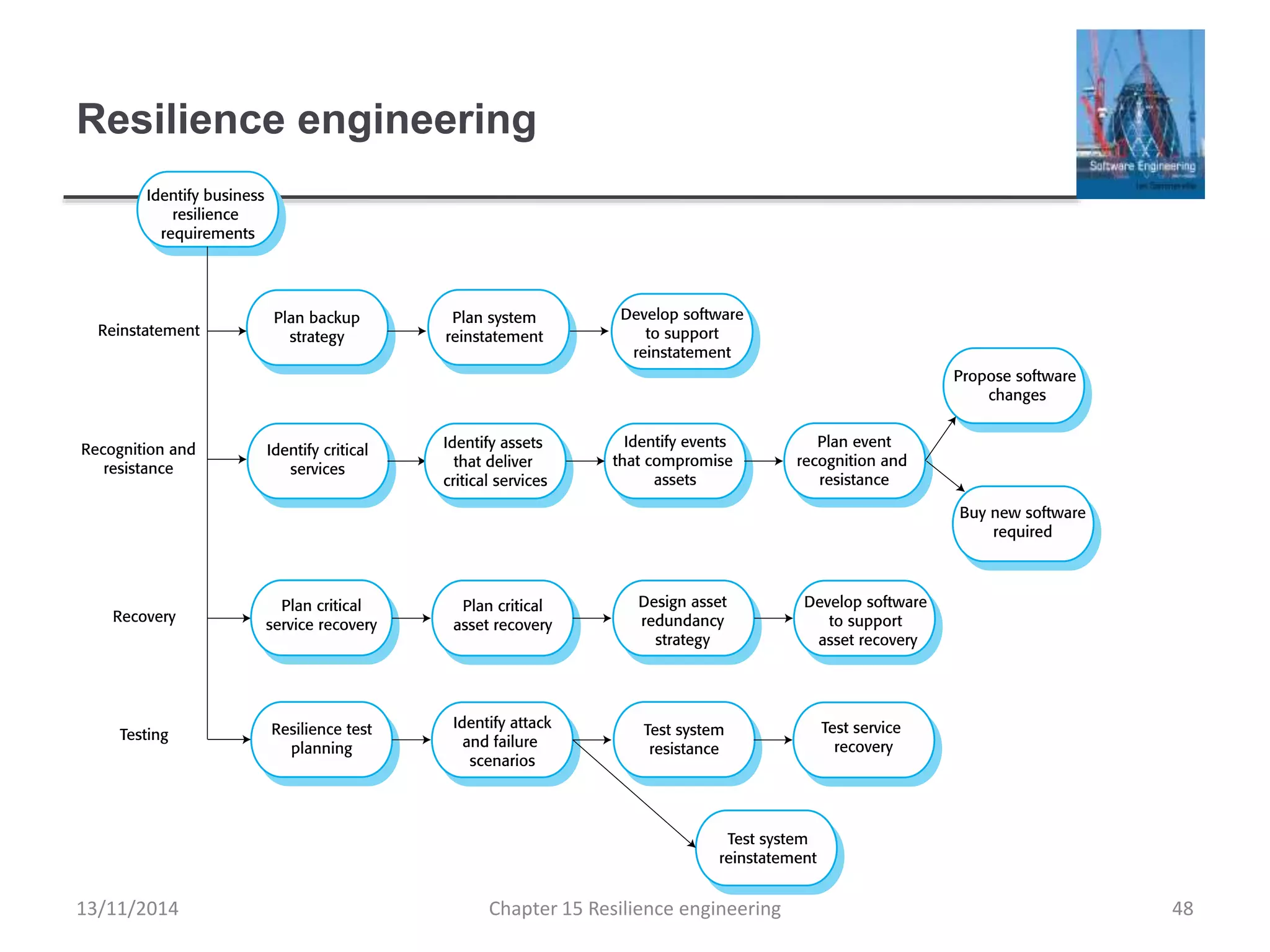
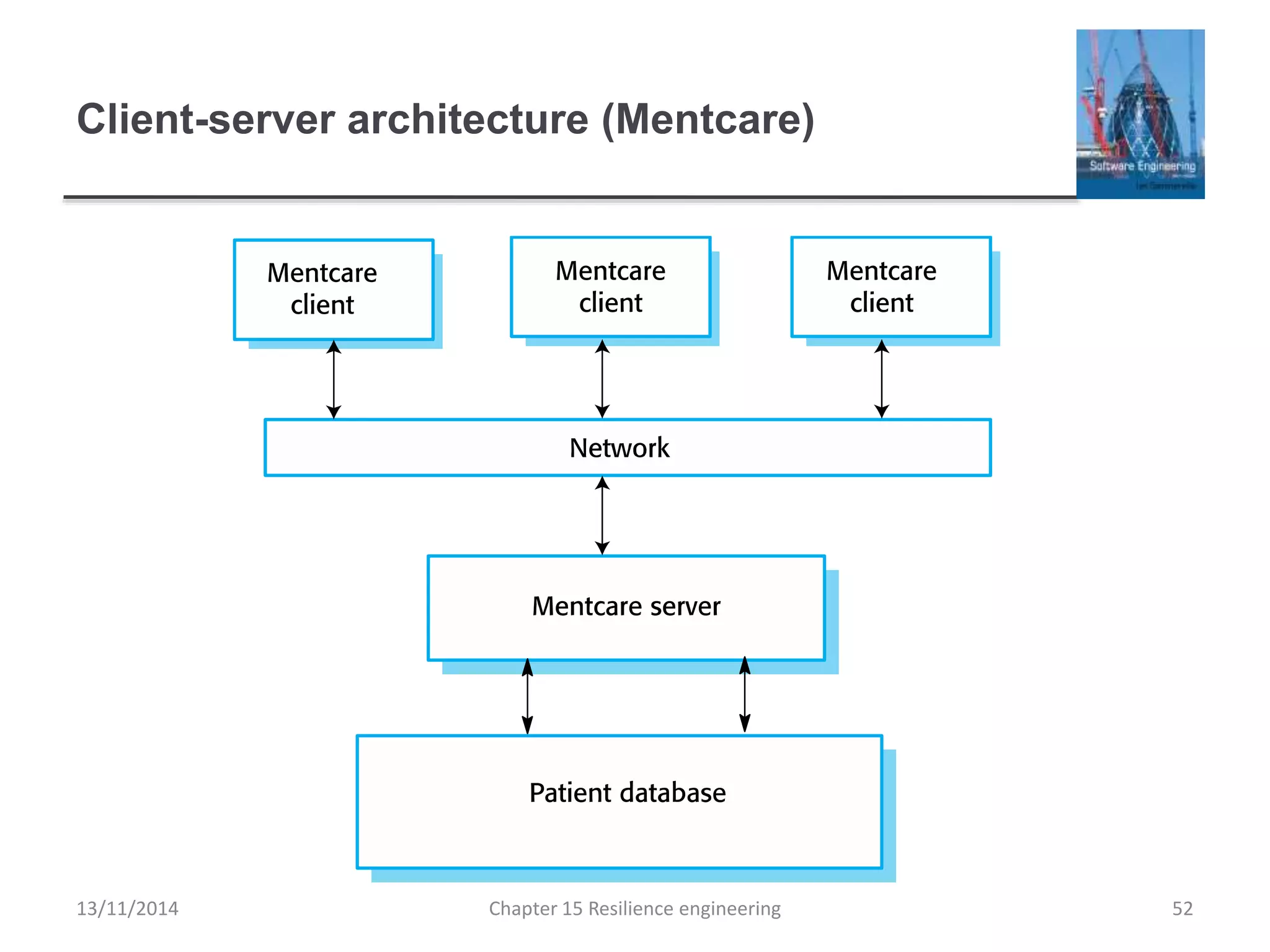
This document summarizes key concepts from Chapter 15 on resilience engineering. It discusses resilience as the ability of systems to maintain critical services during disruptions like failures or cyberattacks. Resilience involves recognizing issues, resisting failures when possible, and recovering quickly through activities like redundancy. The document also covers sociotechnical resilience, where human and organizational factors are considered, and characteristics of resilient organizations like responsiveness, monitoring, anticipation, and learning.