Download to read offline


















![bought to you by
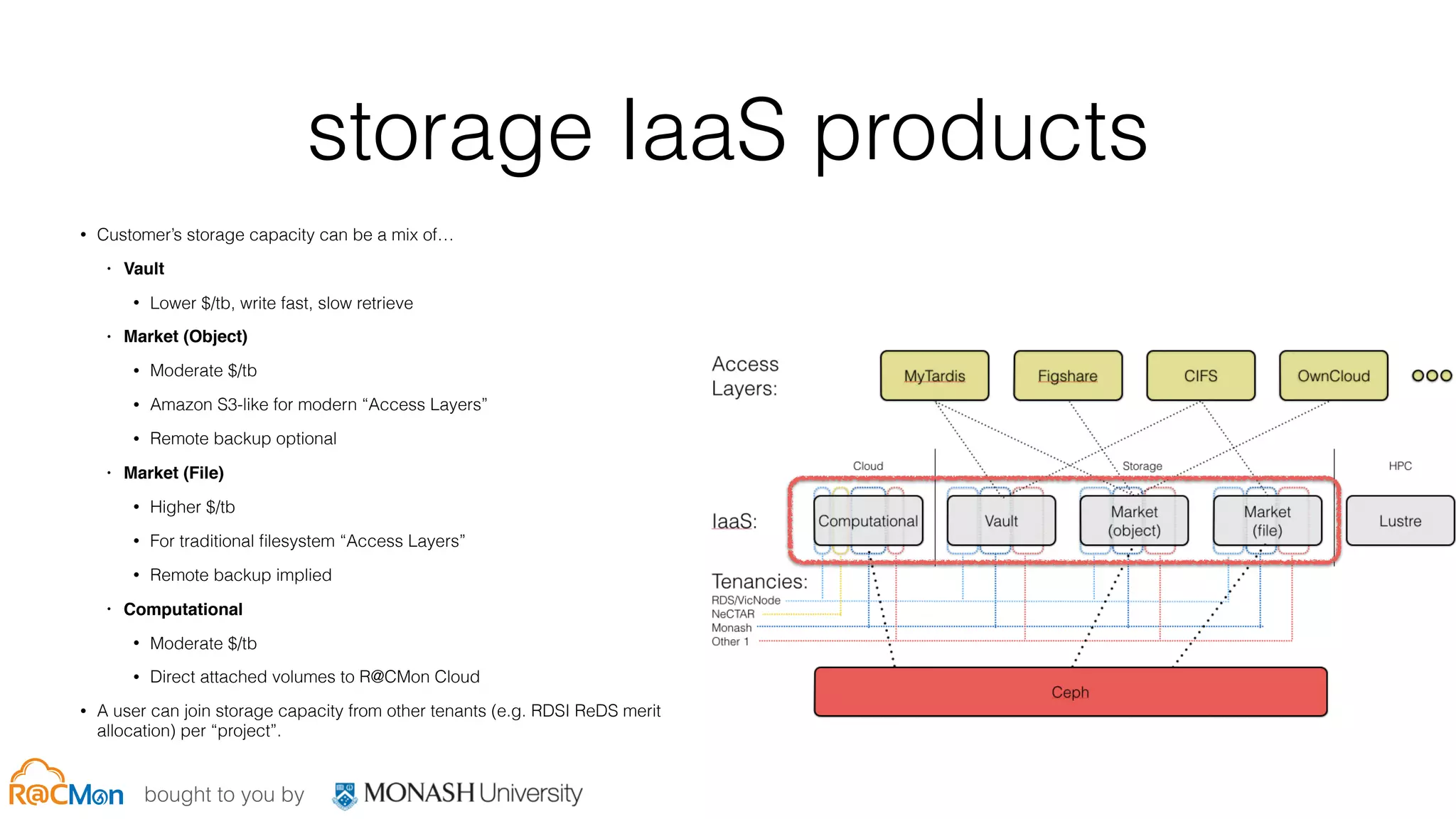
show and tell: rds[i]
• 3x Dell R320 (mons)
• 4x Dell R720xd (cache tier) - 18TB/node
• 20x 900GB 10k SAS (20x RAID0, PERC 710p) - rgw
hot tier
• 4x 400GB Intel DC S3700 SSDs (journals for rgw hot
tier)
• 2x E5-2630v2 (2.6GHz), 128GB RAM
• 56GbE (Mellanox CX-3 DP), VLANs for back/front-end](https://image.slidesharecdn.com/05-rcmon-cephdaymelbourne2015copy-151109170048-lva1-app6891/75/Ceph-Day-Melbourne-Scale-and-performance-Servicing-the-Fabric-and-the-Workshop-22-2048.jpg)
![bought to you by
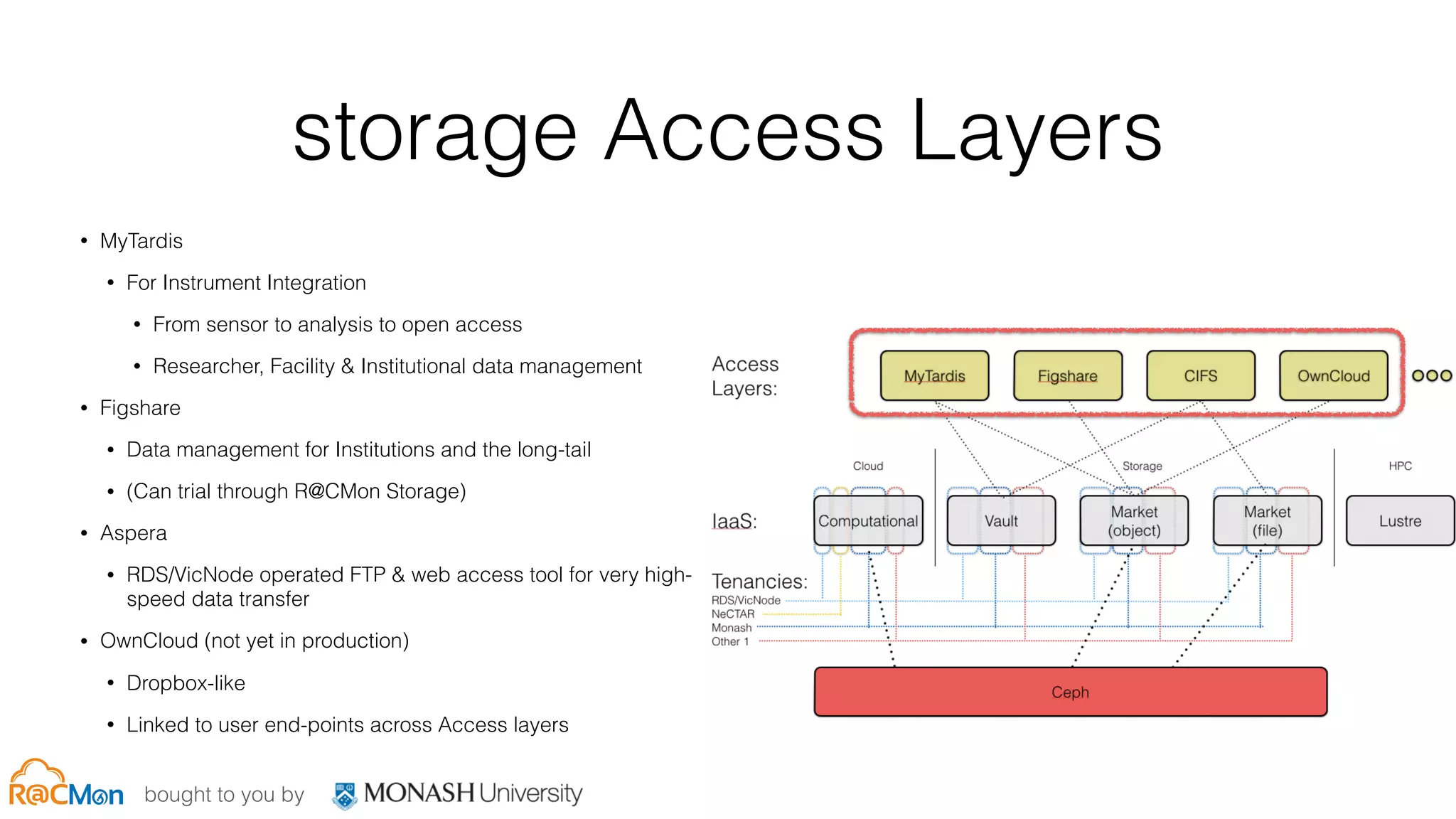
show and tell: rds[i]
• 33x Dell R720xd + 66 MD1200 (2 per node) -144TB/node
• 8x 6TB 7.2k NL-SAS (8x RAID0, PERC H710p) - rgw EC cold
tier
• 24x 4TB 7.2k NL-SAS (24x RAID0, PERC H810) - rbds go
here
• 4x 200GB Intel DC S3700 SSDs (journals for rbd pool)
• 2x E5-2630v2 (2.6GHz), 128GB RAM
• 20GbE (Mellanox CX-3 DP), VLANs for back/front-end
• Ceph Hammer on RHEL Maipo](https://image.slidesharecdn.com/05-rcmon-cephdaymelbourne2015copy-151109170048-lva1-app6891/75/Ceph-Day-Melbourne-Scale-and-performance-Servicing-the-Fabric-and-the-Workshop-23-2048.jpg)
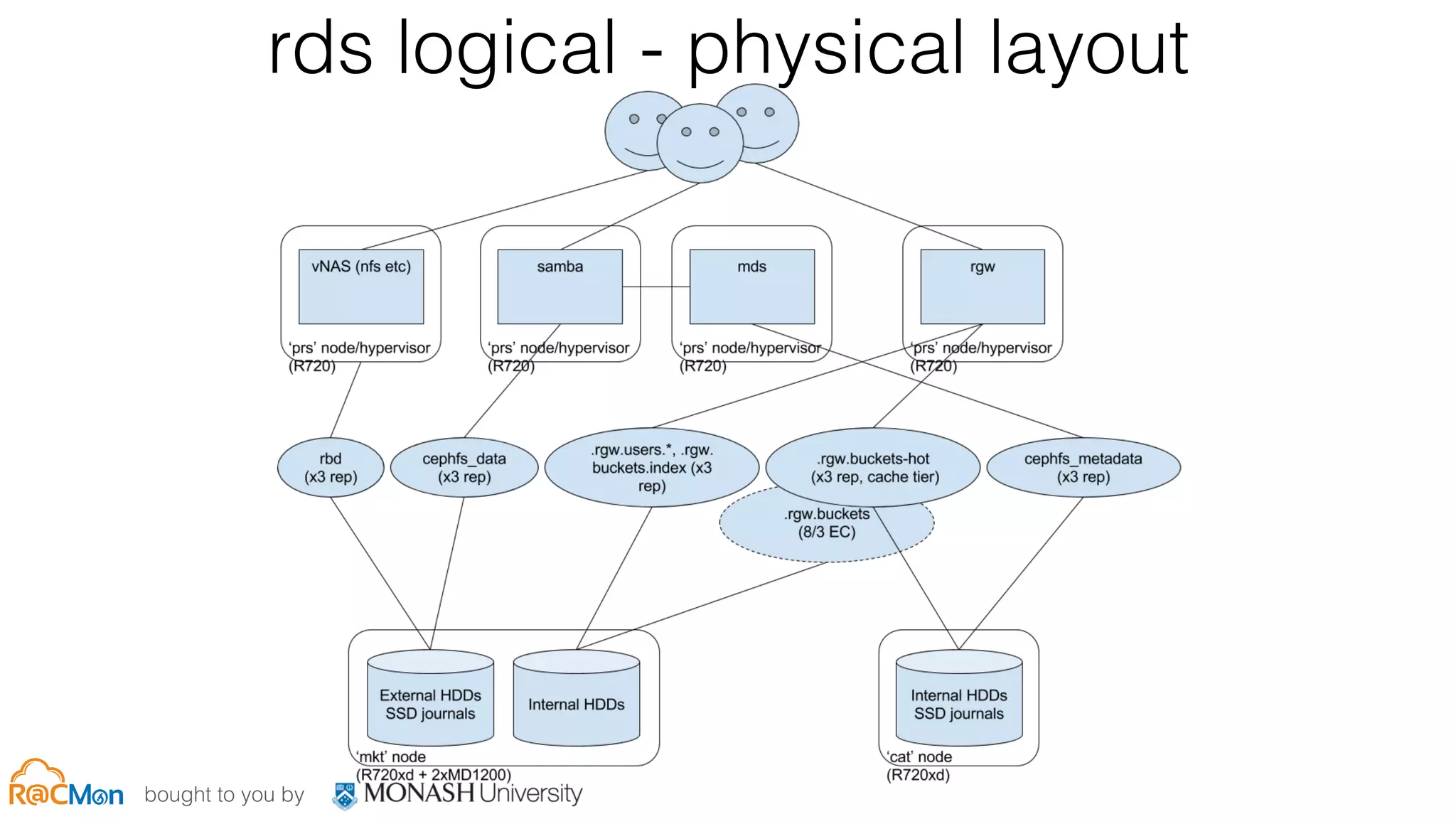
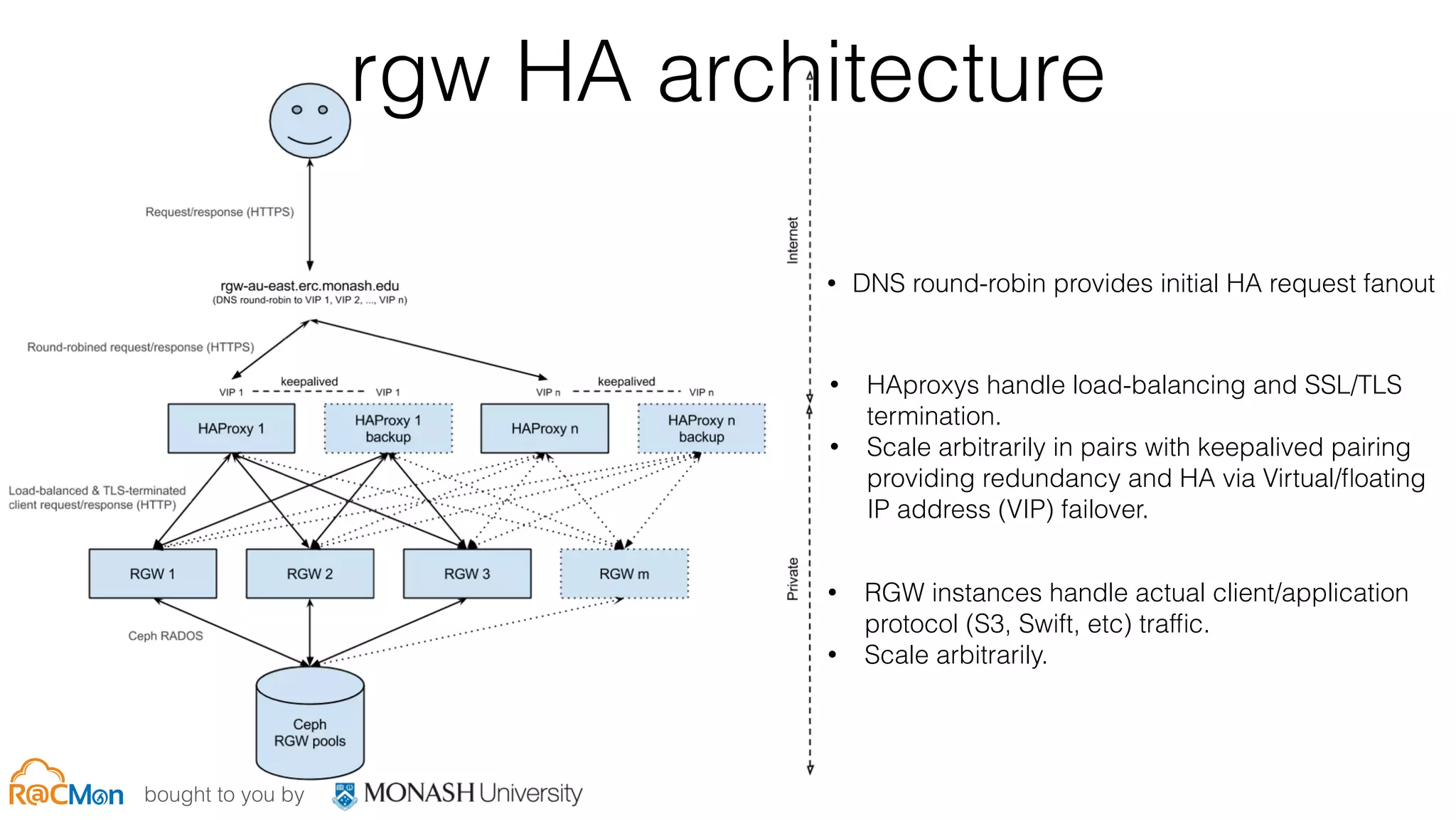





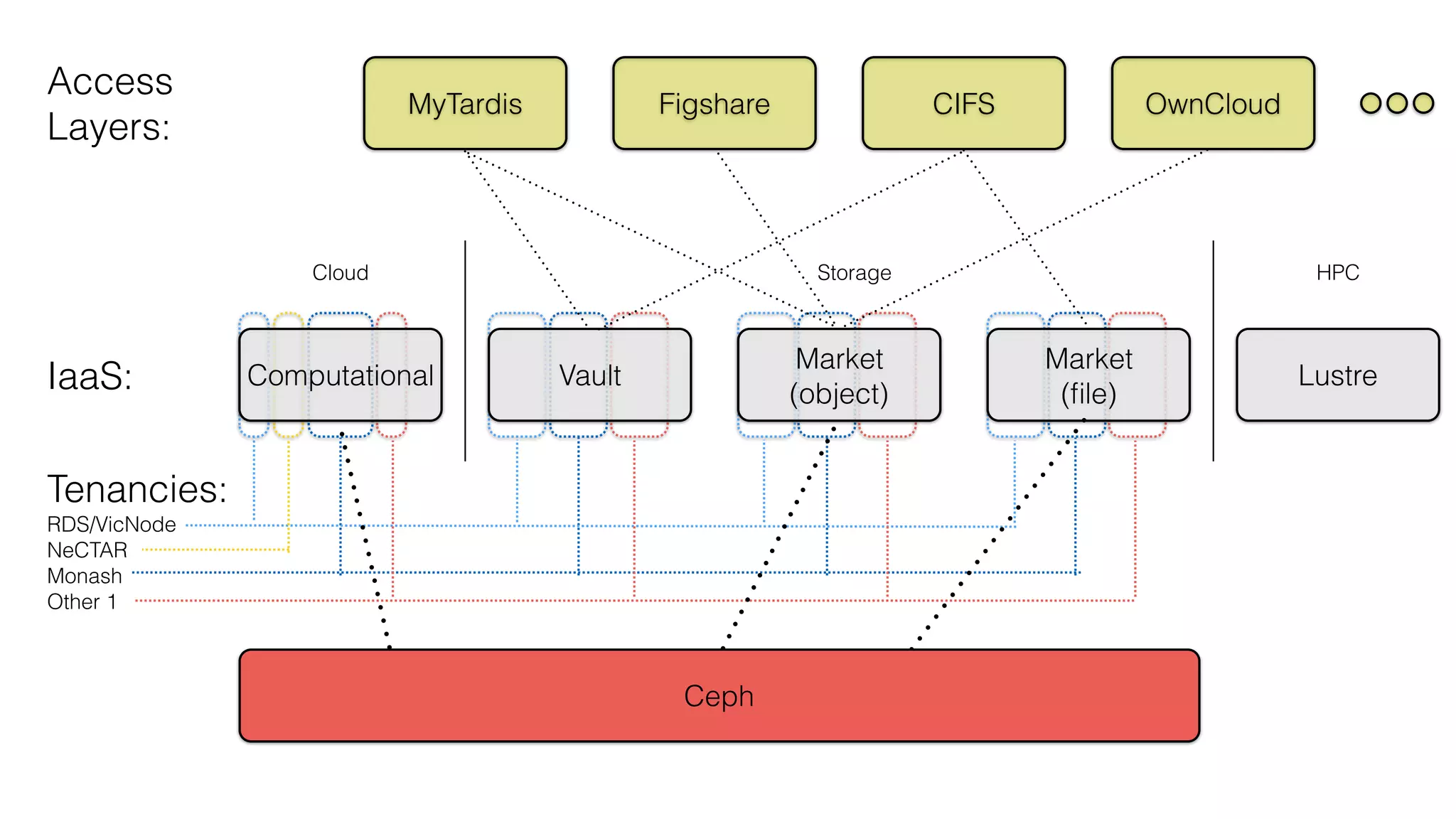

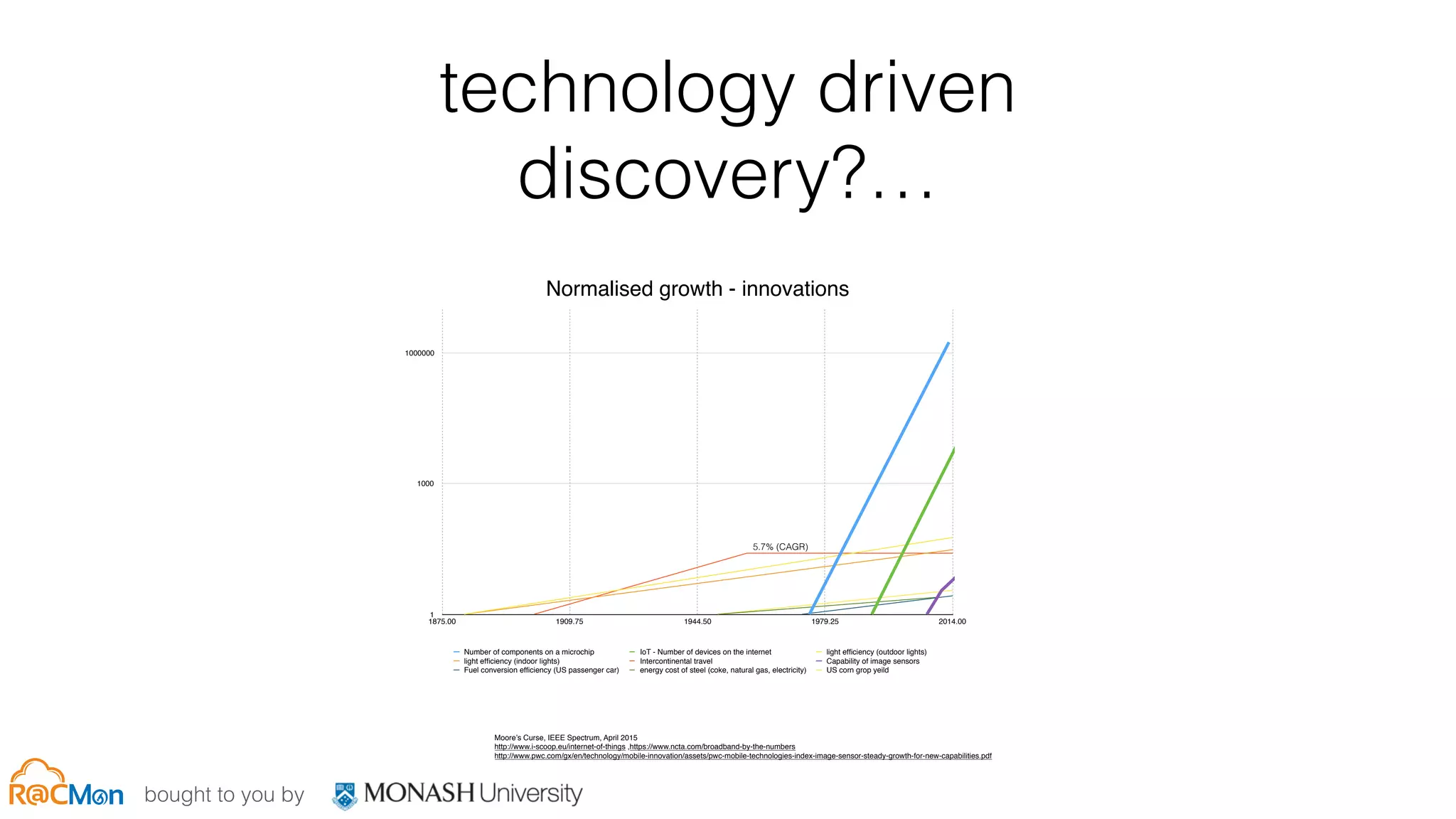
The document discusses scale and performance challenges in providing storage infrastructure for research computing. It describes Monash University's implementation of the Ceph distributed storage system across multiple clusters to provide a "fabric" for researchers' storage needs in a flexible, scalable way. Key points include: - Ceph provides software-defined storage that is scalable and can integrate with other systems like OpenStack. - Multiple Ceph clusters have been implemented at Monash of varying sizes and purposes, including dedicated clusters for research data storage. - The infrastructure provides different "tiers" of storage with varying performance and cost characteristics to meet different research needs. - Ongoing work involves expanding capacity and upgrading hardware to improve performance










































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












