






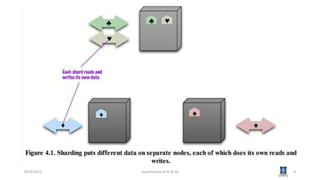


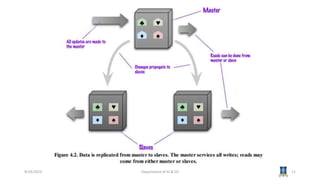


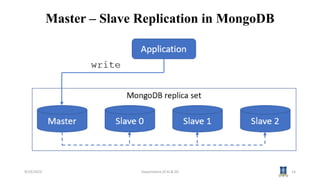

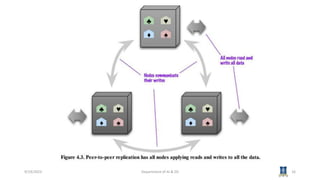



This document discusses topics related to NoSQL data management and distribution models in big data analytics. It covers key-value and document data models, as well as graph databases and schema-less databases. It then describes several distribution models including single server, sharding, master-slave replication, peer-to-peer replication, and combining sharding and replication. Specific examples of these models in MongoDB and Cassandra are provided. The next session will cover Cassandra's data model.






















































































