Downloaded 114 times

















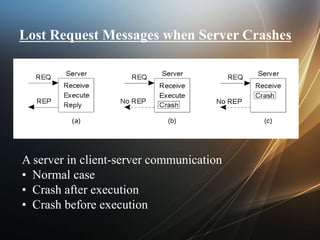




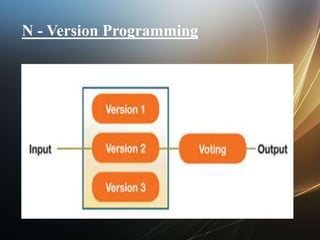
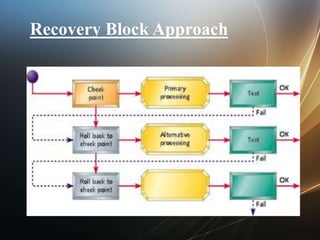







The document discusses faults, errors, and failures in systems. A fault is a defect, an error is unexpected behavior, and a failure occurs when specifications are not met. Fault tolerance allows a system to continue operating despite errors. Fault tolerant systems are gracefully degradable and aim to ensure small failure probabilities. Faults can be hardware or software issues. Various failure types and objectives of fault tolerance like availability and reliability are also described.









































































