Downloaded 65 times



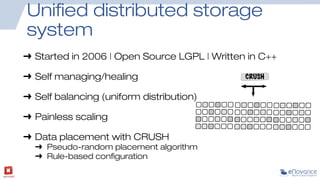
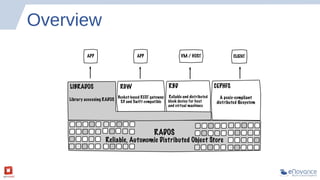

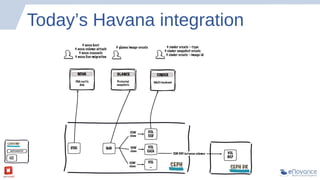


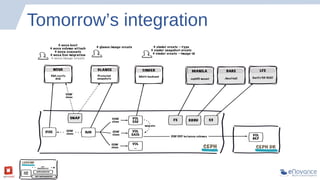
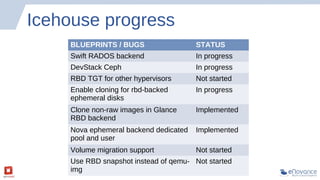




The document summarizes a presentation about Ceph storage and its integration with OpenStack. It discusses: - Ceph is an open source distributed storage system that is self-managing, self-healing, and scales easily. It uses a pseudo-random placement algorithm called CRUSH to distribute data. - Ceph has become the de facto storage backend for OpenStack. The presentation discusses the current status of Ceph integration in OpenStack Havana and upcoming improvements planned for Icehouse. - Future releases like Firefly will add new features to Ceph like tiering, erasure coding, ZFS support, and multi-backend filestore capabilities.





























































































