Downloaded 87 times










![Ceph with CloudStack
ROTATIONAL=$(cat /sys/block/$DEV/queue/rotational)
if [ $ROTATIONAL -eq 1 ]; then
echo "root=hdd rack=${RACK}-hdd host=${HOST}-hdd"
else
echo "root=ssd rack=${RACK}-ssd host=${HOST}-ssd"
fi
● If we detect the OSD is running on a SSD it goes into
a different 'host' in the CRUSH Map
– Rack is encoded in hostname (dc2-rk01)
-48 2.88 rack rk01-ssd
-33 0.72 host dc2-rk01-osd01-ssd
252 0.36 osd.252 up 1
253 0.36 osd.253 up 1
-41 69.16 rack rk01-hdd
-10 17.29 host dc2-rk01-osd01-hdd
20 0.91 osd.20 up 1
19 0.91 osd.19 up 1
17 0.91 osd.17 up 1](https://image.slidesharecdn.com/deployingcephinthewild-141028171447-conversion-gate02/85/Ceph-Day-London-2014-Deploying-ceph-in-the-wild-11-320.jpg)
![Ceph with CloudStack
● Download the script on my Github page:
– Url: https://gist.github.com/wido
– Place it in /usr/local/bin
● Configure it in your ceph.conf
– Push the config to your nodes using Puppet, Chef,
Ansible, ceph-deploy, etc
[osd]
osd_crush_location_hook = /usr/local/bin/crush-location-looukp](https://image.slidesharecdn.com/deployingcephinthewild-141028171447-conversion-gate02/85/Ceph-Day-London-2014-Deploying-ceph-in-the-wild-12-320.jpg)



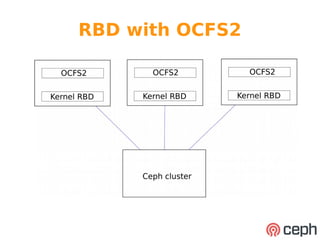











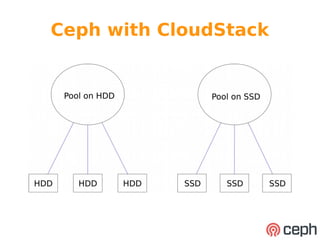
The document discusses Wido den Hollander's experience deploying Ceph storage clusters in various organizations. It describes two example deployments: one using Ceph block storage with CloudStack for 1000 VMs and S3 object storage, using SSDs and HDDs optimized for IOPS; the other using Ceph block storage with OCFS2 shared filesystem between web servers, using all SSDs and 10GbE networking for low latency. The document emphasizes designing for high IOPS rather than just capacity, and discusses best practices like regular hardware updates and testing recovery scenarios.



































































